HBase的LSM树
2015-07-05 22:57
211 查看
HBase的LSM树
讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来:
哈希存储引擎 是哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,如果不需要有序的遍历数据,哈希表就是your Mr.Right
B树存储引擎是B树(关于B树的由来,数据结构以及应用场景可以看之前一篇博文)的持久化实现,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描(B+树的叶子节点之间的指针),对应的存储系统就是关系数据库(Mysql等)。
LSM树(Log-Structured Merge Tree)存储引擎和B树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
通过以上的分析,应该知道LSM树的由来了,LSM树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端的说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级,读性能低了一个数量级。
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。

以上这些大概就是HBase存储的设计主要思想,这里分别对应说明下:
因为小树先写到内存中,为了防止内存数据丢失,写内存的同时需要暂时持久化到磁盘,对应了HBase的MemStore和HLog
MemStore上的树达到一定大小之后,需要flush到HRegion磁盘中(一般是Hadoop DataNode),这样MemStore就变成了DataNode上的磁盘文件StoreFile,定期HRegionServer对DataNode的数据做merge操作,彻底删除无效空间,多棵小树在这个时机合并成大树,来增强读性能。
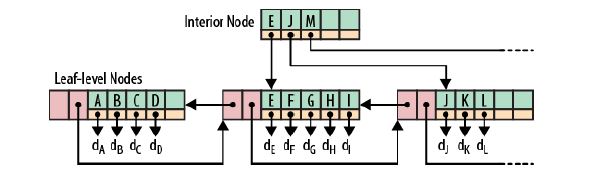
关于LSM Tree,对于最简单的二层LSM Tree而言,内存中的数据和磁盘你中的数据merge操作,如下图

图来自lsm论文
lsm tree,理论上,可以是内存中树的一部分和磁盘中第一层树做merge,对于磁盘中的树直接做update操作有可能会破坏物理block的连续性,但是实际应用中,一般lsm有多层,当磁盘中的小树合并成一个大树的时候,可以重新排好顺序,使得block连续,优化读性能。
hbase在实现中,是把整个内存在一定阈值后,flush到disk中,形成一个file,这个file的存储也就是一个小的B+树,因为hbase一般是部署在hdfs上,hdfs不支持对文件的update操作,所以hbase这么整体内存flush,而不是和磁盘中的小树merge update,这个设计也就能讲通了。内存flush到磁盘上的小树,定期也会合并成一个大树。整体上hbase就是用了lsm tree的思路。
原文地址:http://www.cnblogs.com/yanghuahui/p/3483754.html
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
LSM树是HBase里非常有创意的一种数据结构,它和传统的B+树不太一样,下面先说说B+树。
相信大家对B+树已经非常的熟悉,比如Oracle的普通索引就是采用B+树的方式,下面是一个B+树的例子:
根节点和枝节点很简单,分别记录每个叶子节点的最小值,并用一个指针指向叶子节点。
叶子节点里每个键值都指向真正的数据块(如Oracle里的RowID),每个叶子节点都有前指针和后指针,这是为了做范围查询时,叶子节点间可以直接跳转,从而避免再去回溯至枝和跟节点。
B+树最大的性能问题是会产生大量的随机IO,随着新数据的插入,叶子节点会慢慢分裂,逻辑上连续的叶子节点在物理上往往不连续,甚至分离的很远,但做范围查询时,会产生大量读随机IO。
对于大量的随机写也一样,举一个插入key跨度很大的例子,如7->1000->3->2000 ... 新插入的数据存储在磁盘上相隔很远,会产生大量的随机写IO.
从上面可以看出,低下的磁盘寻道速度严重影响性能(近些年来,磁盘寻道速度的发展几乎处于停滞的状态)。
为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
为了更好的说明LSM树的原理,下面举个比较极端的例子:
现在假设有1000个节点的随机key,对于磁盘来说,肯定是把这1000个节点顺序写入磁盘最快,但是这样一来,读就悲剧了,因为key在磁盘中完全无序,每次读取都要全扫描;
那么,为了让读性能尽量高,数据在磁盘中必须得有序,这就是B+树的原理,但是写就悲剧了,因为会产生大量的随机IO,磁盘寻道速度跟不上。
LSM树本质上就是在读写之间取得平衡,和B+树相比,它牺牲了部分读性能,用来大幅提高写性能。
它的原理是把一颗大树拆分成N棵小树, 它首先写入到内存中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,内存的小树会flush到磁盘上。当读时,由于不知道数据在哪棵小树上,因此必须遍历所有的小树,但在每颗小树内部数据是有序的。

