大型网站架构体系的演变(上)
2015-06-30 20:14
441 查看
本文转自:http://blog.csdn.net/dinglang_2009/article/details/46398885
互联网上有很多关于网站架构的各种分享,有些主要是从运维和基础架构的角度去分析的(堆机器,做集群),太关注技术细节实现,普通的开发人员基本看不太懂。
本文上篇将主要介绍大型网站基础架构的扩展,下篇则重点从应用程序的角度去介绍网站架构的扩展和演变。
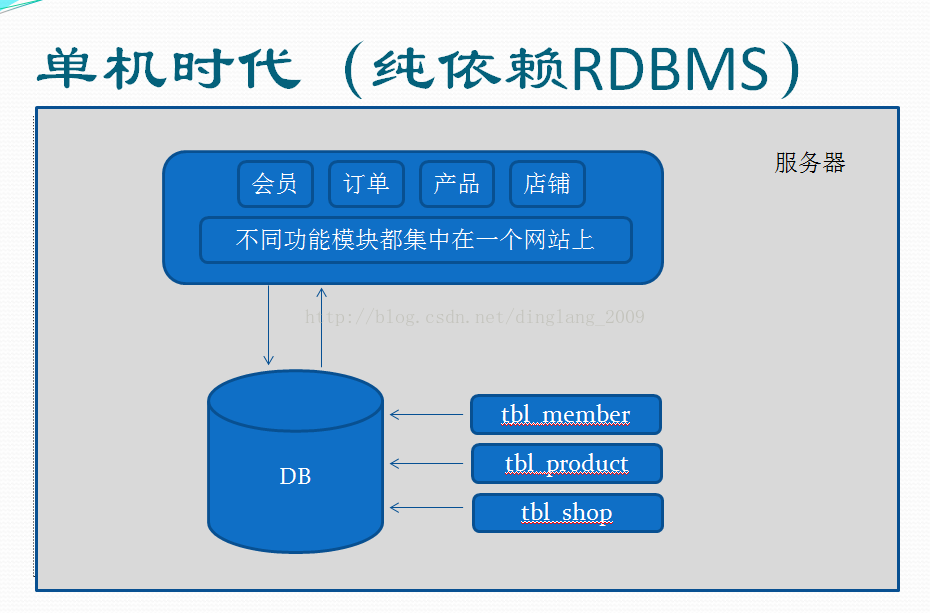
草根时期,快速开发网站并上线。当然,通常只是先试水,用户规模也没有形成,经济能力和投入也非常有限。
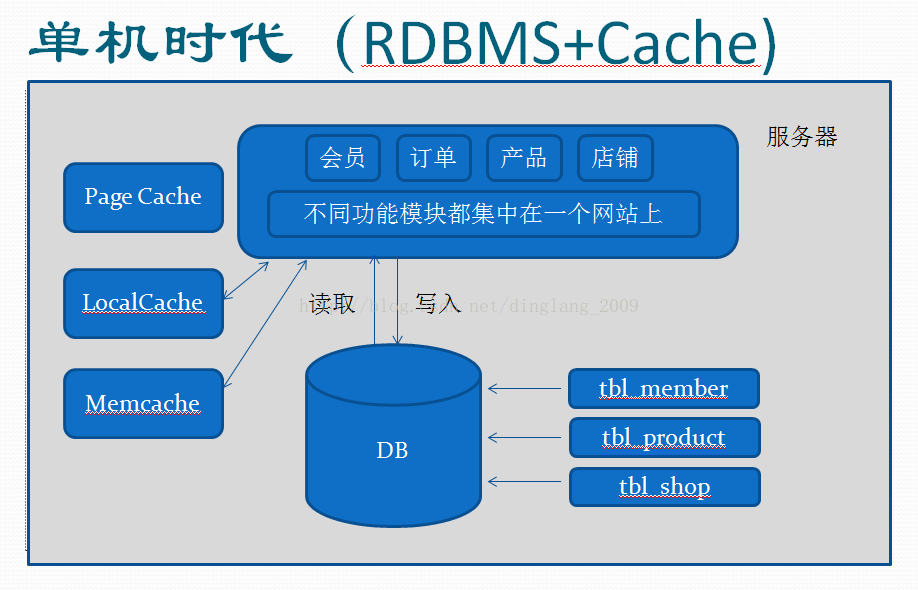
有一定的业务量和用户规模了,想提升网站速度,于是,缓存出场了。
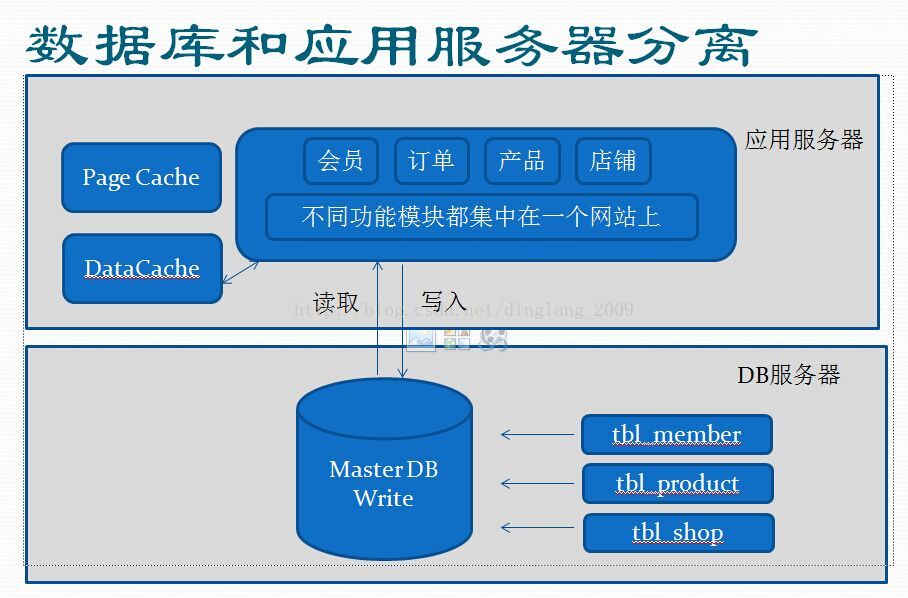
市场反响还不错,用户量每天在增长,数据库疯狂读写,逐渐发现一台服务器快撑不住了。于是,决定把DB和APP做分离。
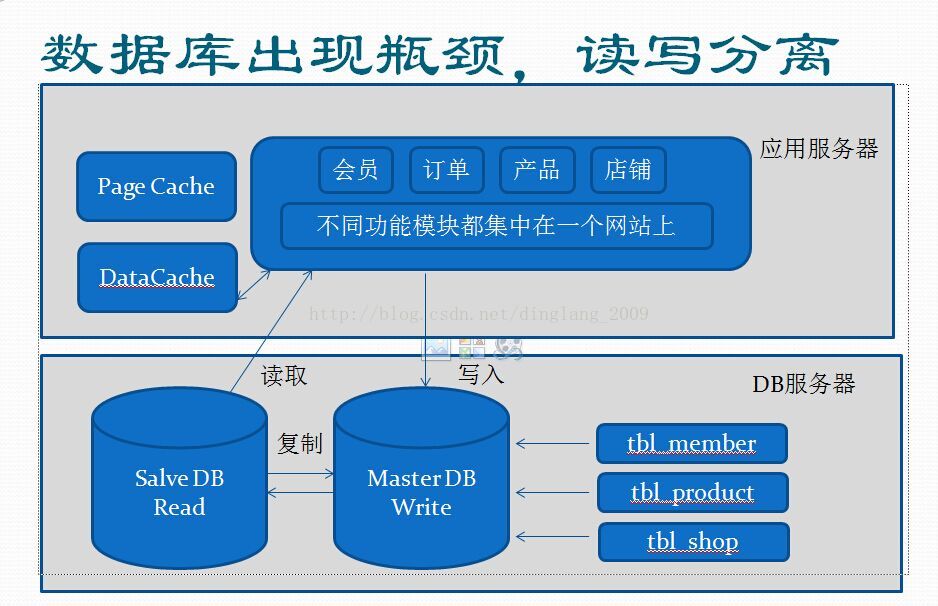
