CaaS环境下实践经验总结(一):ELK Stack部署
2015-07-06 11:11
225 查看
【编者按】“在审视任何一个新东西的时候,我都会先去尝试发现它与production ready之间到底有多少距离”,这是杜航写作本文的初衷。杜航首先考虑到的是log的处理,尤其对于Docker这个短暂存在的运行环境,log的处理更为重要。Volume虽然可以解决这个问题,但是随着容器数量的增多,工作量也会剧增。杜航决定在灵雀云上搭建一个ELK stack(ELK是一套常用的开源日志监控和分析系统,包括一个分布式索引与搜索服务Elasticsearch,一个管理日志和事件的工具logstash,和一个数据可视化服务Kibana)。
作者杜航,Websense云基础架构组开发经理,专注于OpenStack和Docker。以下为原文:
第一次接触CaaS这个概念,第一次接触灵雀云的时候,我并没有像很多人一样马上推送一个应用以体验Docker所带来的快感。因为我从不怀疑docker的出现所解决环境依赖性问题,提高了产品部署速度。我也从不怀疑灵雀云作为一个CaaS共有云平台对容易的管理,调度,运行的能力。这就是Docker以及CaaS平台出现带来的优势,一分钟之前我还刚把代码提交到github,一分钟之后我提交的代码已经在生产环境上线。可能是因为我长期和一个十分严谨又追求完美的英国团队,特别是英国运维团队合作的背景,在审视任何一个新东西的时候我都会先去尝试发现它与production ready之间到底有多少距离。所以当我准备把应用推送到灵雀云之前,我首先考虑的是除了应用之外我还需要部署什么样的服务来达到生产环境的标准。
第一点考虑到的是log的处理。我想我不需要花太多篇幅解释log的重要性,大家应该都有体会。Docker作为一个短暂存在(ephemeral)的运行环境,数据的持久化是一个要解决的问题。CaaS平台不会像IaaS那样给你vm的登录管理权限,所以你不能想把docker容器运行在物理主机或者虚拟主机上那样通过将存储卷映射到主机上或者链接一个数据容器(data-only container)来保存log数据。灵雀云平台提供了存储卷的功能,可以将log数据存放在一个稳定的云存储平台(从链接看是AWS S3)并提供下载。当时当你管理上百个甚至上千个容器的时候,这种方式也会给你带来很大的工作量。综合以上原因,我决定在灵雀云上搭建一个ELK stack。(E – Elasticsearch, L – Logstash, K – Kibana)
我没有使用网上现有的ELK image,原因有三:
深度CentOS依赖者;
体验一下灵雀云提供的代码仓库集成的功能;
将容器镜像存储在灵雀云镜像仓库可以提高服务启动速度
代码可以在github找到https://github.com/darkheaven1983/elk
以下是如何在灵雀云上部署ELK stack的具体步骤:
1. 关联github代码仓库与灵雀云构建系统,指明Dockerfile在github的路径,并创建一个构建
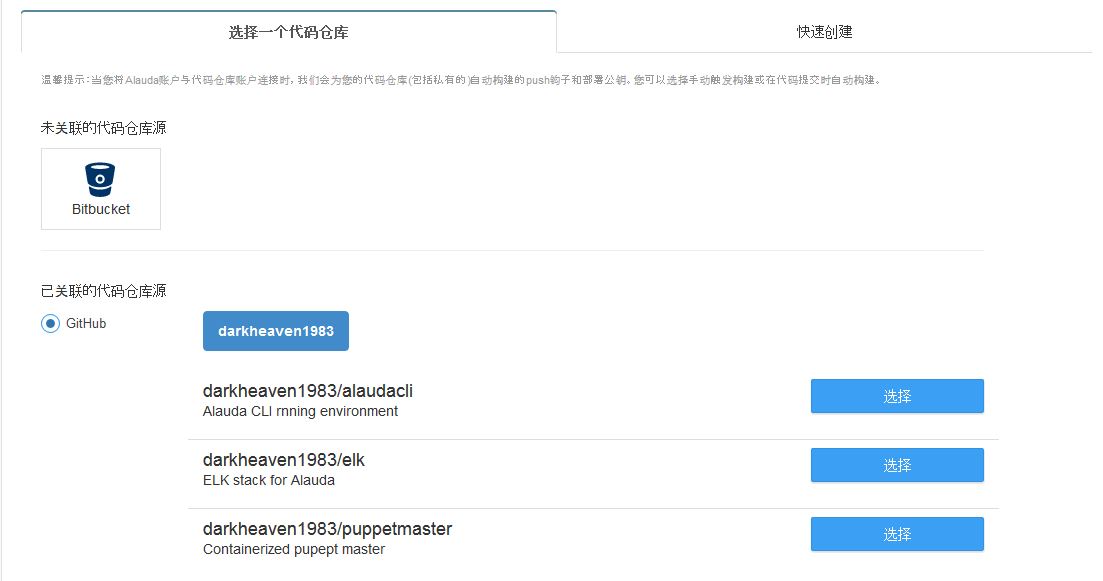
2. git push代码到github触发灵雀云构建docker镜像

