Dual SVM (对偶支持向量机)
2015-07-12 16:50
141 查看
1. SVM 目标函数及约束条件
SVM 的介绍及数学推导参考:我的CSDN,此处直接跳过,直接给出 SVM 的目标函数和约束条件:minw,b12wTws.t.yn(wTxn+b)≥1,n=1,..N
2. 拉格朗日乘子形式
利用拉格朗日乘子法可以将 1 中的有约束问题转化为无约束问题,如下所示:L(w,b,α)=12wTw+∑Nn=0αn(1−yn(wTxn+b))
此时的目标函数变为:
minw,b(maxαn>0L(w,b,α))
对于不好的 (b,w),会有1−yn(wTx+b)>0 ,则:
maxαn>0(Ω+∑Nn=0αn(......))→∞αn→∞
对于好的 (b,w),会有1−yn(wTx+b)<0 ,则:
maxαn>0(Ω+∑Nn=0αn(......))→Ωαn→0
3. 对偶形式
假设 p∗ 表示目标函数的最优解,即:minw,b(maxαn>0L(w,b,α))=p∗
假设 q∗ 表示下述目标函数对偶形式的最优解,即:
maxαn>0(minw,bL(w,b,α))=q∗
则满足:p∗>q∗
因为值域有重叠时,最大值中的最小值比最小值中的最大值要大,如下图所示:
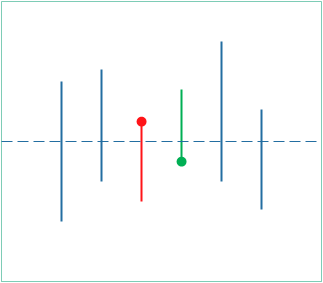
因为 q∗ 提供了 p∗ 的一个下界,在满足某些条件的情况下这两者相等,可以通过求解第二个问题间接的求解第一个问题。
对于二次规划问题,如果满足下述条件,则两个问题等价,构成强对偶关系。
1. 凸问题
2. 有解
3. 线性条件
因此,求解 p∗ 的问题就变成了求解 q∗ 的问题。
maxαn>0⎛⎝⎜⎜⎜⎜minw,b12wTw+∑Nn=1αn(1−yn(wTxn+b))L(w,b)⎞⎠⎟⎟⎟⎟
4. 求解
令 ∂L(w,b)∂b=0=∑Nn=1αnyn,得:∑Nn=1αnyn=0
把上式带入 L(w,b,α) 得:
maxαn>0⎛⎝⎜⎜⎜minw12wTw+∑Nn=1αn(1−ynwTxn)L(w,b)⎞⎠⎟⎟⎟
令 ∂L(w)∂w=0=wi−∑Nn=1αnwTxn,i,得:
w=∑Nn=1αnynxn
把上式带入 L(w),得:
maxαn>0(−12||∑Nn=1αnynxn||2+∑Nn=1αn)
max -> min
minαn>0(12||∑Nn=1αnynxn||2−∑Nn=1αn)
标准对偶 SVM
minαn>0(12∑Nn=1∑Nm=1αnαmynymxTnxm||−∑Nn=1αn)s.t.∑Nn=1αnyn=0αn=0,n=1,2,...,n
转化为二次规划问题
α←QP(Q,p,A,c)minu12αTQα+pTαs.t.aTmα≥cm,m=1,2,...,M
qn,m=ynymxTnxmp=−1Nc=0
8. 求解 b,w
w=∑Nn=1αnynxn
αn(1−yn(wTxn+b))=0αn>0→b=yn−wTx
matlab 中的 quadprog 函数可用于求解该问题。
5. 问题
在第4部份中第7步的二次规划问题中,qn,m=ynymxTnxm,也就是说 Q 的计算复杂度为O(N2d),d 表示每个样本的长度;而在标准的 SVM 问题中,Q 的计算复杂度为O(Nd2),所以,如果 d>N,将原问题转化为对偶问题可以减小计算复杂度,而如果d<N时,直接计算的复杂度反而较低。由于w=∑Nn=1αnynxn,在非支持向量处αn=0,也就是说w只与支持向量有关,所以预测函数
h(x)=sign(wTx+b)只与支持向量有关。而直接的 SVM 不具有这样的性质。