单台数据库也感觉快撑不住了,一般都会尝试做“读写分离”。由于大部分互联网“读多写少”的特性所决定的。Salve的台数,取决于按业务评估的读写比例。
数据库层面是缓解了,但是应用程序层面也出现了瓶颈,由于访问量增大,加上早期程序员水平有限写的代码也很烂,人员流动性也大,很难去维护和优化。所以,很常用的办法还是“堆机器”。
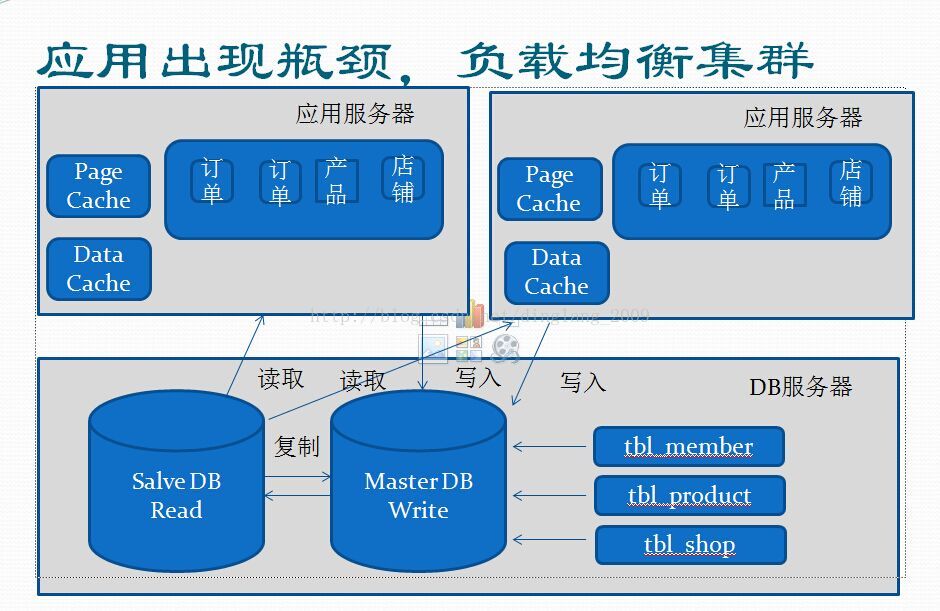
加机器谁都会加,关键是加完之后得有效果,加完之后可能会引发一些问题。例如非常常见的:页面输出缓存和本地缓存的问题,Session保存的问题......
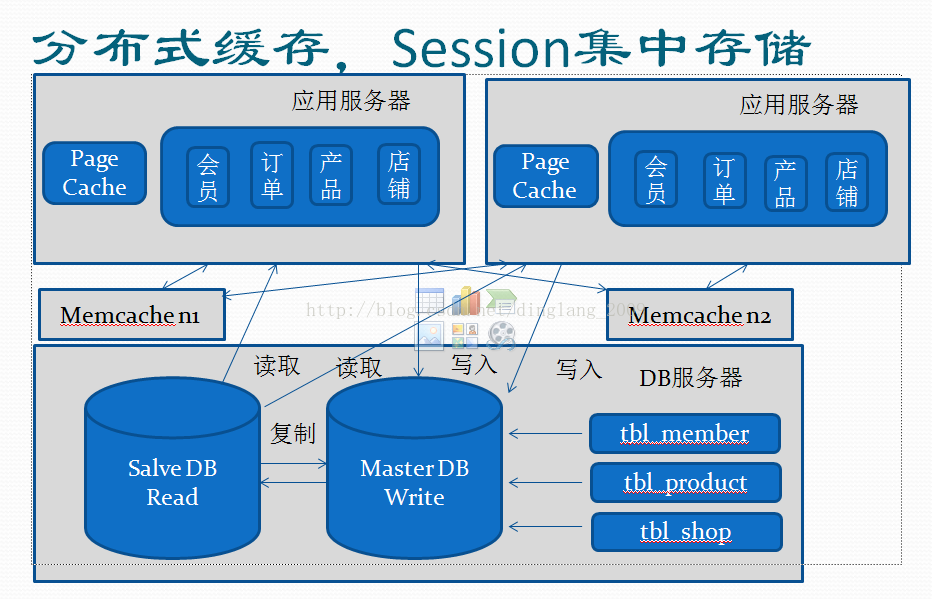
到这里,已经基本做到了DB层面和应用层面的横向扩展了,可以开始关注一些其它方面,例如:站内搜索的精准度,对DB的依赖,开始引入全文索引。
Java领域用的较多的是Lucene、Solr等,而php领域用的比较多的是sphinx/coreseek。
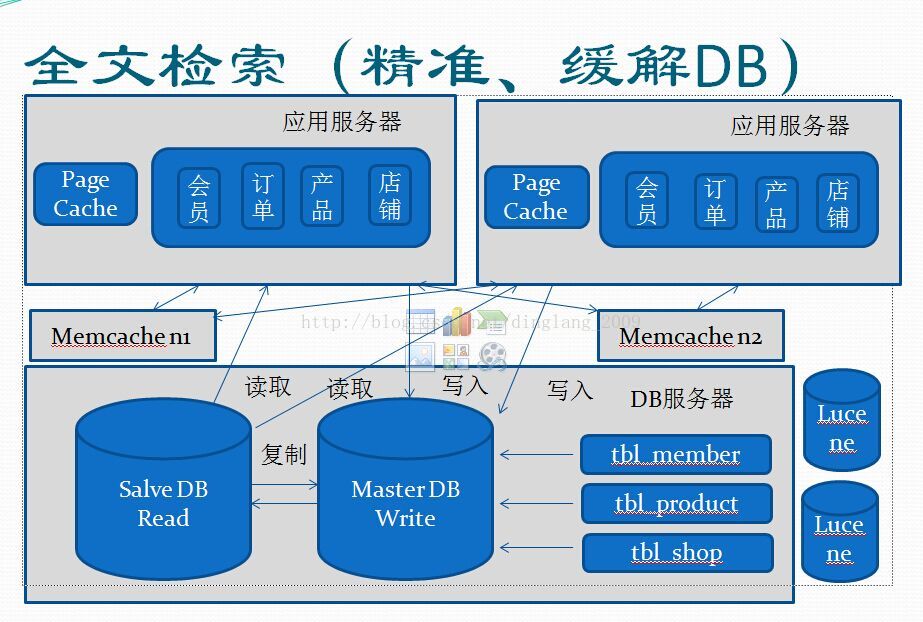
到目前为止,一个能够承载日均百万级访问量的中型网站架构基本介绍完了。当然,每一步扩展里面都会有很多技术实现的细节,后续有时间会写文章单独去剖析那些细节。
下篇我们继续。
