360方案 技术解决方案
2015-07-16 11:38
253 查看
之前有做过一个360的个性化推荐排序与点击率预估方案。很遗憾,方案最终落选于一堆清华北大的队伍中。记得当时评估人(一个很资深的大牛)问我:如果把用户分组了,不是会抹杀掉用户的一些特征吗?我当时完全答不上来。现在想想,还真是不需要分用户组,直接根据所有用户投票的结果选择就可以了。
但是能够在一周内快速的做出一个方案来,这段黑暗的岁月还是值得铭记在心的。下面,就把这个方案分享一下:
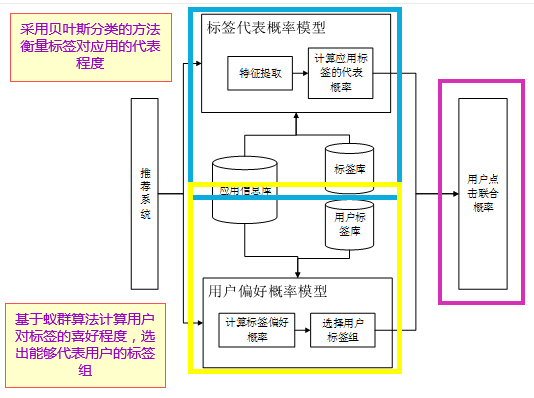
点击率预估现在普遍应用在广告投放中,因为直接与用户和利益相关,是各个企业非常重视的一部分。
但是,用户的点击是具有很大随机性的,因此,为了能够为用户提供更好的推荐结果,并且考虑到用户点击的随机性,我们提出了基于蚁群算法的点击率预估模型。此模型主要采用针对用户行为随机性的概率模型,通过实现用户对一组物品兴趣的动态更新来进行点击率预估。
整个模型分为标签代表概率模型和用户偏好概率模型。前者主要是为了选取最能够代表应用的标签,后者则主要选出最能够代表用户偏好的标签。所以,一切都是基于标签库的。
在标签代表概率模型中,我们针对一个应用可能会有多个标签的问题,遍历标签库中所有的标签,利用贝叶斯分类计算每个标签能够体现该应用特征的代表概率。概率值越大,则该标签越能代表该应用的特征。
而用户偏好概率模型则是基于基于蚁群算法的,通过计算每个标签被用户的喜好程度来选出最能代表用户兴趣的标签组。
通过上述两个步骤的构建,我们对于每一个包含很多标签的应用,计算用户点击的联合概率,以此来对用户的点击率进行预估。
下面说一下蚁群算法吧。
蚁群算法的大概过程如下:蚂蚁在寻找食物的过程中每一只蚂蚁都会在它走过的路上留下信息素,而蚂蚁倾向于选择具有较浓信息素的路径,因此,若某条路径较优,被蚂蚁选择的较多时,其遗留的信息素浓度就越大,从而被选中的可能性就更大。类比到点击率预估系统中,用户可以认为是蚂蚁,用户之前的选择不同类别的物品为道路,用户的每一次选择认为是蚂蚁走过的道路,并留下了相应的信息素。而待推荐的物品即为目标,通过点击模型来计算用户选择该目标的概率值,从而进行点击率预估。
当用户执行完一次选择时,需要用更新函数进行信息素更新,即更新概率函数,从而实现对用户兴趣变化的快速反应。为了能够体现个性化所以需要为每一个用户构建他们的点击模型,对于每个用户的点击模型涉及到训练和更新。不同用户的更新函数可以一致,但是因为选择的不同,对于不同的用户概率模型会有一定的差异。
另外,为了克服冷启动的问题,对于没有历史记录的用户,利用Item的流行度情况进行推荐,当用户存在历史记录时,构建基于蚁群的点击率预估模型,来实现点击率预估。
举一个例子吧:
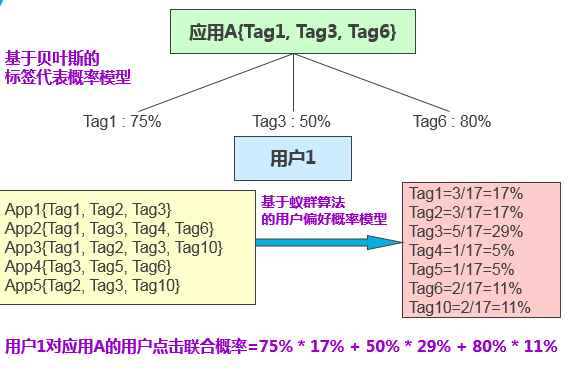
