MySQL数据库优化学习笔记
2015-06-19 20:27
681 查看
数据库优化的目的:
1.避免出现页面访问错误
由于数据库连接timeout产生页面5xx错误
由于慢查询造成页面无法加载
由于阻塞造成数据无法提交
2.增加数据库的稳定性
很多数据库问题都是由于低效的查询引起的
3.优化用户体验
流畅页面的访问速度
良好的网站功能体验
可以从几个方面进行数据库优化:
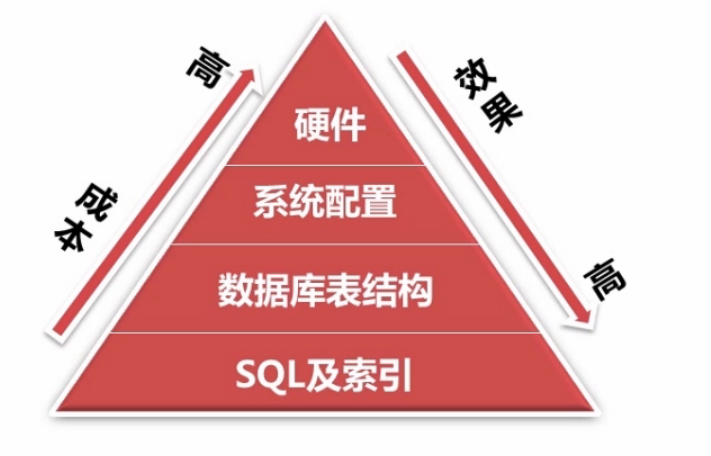
使用MySQL慢查日志对有效率问题的SQL进行监控
慢查日志的分析工具-mysqldumpslow
慢查日志的分析工具-pt-query-digest(信息比较完整,推荐学习)
有问题的SQL:
查询次数多且每次查询占用时间长的SQL
IO大的SQL
未命中索引的SQL
SQL语句优化:
通过explain查询和分析SQL的执行计划
Count()和Max()的优化
子查询的优化
通常情况下,需要把子查询优化为join查询,但在优化时要注意关联键是否有一对多的关系,要注意重复数据。(用distinct消除)
group by的优化
SQL句子优化过程示例:(查询每个演员演了多少次电影)
(1)优化前,一般的group by查询
select actor.first_name,actor.last_name,count(*) from sakila.film_actor inner join sakila.actor using(actor_id) group by film_actor.actor_id;
(2)优化group by后
select actor.first_name,actor.last_name,c.cnt from sakila.film_actor inner join (select actor_id,count(*) as cnt from sakila.film_actor group by actor_id) as c using(actor_id);
Limit的优化
Limit常用于分页处理,时常会伴随order by从句使用。
优化步骤1:使用有索引的列或主键进行Order By排序
优化步骤2:记录上次返回的主键,在下次查询时使用主键过滤
SQL句子优化过程示例:(查询指定范围的电影信息)
(1)优化前,一般的limit查询
select film_id,description from sakila.film order by title limit 50,5;
(2)优化order by后
select film_id,description from sakila.film order by film_id limit 50,5;
(3)记录上次返回的主键,继续优化
select film_id,description from sakila.film where film_id > 55 and film_id <= 60 order by film_id limit 50,5;
在where从句,group by从句,order by从句,on从句中出现的列
索引字段越小越好
离散度大的列放到联合索引的前面
索引的维护及优化:
重复索引:是指相同的列以相同的顺序建立的同类型的索引。
eg:一个列既声明为primary key主键,又声明为unique唯一键。
冗余索引:是指多个索引的前缀列相同,或是在联合索引中包含了主键的索引。
eg:一个列既声明为primary key主键,又在联合主键中使用到。
查找重复及冗余索引
使用工具pt-duplicate-key-checker查找
删除不用索引
目前MySQL中还没有记录索引的使用情况,但是在PerconMySQL和MariaDB中可以通过INDEX_STATISTICS表来查看哪些索引未被使用,但在MySQL中目前只能通过慢查日志(mysql-slow.log)配合pt-index-usage工具来进行索引使用情况的分析。