以上就是LSM树最本质的原理,有了原理,再看具体的技术就很简单了。
1)首先说说为什么要有WAL(Write Ahead Log),很简单,因为数据是先写到内存中,如果断电,内存中的数据会丢失,因此为了保护内存中的数据,需要在磁盘上先记录logfile,当内存中的数据flush到磁盘上时,就可以抛弃相应的Logfile。
2)什么是memstore, storefile?很简单,上面说过,LSM树就是一堆小树,在内存中的小树即memstore,每次flush,内存中的memstore变成磁盘上一个新的storefile。
3)为什么会有compact?很简单,随着小树越来越多,读的性能会越来越差,因此需要在适当的时候,对磁盘中的小树进行merge,多棵小树变成一颗大树。
原文链接:http://blog.csdn.net/u010415792/article/details/8897599
讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来:
哈希存储引擎 是哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,如果不需要有序的遍历数据,哈希表就是your Mr.Right
B树存储引擎是B树(关于B树的由来,数据结构以及应用场景可以看之前一篇博文)的持久化实现,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描(B+树的叶子节点之间的指针),对应的存储系统就是关系数据库(Mysql等)。
LSM树(Log-Structured Merge Tree)存储引擎和B树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
通过以上的分析,应该知道LSM树的由来了,LSM树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端的说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级,读性能低了一个数量级。
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。
以上这些大概就是HBase存储的设计主要思想,这里分别对应说明下:
因为小树先写到内存中,为了防止内存数据丢失,写内存的同时需要暂时持久化到磁盘,对应了HBase的MemStore和HLog
MemStore上的树达到一定大小之后,需要flush到HRegion磁盘中(一般是Hadoop DataNode),这样MemStore就变成了DataNode上的磁盘文件StoreFile,定期HRegionServer对DataNode的数据做merge操作,彻底删除无效空间,多棵小树在这个时机合并成大树,来增强读性能。
关于LSM Tree,对于最简单的二层LSM Tree而言,内存中的数据和磁盘你中的数据merge操作,如下图
图来自lsm论文
lsm tree,理论上,可以是内存中树的一部分和磁盘中第一层树做merge,对于磁盘中的树直接做update操作有可能会破坏物理block的连续性,但是实际应用中,一般lsm有多层,当磁盘中的小树合并成一个大树的时候,可以重新排好顺序,使得block连续,优化读性能。
hbase在实现中,是把整个内存在一定阈值后,flush到disk中,形成一个file,这个file的存储也就是一个小的B+树,因为hbase一般是部署在hdfs上,hdfs不支持对文件的update操作,所以hbase这么整体内存flush,而不是和磁盘中的小树merge update,这个设计也就能讲通了。内存flush到磁盘上的小树,定期也会合并成一个大树。整体上hbase就是用了lsm tree的思路。
原文地址:http://www.cnblogs.com/yanghuahui/p/3483754.html
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
LSM树是HBase里非常有创意的一种数据结构,它和传统的B+树不太一样,下面先说说B+树。
1 B+树
相信大家对B+树已经非常的熟悉,比如Oracle的普通索引就是采用B+树的方式,下面是一个B+树的例子:根节点和枝节点很简单,分别记录每个叶子节点的最小值,并用一个指针指向叶子节点。
叶子节点里每个键值都指向真正的数据块(如Oracle里的RowID),每个叶子节点都有前指针和后指针,这是为了做范围查询时,叶子节点间可以直接跳转,从而避免再去回溯至枝和跟节点。
B+树最大的性能问题是会产生大量的随机IO,随着新数据的插入,叶子节点会慢慢分裂,逻辑上连续的叶子节点在物理上往往不连续,甚至分离的很远,但做范围查询时,会产生大量读随机IO。
对于大量的随机写也一样,举一个插入key跨度很大的例子,如7->1000->3->2000 ... 新插入的数据存储在磁盘上相隔很远,会产生大量的随机写IO.
从上面可以看出,低下的磁盘寻道速度严重影响性能(近些年来,磁盘寻道速度的发展几乎处于停滞的状态)。
2 LSM树
为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。为了更好的说明LSM树的原理,下面举个比较极端的例子:
现在假设有1000个节点的随机key,对于磁盘来说,肯定是把这1000个节点顺序写入磁盘最快,但是这样一来,读就悲剧了,因为key在磁盘中完全无序,每次读取都要全扫描;
那么,为了让读性能尽量高,数据在磁盘中必须得有序,这就是B+树的原理,但是写就悲剧了,因为会产生大量的随机IO,磁盘寻道速度跟不上。
LSM树本质上就是在读写之间取得平衡,和B+树相比,它牺牲了部分读性能,用来大幅提高写性能。
它的原理是把一颗大树拆分成N棵小树, 它首先写入到内存中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,内存的小树会flush到磁盘上。当读时,由于不知道数据在哪棵小树上,因此必须遍历所有的小树,但在每颗小树内部数据是有序的。
以上就是LSM树最本质的原理,有了原理,再看具体的技术就很简单了。
1)首先说说为什么要有WAL(Write Ahead Log),很简单,因为数据是先写到内存中,如果断电,内存中的数据会丢失,因此为了保护内存中的数据,需要在磁盘上先记录logfile,当内存中的数据flush到磁盘上时,就可以抛弃相应的Logfile。
2)什么是memstore, storefile?很简单,上面说过,LSM树就是一堆小树,在内存中的小树即memstore,每次flush,内存中的memstore变成磁盘上一个新的storefile。
3)为什么会有compact?很简单,随着小树越来越多,读的性能会越来越差,因此需要在适当的时候,对磁盘中的小树进行merge,多棵小树变成一颗大树。
原文链接:http://blog.csdn.net/u010415792/article/details/8897599

相关文章推荐
- php安装及配置笔记
- 应用select 函数控制多线程中子线程结束方法
- PHP 类的一些知识点
- Shell中特殊的变量
- [leedcode 08]String to Integer (atoi)
- neutron外部网卡禁用GRO
- K650c + Ubuntu15.04双显卡切换
- 二叉树相关算法总结
- Excel Sheet Column Title
- python print和strip
- MySQL 8小时问题
- [转]分布式计算框架综述
- Longest Substring Without Repeating Characters
- IOS菜鸟的所感所思(十六)—— 立体式的切换视图
- 通过代码自定义cell(cell的高度不一致)
- 黑马程序员——12_File_deleteOnExit()试验
- LeetCode 219: Contains Duplicate II
- 算法与数据结构八日谈之六——数据结构专题(uncompleted)
- 2015070507 - EffactiveJava笔记 - 第13条 使类和成员的可访问性最小(1)
- Red and Black(BFS or DFS)