所谓的支持向量就是:离分隔超平面最近的那些点,就是在第6部份标出的那些点。
6. 示例
% 功能:演示对偶SVM算法
% 时间:2015-07-12
clc
clear all
close all
%% 测试样本
dataLength = 2;
dataNumber = [100, 100];
% 第一类
x1 = randn(dataLength, dataNumber(1));
y1 = ones(1, dataNumber(1));
% 第二类
x2 = 5 + randn(dataLength, dataNumber(2));
y2 = -ones(1, dataNumber(2));
% 显示
figure(1);
plot(x1(1,:), x1(2,:), 'bx', x2(1,:), x2(2,:), 'k.');
axis([-3 8 -3 8]);
title('SVM')
hold on
% 合并样本
X = [x1, x2];
Y = [y1, y2];
% 打乱样本顺序
index = randperm(sum(dataNumber));
X(:, index) = X;
Y(:, index) = Y;
%% SVM 训练
% line : w1x1 + w2x2 + b = 0
% weight = [b, w1, w2]
weight = dualSvmTrainMine(X, Y);
%% 测试输出
% y = kx + b
k = -weight(2) / weight(3);
b = weight(1) / weight(3);
xLine = -2:0.1:7;
yLine = k .* xLine - b;
plot(xLine, yLine, 'r')
hold on
%% 查找支持向量
epsilon = 1e-5;
dist = abs(k .* X(1, :) - X(2,:) - b);
i_sv = find(dist <= min(dist(:)) + epsilon);
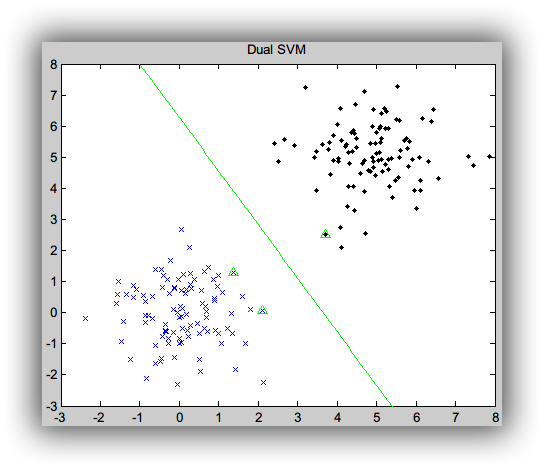
plot(X(1,i_sv), X(2,i_sv),'ro');Dual SVM 结果:
SVM 和 Dual SVM 结果:
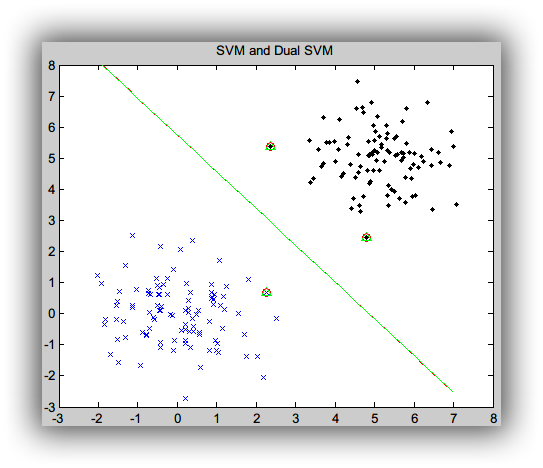
从上图可以看出,SVM 和 Dual SVM 的结果是一致的。
7. 完整代码
GitHub8. 参考
《视觉机器学习20讲》第九讲《Coursera 机器学习技法(林轩田 - 台湾大学 》02 Dual Support Vector Machine

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- 也谈 机器学习到底有没有用 ?
- 量子计算机编程原理简介 和 机器学习
- LSI SVM 挑战IBM SVC
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习书单
- 北美常用的机器学习/自然语言处理/语音处理经典书籍
- 如何提升COBOL系统代码分析效率
- 支持向量机(SVM)算法概述
- 神经网络初步学习手记
- 开始spark之旅
- spark的几点备忘
- 关于机器学习的学习笔记(一):机器学习概念
- 关于机器学习的学习笔记(二):决策树算法
- 关于机器学习的学习笔记(三):k近邻算法
- 长期招聘:自然语言处理工程师
- 长期招聘:个性化推荐
- 人工智能扫盲漫谈篇 & 2018年1月新课资源推荐
- 人工智能唐宇迪老师专题团购~史无前例最低优惠~