1.使用可以存下你的数据的最小的数据类型。
2.使用简单的数据类型。(存储时间)int要比varchar类型在mysql处理上简单。
3.尽可能使用not null 定义字段。
4.尽量少用text等类型,一定要用时最好考虑分表。
具体示例:
1.使用 int 来存储日期时间,利用FROM_UNIXTIME(),UNIX_TIMESTAMP()两个函数来进行转换。
建表:
create table test(id int auto_increment not null, timestr int, primary key(id));
插入数据:
insert into test(timestr) values(UNIX_TIMESTAMP(‘2015-6-20 13:12:00’));
选择数据:
select FROM_UNIXTIME(t
c087
imestr)from test;
2.使用 bigint 来存储 IP 地址,利用INET_ATON(),INER_NTOA()两个函数来进行转换。
建表:
create table sessions(id int auto_increment not null, ipaddress bigint, primary key(id));
插入数据:
insert into sessions(ipaddress) values(INET_ATON(‘113.103.159.102’));
选择数据:
select INET_NTOA(ipaddress) from sessions;
表的范式化优化
范式化是指数据库设计的规范,目前说到范式化一般是指第三设计范式,也就是要求数据表中不存在非关键字段对任意候选关键字段的传递函数依赖,则该数据库设计符合第三范式。
[示例]
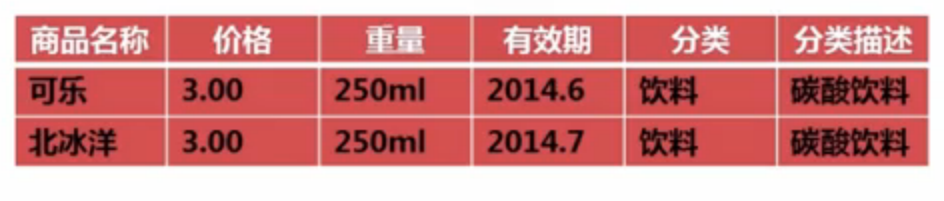
该表不符合第三范式设计,因为存在以下传递函数依赖关系:
(商品名称)->(分类)->(分类描述)
也就是说存在非关键字段“分类描述”对关键字段“商品名称”的传递函数依赖。
该表设计存在以下问题:
1.数据冗余。
对于每个商品都要记录分类和分类描述。
2.数据的插入异常。
如果没有饮料商品,则没法记录饮料分类相当信息。
3.数据的更新异常。
更新饮料分类信息时,需要更新全部商品对应分类信息。
4.数据的删除异常。
删除所有饮料类商品后,把分类也一起删除了,逻辑上是不正确的。
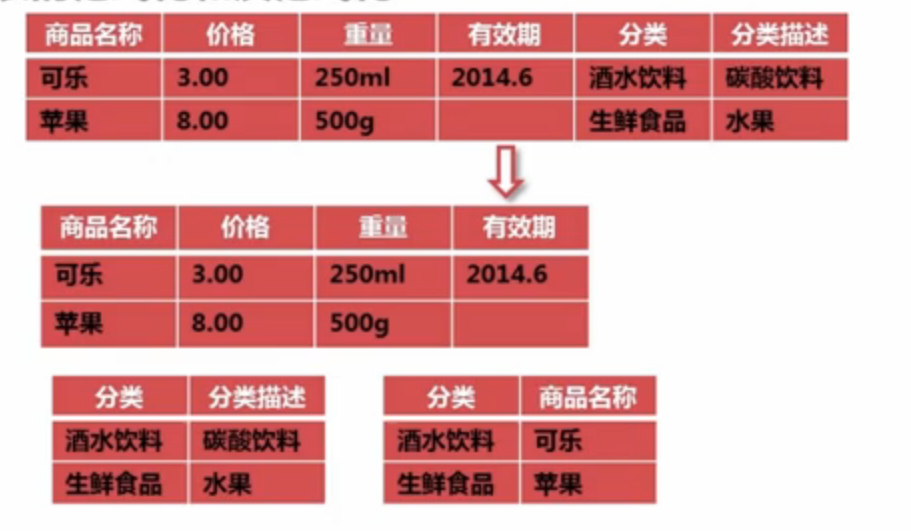
对表的设计进行一下转换:(如图)
表的反范式化优化
反范式化式指为了查询效率的考虑把原本符合第三范式的表适当的增加冗余,以达到优化查询效率的目的,反范式化是一种以空间来换取时间的操作。
对表的设计进行一下转换:(如图)
原先的表设计:

改进的表设计:

这样,在查询用户订单信息和用户信息时,就不用关联两张表,只需要查询订单表即可。(查询会快些)但是这种冗余设计同时也会导致订单表数据列的增加,即存储空间的增加。
所有说,反范式化的思想就是:“用空间来换取时间”。
表结构设计(表的垂直拆分):
所谓垂直拆分,就是把原来一个有很多列的表拆分成多个表,这解决了表的宽度问题。
通常垂直拆分可以按以下原则进行:
把不常用的字段单独存放到一个表中。
把大字段独立存放到一个表中。
把经常一起使用的字段放到一起。
表结构设计(表的水平拆分):
表的水平拆分是为了解决单表的数据量过大的问题,水平拆分的表,每一个表的结构都是完全一致的。
常用的水平拆分方法为:
对id列进行hash运算,如果要拆分成5个表使用,则mod(id,5)取出0-4的值,即对5取模。
