数据挖掘导论 之 分类
2015-07-01 22:58
357 查看
这篇总结一下《数据挖掘导论》中的分类部分:
类标号:离散属性(区别于回归,回归的目标属性是连续的)
作用:
描述性建模:作为解释性的工具,区分不同类的对象。
预测性建模:预测未知记录的类标号。
一般方法:用一种学习算法(learning algorithm)确定分类模型,该模型能够很好的拟合输入数据中类标号和属性集之间的联系。学习算法得到的模型不仅要很好地拟合输入数据,还要能正确的预测未知样本的类标号。
性能评估:混淆矩阵(confusion matrix)
决策树的建立(Hunt 算法)
方法:通过将训练记录相继划分成较纯的子集,以递归的方式建立决策树。
如果与结点t相关联的训练集(Dt)中所有记录都属于同一个类y,则t是叶节点,用y_t标志。
如果Dt中包含属于多个类的记录,则选择一个属性测试条件(attribute test condition),将记录划分成较小的子集。对于测试条件的每个输出,创建一个子女结点,并根据测试结果将Dt中的记录分布到子女结点中。然后对每个子女结点,递归的调用该算法。
选择最佳划分:根据划分后子女结点不纯性的程度,不纯的程度越低,类分布就越倾斜。
Entropy(t)
Gini(t)
Classification error(t)
比较父节点(划分前)的不纯程度和子女结点(划分后)的不纯程度,它们的差越大(增益),测试条件的效果就越好。(当选择熵作为不纯性度量时,熵的差就是所谓的信息增益)
特点:
非参数方法:不要求任何先验假设,不假定类和其他属性服从一定的概率分布。
找到最佳决策树是NP完全问题。
对噪声具有很好的鲁棒性。
冗余属性(与其他属性强相关)不会对决策树的准确性造成影响。
数据碎片问题(在叶节点,记录太少,不能做出具有统计意义的判决):当样本数小于某个特定阈值时停止分裂。
噪声
缺乏代表性样本
多重比较过程中:在决策树增长过程中,进行多种测试,以确定最优的属性

形式:规则前件->规则后件
质量衡量:
覆盖率(coverage):数据集中触发规则的记录所占的比例。
准确率(accuracy):触发的记录中类标号等于y的记录所占的比例。
工作原理:根据测试记录所触发的规则来对记录进行分类。
性质:保证每一条记录被且仅被一条规则所覆盖。
互斥规则(Mutually Exclusive Rule):规则集中不存在两条规则被同一个记录所触发。
穷举规则(Exhaustive Rule):对属性值的任一组合,规则集都存在一个规则加以覆盖。
问题:
规则集不是穷举的—–添加一个默认规则来覆盖那些未被覆盖的记录。
规则集不是互斥的—–解决冲突
有序规则(ordered rule):规则集中的规则按照优先级降序排列。对测试记录由覆盖记录的最高秩的规则对其进行分类。
无序规则(unordered rule):把每条被触发规则的后件看做对相应类的一次投票,然后计票确定测试记录的类标号。

