HashMap与ConcurrentHashMap的区别
2015-07-17 10:48
483 查看
从JDK1.2起,就有了HashMap,正如前一篇文章所说,HashMap不是线程安全的,因此多线程操作时需要格外小心。
在JDK1.5中,伟大的Doug Lea给我们带来了concurrent包,从此Map也有安全的了。
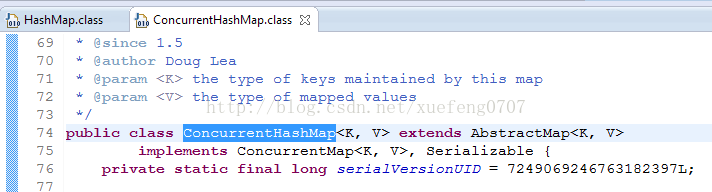
ConcurrentHashMap具体是怎么实现线程安全的呢,肯定不可能是每个方法加synchronized,那样就变成了HashTable。
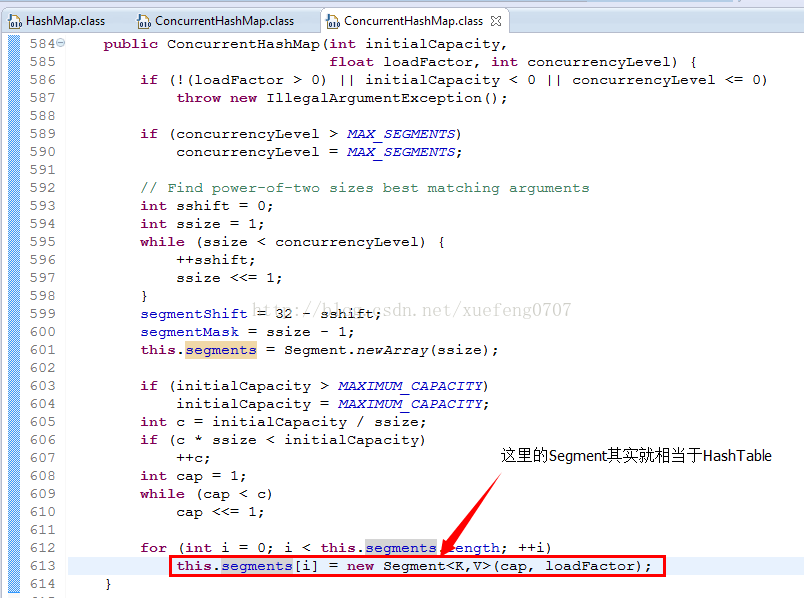
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
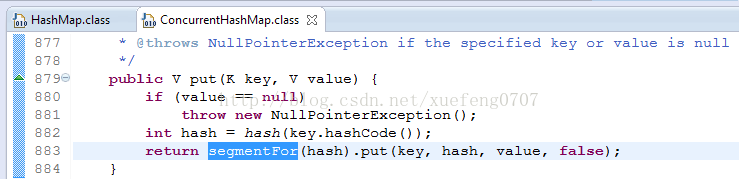
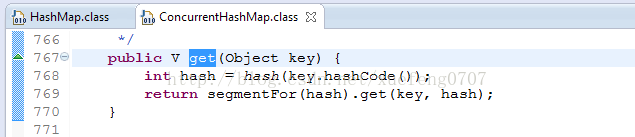
在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中:
测试程序:
[java] view
plaincopy


import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapTest {
private static ConcurrentHashMap<Integer, Integer> map = new ConcurrentHashMap<Integer, Integer>();
public static void main(String[] args) {
new Thread("Thread1"){
@Override
public void run() {
map.put(3, 33);
}
};
new Thread("Thread2"){
@Override
public void run() {
map.put(4, 44);
}
};
new Thread("Thread3"){
@Override
public void run() {
map.put(7, 77);
}
};
System.out.println(map);
}
}
ConcurrentHashMap中默认是把segments初始化为长度为16的数组。