针对不同的hashID把数据存放到不同的表中。例如:取模为0的数据插到表1,取模为1的数据插到表2等等。
挑战:
跨分区表进行数据查询
统计及后台报表操作
注意:
这里前后台数据查询可以分开操作,前台注重时效性(使用拆分后的表),后台不用太注意时效性(使用汇总后的表)。
数据库是基于操作系统的,目前大多数MySQL都是安装在Linux系统之上,所以对于操作系统的一些参数配置也会影响到MySQL的性能。
MySQL配置文件优化:
MySQL可以通过启动时指定配置参数和使用配置文件两种方法进行配置。
常用参数:(只是简单介绍)
innodb_buffer_pool_size(缓冲池的大小)
innodb_buffer_pool_instances(缓冲池的个数)
innodb_log_buffer_size(事务日志缓冲区大小)
innodb_flush_log_at_trx_commit(默认值为1)
innodb_read_io_threads(读线程数)
innodb_write_io_threads(写线程数)
innodb_file_per_table(控制每一个innodb表使用独立的空间)
innodb_stats_on_metadata(决定什么情况下刷新innodb表的统计信息)
第三方配置工具:
Percona Configuration Wizard
参考链接:http://tools.percona.com/wizard
MySQL有一些工作只能使用到单核CPU。
MySQL对CPU核数的支持并不是越多越快。
Disk IO 优化示意图:

1.避免出现页面访问错误
由于数据库连接timeout产生页面5xx错误
由于慢查询造成页面无法加载
由于阻塞造成数据无法提交
2.增加数据库的稳定性
很多数据库问题都是由于低效的查询引起的
3.优化用户体验
流畅页面的访问速度
良好的网站功能体验
可以从几个方面进行数据库优化:
SQL语句优化:
1.如何发现有问题的SQL?使用MySQL慢查日志对有效率问题的SQL进行监控
慢查日志的分析工具-mysqldumpslow
慢查日志的分析工具-pt-query-digest(信息比较完整,推荐学习)
有问题的SQL:
查询次数多且每次查询占用时间长的SQL
IO大的SQL
未命中索引的SQL
SQL语句优化:
通过explain查询和分析SQL的执行计划
Count()和Max()的优化
子查询的优化
通常情况下,需要把子查询优化为join查询,但在优化时要注意关联键是否有一对多的关系,要注意重复数据。(用distinct消除)
group by的优化
SQL句子优化过程示例:(查询每个演员演了多少次电影)
(1)优化前,一般的group by查询
select actor.first_name,actor.last_name,count(*) from sakila.film_actor inner join sakila.actor using(actor_id) group by film_actor.actor_id;
(2)优化group by后
select actor.first_name,actor.last_name,c.cnt from sakila.film_actor inner join (select actor_id,count(*) as cnt from sakila.film_actor group by actor_id) as c using(actor_id);
Limit的优化
Limit常用于分页处理,时常会伴随order by从句使用。
优化步骤1:使用有索引的列或主键进行Order By排序
优化步骤2:记录上次返回的主键,在下次查询时使用主键过滤
SQL句子优化过程示例:(查询指定范围的电影信息)
(1)优化前,一般的limit查询