最近邻分类器
方法:把每个样例看做d(属性个数)维空间上的点,给定一个测试样例,使用邻近性度量方法,计算该测试样例与训练集中其他数据点的邻近度。
k值的选取:
大:误分类
小:过拟合(噪声)
基于实例的学习:使用具体的训练样例进行预测,而不必维护源自数据的抽样模型。
贝叶斯定理
把类的先验知识和从数据中收集的新证据相结合的统计原理
P(Y|X) = ( P(X|Y) P(Y) ) / P(X)
P(X|Y)——类条件概率(用朴素贝叶斯和贝叶斯信念网络计算)
P(X)——证据(对不同Y的后验概率是相同的)
P(Y)——先验概率(通过计算训练集中属于每个类的训练记录所占的比例来估计)
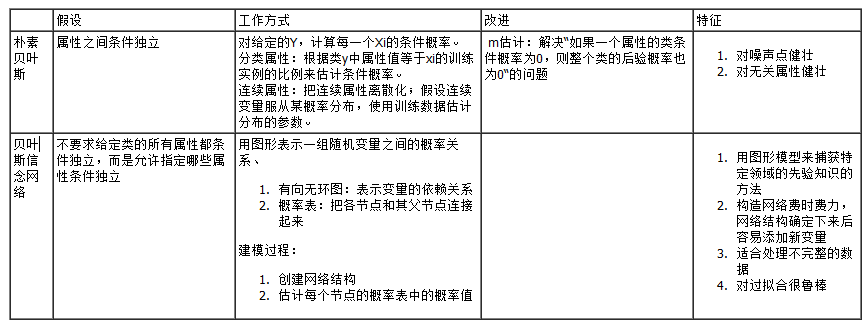
朴素贝叶斯V.S.贝叶斯信念网络
最大边缘超平面:具有最大边缘的决策边界比那些具有较小边缘的决策边界具有更好的泛化误差。
线性支持向量机:寻找具有最大边缘的超平面。
软边缘(soft margin):
学习允许一定训练错误的决策边界。
在优化问题的约束中引入正值的松弛变量。
非线性支持向量机
原理:将数据从原先的坐标空间变换到一个新的坐标空间中,从而可以在变换后的坐标空间中使用一个线性的决策边界来划分样本。
方法:使用核技术
特征:
可以表现为凸优化问题,可以利用有效算法发现目标函数的全局最小值。
通过最大化决策边界的边缘来控制模型
通过对每个分类属性引入一个哑变量,可以应用于分类数据。
-
分类
含义:确定对象属于哪个预定义的目标类。通过学习得到一个目标函数(target function)f,把每个属性集x映射到一个预先定义的类标号y。类标号:离散属性(区别于回归,回归的目标属性是连续的)
作用:
描述性建模:作为解释性的工具,区分不同类的对象。
预测性建模:预测未知记录的类标号。
一般方法:用一种学习算法(learning algorithm)确定分类模型,该模型能够很好的拟合输入数据中类标号和属性集之间的联系。学习算法得到的模型不仅要很好地拟合输入数据,还要能正确的预测未知样本的类标号。
性能评估:混淆矩阵(confusion matrix)
决策树
结构:由结点和有向边组成的层次结构决策树的建立(Hunt 算法)
方法:通过将训练记录相继划分成较纯的子集,以递归的方式建立决策树。
如果与结点t相关联的训练集(Dt)中所有记录都属于同一个类y,则t是叶节点,用y_t标志。
如果Dt中包含属于多个类的记录,则选择一个属性测试条件(attribute test condition),将记录划分成较小的子集。对于测试条件的每个输出,创建一个子女结点,并根据测试结果将Dt中的记录分布到子女结点中。然后对每个子女结点,递归的调用该算法。
选择最佳划分:根据划分后子女结点不纯性的程度,不纯的程度越低,类分布就越倾斜。
Entropy(t)
Gini(t)
Classification error(t)
比较父节点(划分前)的不纯程度和子女结点(划分后)的不纯程度,它们的差越大(增益),测试条件的效果就越好。(当选择熵作为不纯性度量时,熵的差就是所谓的信息增益)
特点:
非参数方法:不要求任何先验假设,不假定类和其他属性服从一定的概率分布。
找到最佳决策树是NP完全问题。
对噪声具有很好的鲁棒性。
冗余属性(与其他属性强相关)不会对决策树的准确性造成影响。
数据碎片问题(在叶节点,记录太少,不能做出具有统计意义的判决):当样本数小于某个特定阈值时停止分裂。
模型过拟合
原因噪声
缺乏代表性样本
多重比较过程中:在决策树增长过程中,进行多种测试,以确定最优的属性
分类器评估
基于规则的分类器
定义:使用”if…then…”规则来对记录进行分类。形式:规则前件->规则后件
质量衡量:
覆盖率(coverage):数据集中触发规则的记录所占的比例。
准确率(accuracy):触发的记录中类标号等于y的记录所占的比例。
工作原理:根据测试记录所触发的规则来对记录进行分类。
性质:保证每一条记录被且仅被一条规则所覆盖。
互斥规则(Mutually Exclusive Rule):规则集中不存在两条规则被同一个记录所触发。
穷举规则(Exhaustive Rule):对属性值的任一组合,规则集都存在一个规则加以覆盖。
问题:
规则集不是穷举的—–添加一个默认规则来覆盖那些未被覆盖的记录。
规则集不是互斥的—–解决冲突
有序规则(ordered rule):规则集中的规则按照优先级降序排列。对测试记录由覆盖记录的最高秩的规则对其进行分类。
无序规则(unordered rule):把每条被触发规则的后件看做对相应类的一次投票,然后计票确定测试记录的类标号。
最近邻分类器
积极学习V.S.消极学习最近邻分类器
方法:把每个样例看做d(属性个数)维空间上的点,给定一个测试样例,使用邻近性度量方法,计算该测试样例与训练集中其他数据点的邻近度。
k值的选取:
大:误分类
小:过拟合(噪声)
基于实例的学习:使用具体的训练样例进行预测,而不必维护源自数据的抽样模型。
贝叶斯分类
使用概率的原因:属性集和类变量的关系是不确定的,尽管测试记录的属性集和某些训练样例相同,但是由于噪声等不确定因素,也不能正确预测他的分类号。贝叶斯定理
把类的先验知识和从数据中收集的新证据相结合的统计原理
P(Y|X) = ( P(X|Y) P(Y) ) / P(X)
P(X|Y)——类条件概率(用朴素贝叶斯和贝叶斯信念网络计算)
P(X)——证据(对不同Y的后验概率是相同的)
P(Y)——先验概率(通过计算训练集中属于每个类的训练记录所占的比例来估计)
朴素贝叶斯V.S.贝叶斯信念网络
支持向量机
支持向量:训练实例的一个子集,用来表示决策边界。最大边缘超平面:具有最大边缘的决策边界比那些具有较小边缘的决策边界具有更好的泛化误差。
线性支持向量机:寻找具有最大边缘的超平面。
软边缘(soft margin):
学习允许一定训练错误的决策边界。
在优化问题的约束中引入正值的松弛变量。
非线性支持向量机
原理:将数据从原先的坐标空间变换到一个新的坐标空间中,从而可以在变换后的坐标空间中使用一个线性的决策边界来划分样本。
方法:使用核技术
特征:
可以表现为凸优化问题,可以利用有效算法发现目标函数的全局最小值。
通过最大化决策边界的边缘来控制模型
通过对每个分类属性引入一个哑变量,可以应用于分类数据。
-

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- 也谈 机器学习到底有没有用 ?
- 量子计算机编程原理简介 和 机器学习
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习书单
- 北美常用的机器学习/自然语言处理/语音处理经典书籍
- 如何提升COBOL系统代码分析效率
- 支持向量机(SVM)算法概述
- 神经网络初步学习手记
- 开始spark之旅
- spark的几点备忘
- 关于机器学习的学习笔记(一):机器学习概念
- 关于机器学习的学习笔记(二):决策树算法
- 关于机器学习的学习笔记(三):k近邻算法
- 长期招聘:自然语言处理工程师
- 长期招聘:个性化推荐
- 为什么需要一个推荐引擎平台
- 机器学习之决策树整理
- Kernel PCA