镜像build成功之后会出现在个人镜像参仓库里面

3. 通过灵雀云CLI提供的compose功能一键部署ELK stack。Alauda支持的compose在docker compose yaml文件的基础之上做了一些针对自己平台的改动。

以下是elk-alauda.yml的内容
elasticsearch:
extends:
file: ./docker-compose.yml
service: elasticsearch
expose:
- "9200"
volumes:
- /var/lib/elasticsearch:10
kibana:
extends:
file: ./docker-compose.yml
service: kibana
ports:
- "5601/http"
links:
- elasticsearch:elasticsearch
logstash:
extends:
file: ./docker-compose.yml
service: logstash
ports:
- "5000"
links:
- elasticsearch:elasticsearch
extends:关联docker compose yaml文件当中对此容器的配置。
expose:指定一个只有Alauda内部才能访问的端口,我将elsaticsearch的9200端口声明为内部端口保证了数据的安全性,避免将9200端口暴露在公网上。
volumes:创建一个存储卷,确保数据的持久化 – 可以通过alauda CLI中backup功能定期保存存储卷,并且从某一个指定的存储卷恢复数据。
ports:指定一个公网可访问的端口,此端口可以为load balance之后的http端口(80),也可以是load balance之后的TCP端口(随机)。
links:容器之间的连接 – 通过Alauda提供的服务发现功能链接多个容器是容器间可以互相访问。
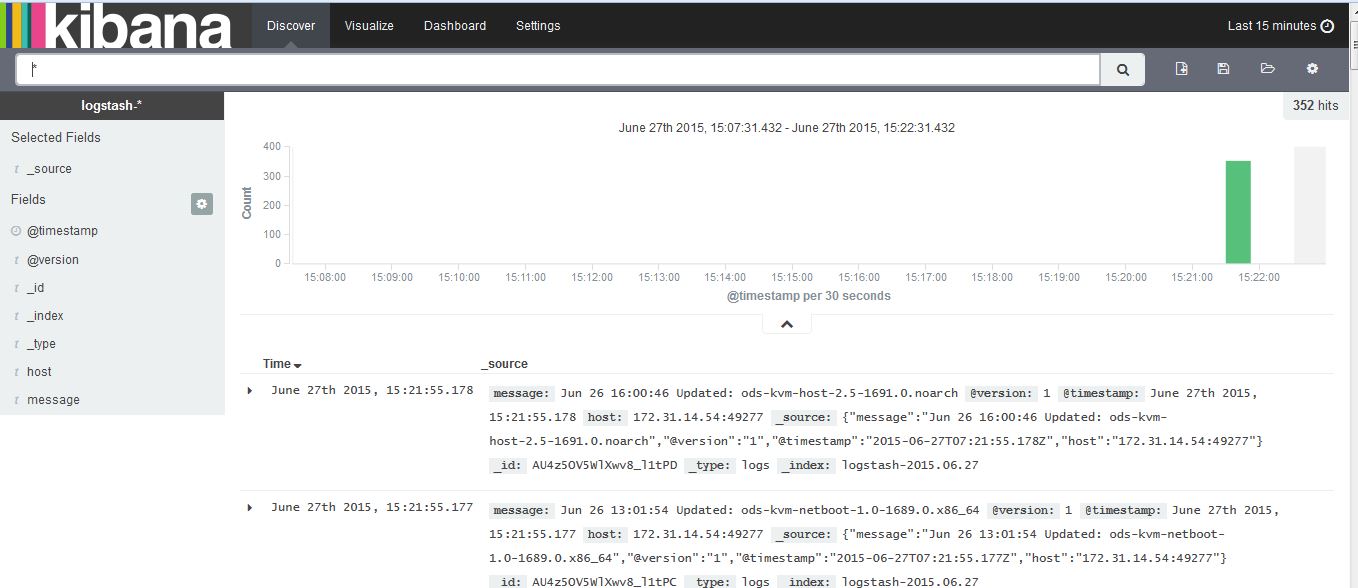
至此,ELK stack在alauda平台的搭建已经结束。由于本实验只是一个PoC的功能,所以logstash的输入是tcp,欢迎大家加入更加复杂的logstash配置。
测试结果:
nc logstash-darkheaven.myalauda.cn 62316 < /var/log/yum.log
作者杜航,Websense云基础架构组开发经理,专注于OpenStack和Docker。以下为原文:
第一次接触CaaS这个概念,第一次接触灵雀云的时候,我并没有像很多人一样马上推送一个应用以体验Docker所带来的快感。因为我从不怀疑docker的出现所解决环境依赖性问题,提高了产品部署速度。我也从不怀疑灵雀云作为一个CaaS共有云平台对容易的管理,调度,运行的能力。这就是Docker以及CaaS平台出现带来的优势,一分钟之前我还刚把代码提交到github,一分钟之后我提交的代码已经在生产环境上线。可能是因为我长期和一个十分严谨又追求完美的英国团队,特别是英国运维团队合作的背景,在审视任何一个新东西的时候我都会先去尝试发现它与production ready之间到底有多少距离。所以当我准备把应用推送到灵雀云之前,我首先考虑的是除了应用之外我还需要部署什么样的服务来达到生产环境的标准。
第一点考虑到的是log的处理。我想我不需要花太多篇幅解释log的重要性,大家应该都有体会。Docker作为一个短暂存在(ephemeral)的运行环境,数据的持久化是一个要解决的问题。CaaS平台不会像IaaS那样给你vm的登录管理权限,所以你不能想把docker容器运行在物理主机或者虚拟主机上那样通过将存储卷映射到主机上或者链接一个数据容器(data-only container)来保存log数据。灵雀云平台提供了存储卷的功能,可以将log数据存放在一个稳定的云存储平台(从链接看是AWS S3)并提供下载。当时当你管理上百个甚至上千个容器的时候,这种方式也会给你带来很大的工作量。综合以上原因,我决定在灵雀云上搭建一个ELK stack。(E – Elasticsearch, L – Logstash, K – Kibana)
我没有使用网上现有的ELK image,原因有三:
深度CentOS依赖者;
体验一下灵雀云提供的代码仓库集成的功能;
将容器镜像存储在灵雀云镜像仓库可以提高服务启动速度
代码可以在github找到https://github.com/darkheaven1983/elk
以下是如何在灵雀云上部署ELK stack的具体步骤:
1. 关联github代码仓库与灵雀云构建系统,指明Dockerfile在github的路径,并创建一个构建

