大数据环境下的数据仓库建设(转)
2015-06-22 18:11
295 查看
这几天研究了一家美国的大数据公司1010data,它在产品白皮书中提出了新一代数据仓库的概念(NEXT-GENERATION DATA DISCOVERY),相对于第一代数据仓库,具有如下一些特征:
l 用户可以针对任何问题进行分析和查询,也就是说,分析系统要提供更加友好的操作体验,更加明细的数据粒度;
l 分析效率和水平扩展,在大数据量的情况下,也要保证分析过程的高效率;
l 数据混搭和数据分享,强调企业内部数据和外部数据的综合分析,以及数据的货币化;
在它的报告中,同时也非常强调自助分析的重要性,要让数据分析摆脱IT支撑部门的束缚,这其实和第一点的内容有些类似,只是更加强调了系统的易用性。为了进一步阐述它的观点,白皮书将第一代数据仓库和新一代数据仓库进行了对比,如下:
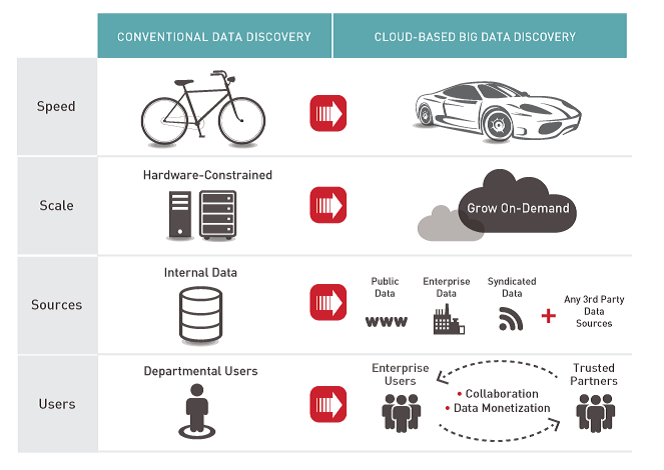
总体上来讲,我比较赞同它前面提出的新一代数据仓库的特点,即易用、高效、扩展、数据分享等,但对于上图中的对比,我很难苟同,尤其是在速度、扩展两个方面。传统数据仓库,数据规模也可能很大,比如,电信运营商的话单数据量就可以很大,在数据仓库建设中,必然要考虑处理速度以及扩展的问题,只是不会使用到目前阶段很火的hadoop等,但可以使用分布式MySQL、并行计算等方面的技术,从而提高处理速度,解决设备扩展的问题。
我个人认为,在大数据时代建设数据仓库,着重要解决的就是打通企业内数据和企业外数据,实现“全数据”的挖掘和应用,这是大数据的精髓所在。之所以要实现全数据的分析,是基于以下考虑:
1) 可以更加全面的定位问题,提出解决办法。传统数据仓库,由于只专注于打通企业内部的业务系统孤岛,获取到的是企业内部数据,是影响问题的企业内部因素,而引起问题的原因往往是复杂的,除了企业自身因素外,外部的宏观因素、社会因素也是必不可少的分析内容,而传统数据仓库对此是无能为力的。
2) 针对未来的预测可以更加精确。大数据时代更加强调数据预测,利用数据挖掘算法实现辅助决策,而分析算法的精确性,取决于影响预测结果的变量多样性和准确性。例如,我们耳熟能详的视频推荐,根据用户的收视历史推荐最感兴趣的内容,推荐算法的命中率很大程度上取决于你所能找到的影响用户收视兴趣的变量,包括收视历史、用户分类、流行视频等等,假设你收集企业内部的用户收视历史,缺少了外部群体的收视习惯,那么你的推荐算法就是有缺陷的,尤其是当用户规模较小的时候,如第一时间获取到大家正在追看《武媚娘》的信号。
l 用户可以针对任何问题进行分析和查询,也就是说,分析系统要提供更加友好的操作体验,更加明细的数据粒度;
l 分析效率和水平扩展,在大数据量的情况下,也要保证分析过程的高效率;
l 数据混搭和数据分享,强调企业内部数据和外部数据的综合分析,以及数据的货币化;
在它的报告中,同时也非常强调自助分析的重要性,要让数据分析摆脱IT支撑部门的束缚,这其实和第一点的内容有些类似,只是更加强调了系统的易用性。为了进一步阐述它的观点,白皮书将第一代数据仓库和新一代数据仓库进行了对比,如下:
总体上来讲,我比较赞同它前面提出的新一代数据仓库的特点,即易用、高效、扩展、数据分享等,但对于上图中的对比,我很难苟同,尤其是在速度、扩展两个方面。传统数据仓库,数据规模也可能很大,比如,电信运营商的话单数据量就可以很大,在数据仓库建设中,必然要考虑处理速度以及扩展的问题,只是不会使用到目前阶段很火的hadoop等,但可以使用分布式MySQL、并行计算等方面的技术,从而提高处理速度,解决设备扩展的问题。
我个人认为,在大数据时代建设数据仓库,着重要解决的就是打通企业内数据和企业外数据,实现“全数据”的挖掘和应用,这是大数据的精髓所在。之所以要实现全数据的分析,是基于以下考虑:
1) 可以更加全面的定位问题,提出解决办法。传统数据仓库,由于只专注于打通企业内部的业务系统孤岛,获取到的是企业内部数据,是影响问题的企业内部因素,而引起问题的原因往往是复杂的,除了企业自身因素外,外部的宏观因素、社会因素也是必不可少的分析内容,而传统数据仓库对此是无能为力的。
2) 针对未来的预测可以更加精确。大数据时代更加强调数据预测,利用数据挖掘算法实现辅助决策,而分析算法的精确性,取决于影响预测结果的变量多样性和准确性。例如,我们耳熟能详的视频推荐,根据用户的收视历史推荐最感兴趣的内容,推荐算法的命中率很大程度上取决于你所能找到的影响用户收视兴趣的变量,包括收视历史、用户分类、流行视频等等,假设你收集企业内部的用户收视历史,缺少了外部群体的收视习惯,那么你的推荐算法就是有缺陷的,尤其是当用户规模较小的时候,如第一时间获取到大家正在追看《武媚娘》的信号。

相关文章推荐
- 属性readwrite,readonly,assign,retain,copy,nonatomic
- POJ 1575 && HDU 1039 Easier Done Than Said?(水~)
- 大数据透视《西游记》之妖怪分布
- 大数据的傲慢
- 从hdfs批量导出数据到hbase表中
- 数据开放,敢问路在何方
- 当智能交通遇上大数据 智能交通不再是梦
- 3、flume数据导入到Hdfs中
- 常用raid概述
- onRetainNonConfigurationInstance和getLastNonConfigurationInstance
- grails、Searchable问题:报此错的原因是因为文件缓存空间冲突;
- Grails多数据源
- grails调用存储过程(调用的时候call不能少了那个一对大括号{},少了调用结果不对)
- grails不想用系统生成的字段id可以自己改
- Grails验证与错误打印
- 在Grails中如何使用Class.forName
- Grails小技巧:工作目录
- grails、groovy创建xml
- grails转换base64
- 【BZOJ】【4152】【AMPZZ2014】The Captain