我们假设一个具有三个标签的应用A,首先使用基于贝叶斯的标签代表概率模型计算每个标签的代表概率,分别为75%,50%和80%。之后我们从用户标签库中取出所有用户之前下载的应用,连同该应用的所有标签,并利用用户偏好概率模型进行计算。为了便于理解,我们选取最为简单的偏好概率函数,即以标签出现次数的概率作为偏好概率。最后,我们将标签的代表概率与偏好概率进行联乘,并将所有标签算出的值进行连加,即可得到用户1对应用A的用户点击联合概率,可以此作为点击率预估的标准。
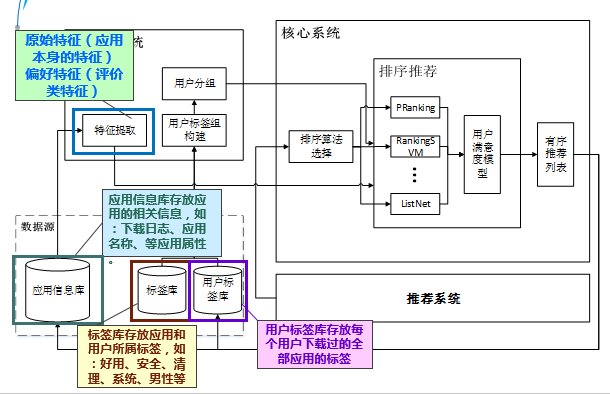
如图,就是推荐排序模型的架构图。
系统主要分为以下几个部分:数据源、预处理系统、推荐系统和核心系统,其中数据源主要实现对系统所需数据的存储和管理,预处理系统主要完成用户和应用特征的提取以及用户分组兴趣的构建。核心系统包括基于随即森林的排序算法选择模块和基于多算法和用户满意度模型的排序推荐。在我们对360手机助手现有业务的分析中,发现360已有一套较为完整的推荐系统,因此,我们直接将次推荐系统作为系统的一部分。
标签库中存放应用和用户所属标签,如:好用、安全、清理、系统、男性等。
用户标签库存放每个用户下载过的全部应用的标签。
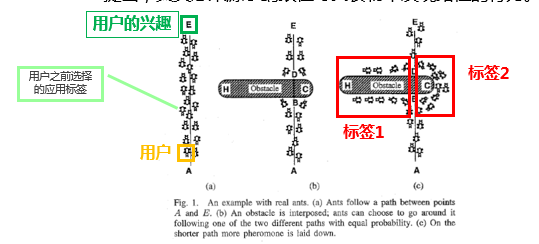
用户可以认为是蚂蚁,而用户的兴趣即为目标,用户下载过的应用标签为道路,并留下了相应的信息素。我们的模型就通过计算用户选择该目标的概率值来选择出用户感兴趣的标签组,该标签组作为用户兴趣的描述。
当用户执行完一次选择时,需要将本次用户下载的应用的标签加入用户自身的标签库中,并用更新函数进行信息素更新,即更新概率函数,从而实现对用户兴趣变化的快速反应。
模型的构建分为以下三步:

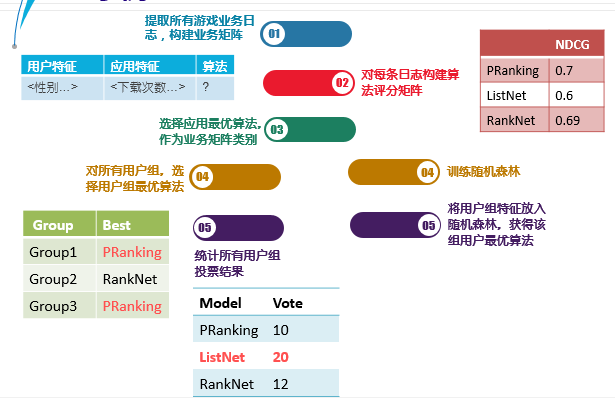
下面我们通过一个简单的示例来介绍我们基于随机森林的排序算法选择模型,我们以游戏业务为例进行说明。首先,我们提取所有游戏业务日志,构建业务矩阵,包括用户特征、应用特征以及最优算法。之后,我们对每一条日志利用NDCG对不同的算法进行评价,并根据NDCG的大小选择应用最优算法,填入业务矩阵的算法中。对于老用户,我们用上述训练集训练一棵随机森林,当要对老用户进行推荐排序时,我们将用户的特征放入随机森林中,获取用户最优算法。对于新用户,由于其没有历史数据,我们用业务相关的所有用户投票结果作为该用户的最优算法。
但是能够在一周内快速的做出一个方案来,这段黑暗的岁月还是值得铭记在心的。下面,就把这个方案分享一下:
点击率预估
点击率预估现在普遍应用在广告投放中,因为直接与用户和利益相关,是各个企业非常重视的一部分。
但是,用户的点击是具有很大随机性的,因此,为了能够为用户提供更好的推荐结果,并且考虑到用户点击的随机性,我们提出了基于蚁群算法的点击率预估模型。此模型主要采用针对用户行为随机性的概率模型,通过实现用户对一组物品兴趣的动态更新来进行点击率预估。