select film_id,description from sakila.film order by title limit 50,5;
(2)优化order by后
select film_id,description from sakila.film order by film_id limit 50,5;
(3)记录上次返回的主键,继续优化
select film_id,description from sakila.film where film_id > 55 and film_id <= 60 order by film_id limit 50,5;
索引优化:
如何选择合适的列建立索引:在where从句,group by从句,order by从句,on从句中出现的列
索引字段越小越好
离散度大的列放到联合索引的前面
索引的维护及优化:
重复索引:是指相同的列以相同的顺序建立的同类型的索引。
eg:一个列既声明为primary key主键,又声明为unique唯一键。
冗余索引:是指多个索引的前缀列相同,或是在联合索引中包含了主键的索引。
eg:一个列既声明为primary key主键,又在联合主键中使用到。
查找重复及冗余索引
使用工具pt-duplicate-key-checker查找
删除不用索引
目前MySQL中还没有记录索引的使用情况,但是在PerconMySQL和MariaDB中可以通过INDEX_STATISTICS表来查看哪些索引未被使用,但在MySQL中目前只能通过慢查日志(mysql-slow.log)配合pt-index-usage工具来进行索引使用情况的分析。
数据库表结构优化:
选择合适的数据类型:1.使用可以存下你的数据的最小的数据类型。
2.使用简单的数据类型。(存储时间)int要比varchar类型在mysql处理上简单。
3.尽可能使用not null 定义字段。
4.尽量少用text等类型,一定要用时最好考虑分表。
具体示例:
1.使用 int 来存储日期时间,利用FROM_UNIXTIME(),UNIX_TIMESTAMP()两个函数来进行转换。
建表:
create table test(id int auto_increment not null, timestr int, primary key(id));
插入数据:
insert into test(timestr) values(UNIX_TIMESTAMP(‘2015-6-20 13:12:00’));
选择数据:
select FROM_UNIXTIME(t
c087
imestr)from test;
2.使用 bigint 来存储 IP 地址,利用INET_ATON(),INER_NTOA()两个函数来进行转换。
建表:
create table sessions(id int auto_increment not null, ipaddress bigint, primary key(id));
插入数据:
insert into sessions(ipaddress) values(INET_ATON(‘113.103.159.102’));
选择数据:
select INET_NTOA(ipaddress) from sessions;
表的范式化优化
范式化是指数据库设计的规范,目前说到范式化一般是指第三设计范式,也就是要求数据表中不存在非关键字段对任意候选关键字段的传递函数依赖,则该数据库设计符合第三范式。
[示例]
该表不符合第三范式设计,因为存在以下传递函数依赖关系:
(商品名称)->(分类)->(分类描述)
也就是说存在非关键字段“分类描述”对关键字段“商品名称”的传递函数依赖。
该表设计存在以下问题:
1.数据冗余。
对于每个商品都要记录分类和分类描述。
2.数据的插入异常。
如果没有饮料商品,则没法记录饮料分类相当信息。
3.数据的更新异常。