互联网上有很多关于网站架构的各种分享,有些主要是从运维和基础架构的角度去分析的(堆机器,做集群),太关注技术细节实现,普通的开发人员基本看不太懂。
本文上篇将主要介绍大型网站基础架构的扩展,下篇则重点从应用程序的角度去介绍网站架构的扩展和演变。
草根时期,快速开发网站并上线。当然,通常只是先试水,用户规模也没有形成,经济能力和投入也非常有限。
有一定的业务量和用户规模了,想提升网站速度,于是,缓存出场了。
市场反响还不错,用户量每天在增长,数据库疯狂读写,逐渐发现一台服务器快撑不住了。于是,决定把DB和APP做分离。
单台数据库也感觉快撑不住了,一般都会尝试做“读写分离”。由于大部分互联网“读多写少”的特性所决定的。Salve的台数,取决于按业务评估的读写比例。
数据库层面是缓解了,但是应用程序层面也出现了瓶颈,由于访问量增大,加上早期程序员水平有限写的代码也很烂,人员流动性也大,很难去维护和优化。所以,很常用的办法还是“堆机器”。
加机器谁都会加,关键是加完之后得有效果,加完之后可能会引发一些问题。例如非常常见的:页面输出缓存和本地缓存的问题,Session保存的问题......
到这里,已经基本做到了DB层面和应用层面的横向扩展了,可以开始关注一些其它方面,例如:站内搜索的精准度,对DB的依赖,开始引入全文索引。
Java领域用的较多的是Lucene、Solr等,而php领域用的比较多的是sphinx/coreseek。
到目前为止,一个能够承载日均百万级访问量的中型网站架构基本介绍完了。当然,每一步扩展里面都会有很多技术实现的细节,后续有时间会写文章单独去剖析那些细节。
下篇我们继续。

相关文章推荐
- mediawiki中全局变量$wgLogo用于设置网站的Logo
- IT架构之IT架构标准——思维导图
- Web前端体系架构
- ODPS技术架构及应用实践
- 批处理刷新网站
- 漫谈SOA(面向服务架构)
- 网站链接
- 浅谈大型web系统架构
- 一个优美的架构需要考虑的几个问题
- 给网站编辑MM写的简易代码情书
- Postback回发事件的真实感触
- dubbo学习笔记-关于架构
- DRBD+HeartBeat+NFS:配置NFS的高可用 推荐
- 如何快速开发网站?
- 自然排名,更倾向于哪个要素?
- 微信网站开发需要注意事项(1)
- 如何让虚拟目录里面的webconfig不继承网站的设置
- KVM虚拟化环境高可用方案探讨
- 架构师学习之路1设计模式
- Hyper-V 高可用性 (添加Hyper-V功能)