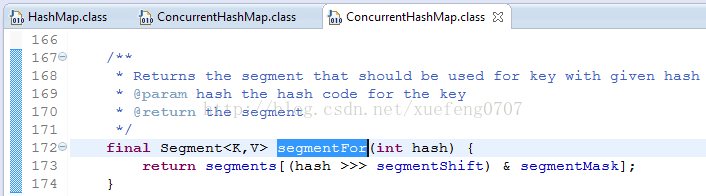
根据ConcurrentHashMap.segmentFor的算法,3、4对应的Segment都是segments[1],7对应的Segment是segments[12]。
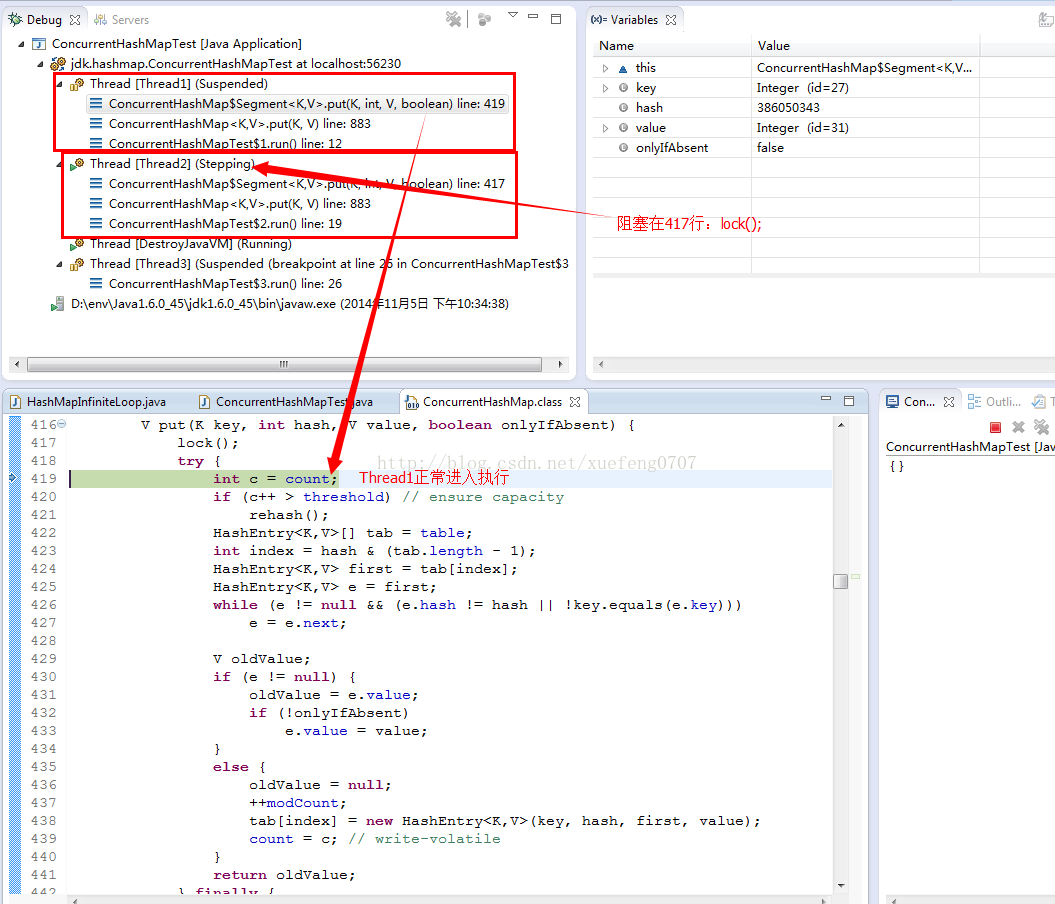
(1)Thread1和Thread2先后进入Segment.put方法时,Thread1会首先获取到锁,可以进入,而Thread2则会阻塞在锁上:
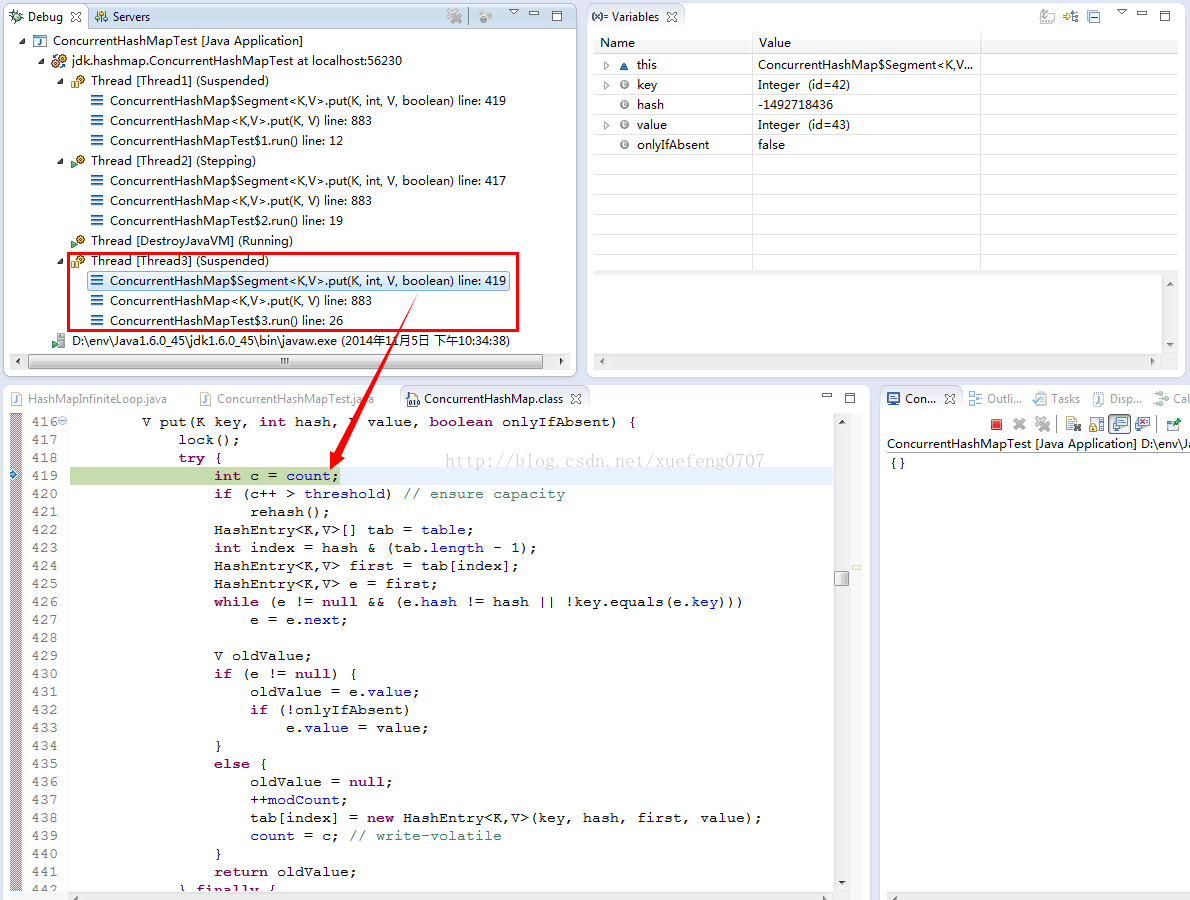
(2)切换到Thread3,也走到Segment.put方法,因为7所存储的Segment和3、4不同,因此,不会阻塞在lock():
以上就是ConcurrentHashMap的工作机制,通过把整个Map分为N个Segment(类似HashTable),可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。
在JDK1.5中,伟大的Doug Lea给我们带来了concurrent包,从此Map也有安全的了。
ConcurrentHashMap具体是怎么实现线程安全的呢,肯定不可能是每个方法加synchronized,那样就变成了HashTable。
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中:
测试程序:
[java] view
plaincopy
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapTest {
private static ConcurrentHashMap<Integer, Integer> map = new ConcurrentHashMap<Integer, Integer>();
public static void main(String[] args) {
new Thread("Thread1"){
@Override
public void run() {
map.put(3, 33);
}
};
new Thread("Thread2"){
@Override
public void run() {
map.put(4, 44);