更新饮料分类信息时,需要更新全部商品对应分类信息。
4.数据的删除异常。
删除所有饮料类商品后,把分类也一起删除了,逻辑上是不正确的。
对表的设计进行一下转换:(如图)
表的反范式化优化
反范式化式指为了查询效率的考虑把原本符合第三范式的表适当的增加冗余,以达到优化查询效率的目的,反范式化是一种以空间来换取时间的操作。
对表的设计进行一下转换:(如图)
原先的表设计:
改进的表设计:
这样,在查询用户订单信息和用户信息时,就不用关联两张表,只需要查询订单表即可。(查询会快些)但是这种冗余设计同时也会导致订单表数据列的增加,即存储空间的增加。
所有说,反范式化的思想就是:“用空间来换取时间”。
表结构设计(表的垂直拆分):
所谓垂直拆分,就是把原来一个有很多列的表拆分成多个表,这解决了表的宽度问题。
通常垂直拆分可以按以下原则进行:
把不常用的字段单独存放到一个表中。
把大字段独立存放到一个表中。
把经常一起使用的字段放到一起。
表结构设计(表的水平拆分):
表的水平拆分是为了解决单表的数据量过大的问题,水平拆分的表,每一个表的结构都是完全一致的。
常用的水平拆分方法为:
对id列进行hash运算,如果要拆分成5个表使用,则mod(id,5)取出0-4的值,即对5取模。
针对不同的hashID把数据存放到不同的表中。例如:取模为0的数据插到表1,取模为1的数据插到表2等等。
挑战:
跨分区表进行数据查询
统计及后台报表操作
注意:
这里前后台数据查询可以分开操作,前台注重时效性(使用拆分后的表),后台不用太注意时效性(使用汇总后的表)。
系统配置优化:
操作系统配置优化:数据库是基于操作系统的,目前大多数MySQL都是安装在Linux系统之上,所以对于操作系统的一些参数配置也会影响到MySQL的性能。
MySQL配置文件优化:
MySQL可以通过启动时指定配置参数和使用配置文件两种方法进行配置。
常用参数:(只是简单介绍)
innodb_buffer_pool_size(缓冲池的大小)
innodb_buffer_pool_instances(缓冲池的个数)
innodb_log_buffer_size(事务日志缓冲区大小)
innodb_flush_log_at_trx_commit(默认值为1)
innodb_read_io_threads(读线程数)
innodb_write_io_threads(写线程数)
innodb_file_per_table(控制每一个innodb表使用独立的空间)
innodb_stats_on_metadata(决定什么情况下刷新innodb表的统计信息)
第三方配置工具:
Percona Configuration Wizard
参考链接:http://tools.percona.com/wizard
服务器硬件优化:
如何选择CPU:MySQL有一些工作只能使用到单核CPU。
MySQL对CPU核数的支持并不是越多越快。
Disk IO 优化示意图:

相关文章推荐
- MySQL数据库的安装与配置(Windows)
- MySQL隔离等级
- 用MySQL实现微博关注关系的方案分析
- mysql 左连接
- mysql 分区
- mysql数据库结构比较工具
- MySQL行级锁、表级锁、页级锁详细介绍
- MySQL 加锁处理分析
- MySQL优化之——修改默认存储引擎
- Mysql的导入
- mysql常用操作
- mysql查询语句的不等于写法
- Mac下如何使用MySql
- MySQL初级培训
- 实践:搭建基于Load Balancer的MySql Cluster
- MySQL配置文件mysql.ini参数详解
- MySql检测阻塞,锁等待sql
- mysql性能优化-慢查询分析、优化索引和配置
- 【转载】mysql text 长度
- MySQL my.cnf参数配置优化详解