2. git push代码到github触发灵雀云构建docker镜像

镜像build成功之后会出现在个人镜像参仓库里面

3. 通过灵雀云CLI提供的compose功能一键部署ELK stack。Alauda支持的compose在docker compose yaml文件的基础之上做了一些针对自己平台的改动。

以下是elk-alauda.yml的内容
elasticsearch:
extends:
file: ./docker-compose.yml
service: elasticsearch
expose:
- "9200"
volumes:
- /var/lib/elasticsearch:10
kibana:
extends:
file: ./docker-compose.yml
service: kibana
ports:
- "5601/http"
links:
- elasticsearch:elasticsearch
logstash:
extends:
file: ./docker-compose.yml
service: logstash
ports:
- "5000"
links:
- elasticsearch:elasticsearch
extends:关联docker compose yaml文件当中对此容器的配置。
expose:指定一个只有Alauda内部才能访问的端口,我将elsaticsearch的9200端口声明为内部端口保证了数据的安全性,避免将9200端口暴露在公网上。
volumes:创建一个存储卷,确保数据的持久化 – 可以通过alauda CLI中backup功能定期保存存储卷,并且从某一个指定的存储卷恢复数据。
ports:指定一个公网可访问的端口,此端口可以为load balance之后的http端口(80),也可以是load balance之后的TCP端口(随机)。
links:容器之间的连接 – 通过Alauda提供的服务发现功能链接多个容器是容器间可以互相访问。
至此,ELK stack在alauda平台的搭建已经结束。由于本实验只是一个PoC的功能,所以logstash的输入是tcp,欢迎大家加入更加复杂的logstash配置。
测试结果:
nc logstash-darkheaven.myalauda.cn 62316 < /var/log/yum.log


相关文章推荐
- android 图片格式和像素引发的问题
- 中兴通讯携智慧轨道(iRail)解决方案参加非洲轨交展
- recv函数的用法详解
- NYOJ 65 另一种阶乘问题
- Spring(之二)--深入研究
- gsoap编译错误 LNK2005
- 【Developing Log】数据库连接权限非动态
- 【整理】--批量修改文件后缀名
- 文本框的应用--获得焦点和失去焦点
- “Zabbix poller processes more than 75% busy”警报问题解决
- 文章标题
- 解决Firefox浏览器每次打开都弹出导入向导的问题
- 一些达成共识的JavaScript编码风格约定
- Pollard-rho大整数分解
- 【Android】手势输入拨号器
- Unity的DrawCall
- MAC下显示系统隐藏目录和文件
- 创建一个卡片对象,卡片上标有“名字”、“地址”和“电话”等信息。名片对象提供一个方法以输出这些信息。
- GRE写作必备句型
- Java程序员学习C++之数组和动态数组