整个模型分为标签代表概率模型和用户偏好概率模型。前者主要是为了选取最能够代表应用的标签,后者则主要选出最能够代表用户偏好的标签。所以,一切都是基于标签库的。
在标签代表概率模型中,我们针对一个应用可能会有多个标签的问题,遍历标签库中所有的标签,利用贝叶斯分类计算每个标签能够体现该应用特征的代表概率。概率值越大,则该标签越能代表该应用的特征。
而用户偏好概率模型则是基于基于蚁群算法的,通过计算每个标签被用户的喜好程度来选出最能代表用户兴趣的标签组。
通过上述两个步骤的构建,我们对于每一个包含很多标签的应用,计算用户点击的联合概率,以此来对用户的点击率进行预估。
下面说一下蚁群算法吧。
蚁群算法的大概过程如下:蚂蚁在寻找食物的过程中每一只蚂蚁都会在它走过的路上留下信息素,而蚂蚁倾向于选择具有较浓信息素的路径,因此,若某条路径较优,被蚂蚁选择的较多时,其遗留的信息素浓度就越大,从而被选中的可能性就更大。类比到点击率预估系统中,用户可以认为是蚂蚁,用户之前的选择不同类别的物品为道路,用户的每一次选择认为是蚂蚁走过的道路,并留下了相应的信息素。而待推荐的物品即为目标,通过点击模型来计算用户选择该目标的概率值,从而进行点击率预估。
当用户执行完一次选择时,需要用更新函数进行信息素更新,即更新概率函数,从而实现对用户兴趣变化的快速反应。为了能够体现个性化所以需要为每一个用户构建他们的点击模型,对于每个用户的点击模型涉及到训练和更新。不同用户的更新函数可以一致,但是因为选择的不同,对于不同的用户概率模型会有一定的差异。
另外,为了克服冷启动的问题,对于没有历史记录的用户,利用Item的流行度情况进行推荐,当用户存在历史记录时,构建基于蚁群的点击率预估模型,来实现点击率预估。
举一个例子吧:
我们假设一个具有三个标签的应用A,首先使用基于贝叶斯的标签代表概率模型计算每个标签的代表概率,分别为75%,50%和80%。之后我们从用户标签库中取出所有用户之前下载的应用,连同该应用的所有标签,并利用用户偏好概率模型进行计算。为了便于理解,我们选取最为简单的偏好概率函数,即以标签出现次数的概率作为偏好概率。最后,我们将标签的代表概率与偏好概率进行联乘,并将所有标签算出的值进行连加,即可得到用户1对应用A的用户点击联合概率,可以此作为点击率预估的标准。
个性化推荐排序模型
如图,就是推荐排序模型的架构图。
系统主要分为以下几个部分:数据源、预处理系统、推荐系统和核心系统,其中数据源主要实现对系统所需数据的存储和管理,预处理系统主要完成用户和应用特征的提取以及用户分组兴趣的构建。核心系统包括基于随即森林的排序算法选择模块和基于多算法和用户满意度模型的排序推荐。在我们对360手机助手现有业务的分析中,发现360已有一套较为完整的推荐系统,因此,我们直接将次推荐系统作为系统的一部分。
数据源
应用信息库存放应用的相关信息,如:下载日志、应用名称、应用类别等应用自身属性。标签库中存放应用和用户所属标签,如:好用、安全、清理、系统、男性等。
用户标签库存放每个用户下载过的全部应用的标签。