}
};
new Thread("Thread3"){
@Override
public void run() {
map.put(7, 77);
}
};
System.out.println(map);
}
}
ConcurrentHashMap中默认是把segments初始化为长度为16的数组。
根据ConcurrentHashMap.segmentFor的算法,3、4对应的Segment都是segments[1],7对应的Segment是segments[12]。
(1)Thread1和Thread2先后进入Segment.put方法时,Thread1会首先获取到锁,可以进入,而Thread2则会阻塞在锁上:
(2)切换到Thread3,也走到Segment.put方法,因为7所存储的Segment和3、4不同,因此,不会阻塞在lock():
以上就是ConcurrentHashMap的工作机制,通过把整个Map分为N个Segment(类似HashTable),可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。

相关文章推荐
- 基于spring3.0的采用注解配置的spring MVC项目
- Oracle 查看表空间的大小及使用情况sql语句
- PostgreSQL基础整理(三)
- IE浏览器CTRL+F5无法重新请求
- ulimit -n 修改
- 第5章分布式系统模式 在 .NET 中使用 DataSet 实现 Data Transfer Object
- R fitting R语言数据拟合总结
- 图解TCP-IP协议
- 串口通信中整型和浮点型数据的处理和发送
- android系统重启设备
- 云之讯融合通讯开放平台_提供融合语音,短信,VoIP,视频和IM等通讯API及SDK。
- JavaScript用select实现日期控件
- my97的WdatePicker插件使用
- jsp页面中日期类型回显格式设置
- CSS中绝对定位对子元素height的影响
- 【工作日志】【asp】【04】asp for each详解
- 黑马程序员---ios学习日志 10
- 第5章分布式系统模式 在 .NET 中使用 DataSet 实现 Data Transfer Object
- Netty与java Socket通信不太好使
- yum快速升级