预处理
特征提取:结合360手机助手已有业务,对从两个方面进行特征提取:原始特征和偏好特征。原始特征包含软件开发作者、支持语言、支持系统、安装包大小等应用本身的特征;偏好特征包括评分、评价数(好评数、中评数、差评数)、下载量、是否免费、有无广告、是否参与绿剑行动、是否获得蒲公英奖、是否具有360软件特权等特征内容。核心系统
| 目标 | 解决方案 |
|---|---|
| 用户兴趣建模 | 基于蚁群的偏好概率模型 |
| 用户兴趣小组 | 基于Kmeans聚类的用户分组模型 |
| 用户个性化排序算法 | 基于随机森林的排序算法选择模型 |
| 用户满意度评估 | 基于贝叶斯分布的用户满意度模型 |
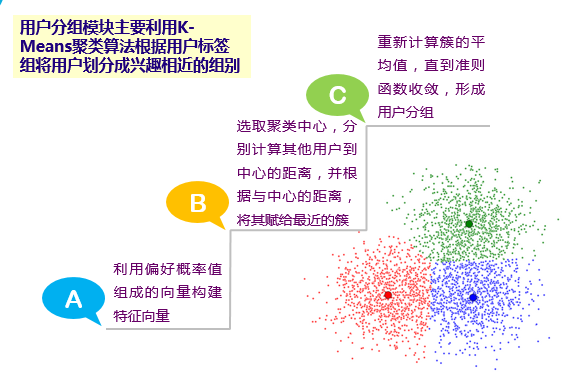
基于蚁群的偏好概率模型
用户可以认为是蚂蚁,而用户的兴趣即为目标,用户下载过的应用标签为道路,并留下了相应的信息素。我们的模型就通过计算用户选择该目标的概率值来选择出用户感兴趣的标签组,该标签组作为用户兴趣的描述。
当用户执行完一次选择时,需要将本次用户下载的应用的标签加入用户自身的标签库中,并用更新函数进行信息素更新,即更新概率函数,从而实现对用户兴趣变化的快速反应。
模型的构建分为以下三步:
基于Kmeans聚类的用户分组模型
排序算法选择模型
下面我们通过一个简单的示例来介绍我们基于随机森林的排序算法选择模型,我们以游戏业务为例进行说明。首先,我们提取所有游戏业务日志,构建业务矩阵,包括用户特征、应用特征以及最优算法。之后,我们对每一条日志利用NDCG对不同的算法进行评价,并根据NDCG的大小选择应用最优算法,填入业务矩阵的算法中。对于老用户,我们用上述训练集训练一棵随机森林,当要对老用户进行推荐排序时,我们将用户的特征放入随机森林中,获取用户最优算法。对于新用户,由于其没有历史数据,我们用业务相关的所有用户投票结果作为该用户的最优算法。

相关文章推荐
- (new)new的作用到底是什么?
- GRE写作必备句型
- CENTOS7阿里云LAMP环境搭建
- JScharts快速入门
- 编译so动态库出现relocation R_X86_64_32 against `a local symbol
- js显示json数据
- 2014鞍山直播比赛H称号HDU5077(DFS修剪+通过计)
- python,datetime
- 企业退信的常见问题?
- #ifndef/#define/#endif使用详解
- 2012年5月SAT香港真题解析
- MFC中的Format
- 【java】【classpath】【javac】【java】
- android listview实现树形菜单及进行选择操作
- 杭电之统计汉字
- git
- OSI模型的理解
- (微信框架之雏形)ViewPager+Fragment实现滑动标签页
- Java培训-IO流补充
- Android控件属性大全