2.Logistic Regression
2015-06-19 16:59
357 查看
ca27
J(θ)的计算公式
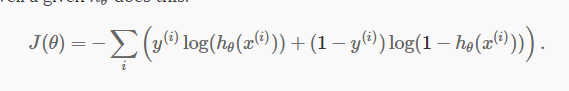
2.
梯度g的计算公式
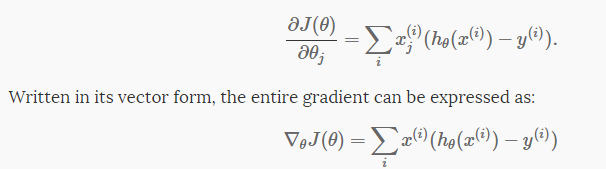
load_mnist.m文件
logistic_regression.m文件
binary_classifier_accuracy.m文件
sigmoid.m文件
参考斯坦福的UFLDL教程
http://ufldl.stanford.edu/tutorial/supervised/LogisticRegression/重要公式
1.J(θ)的计算公式
2.
梯度g的计算公式
代码
logreg.m文件%加上这三句才可以用minFunc,loadMNISTImages,loadMNISTLabels等函数
addpath ../common
addpath ../common/minFunc_2012/minFunc
addpath ../common/minFunc_2012/minFunc/compiled
%binary_digits=true表示只取标签为0,1样本
binary_digits = true;
%载入数据
[train,test] = load_mnist(binary_digits);
% train.X 784*12665,784个特征,12665个样本
%给train.X 加上一行截距 全为1 则train.X 785*12665
train.X = [ones(1,size(train.X,2)); train.X];
%test.X 784*2115,784个特征,2115个样本
%给test.X 加上一行截距 全为1 则test.X 785*2115
test.X = [ones(1,size(test.X,2)); test.X];
% m=12665列, n=785行
m=size(train.X,2);
n=size(train.X,1);
% 选项,最大迭代次数100
options = struct('MaxIter', 100);
%随机初始化theta,每个值都接近于0,但不为0
%theta 785*1
theta = rand(n,1)*0.001;
tic;
%求theta,minFunc和fminunc用法差不多,但minFunc的第一个参数的返回值必须包含梯度
theta=minFunc(@logistic_regression, theta, options, train.X, train.y);
fprintf('Optimization took %f seconds.\n', toc);
%预测准确度
tic;
accuracy = binary_classifier_accuracy(theta,train.X,train.y);
fprintf('Training accuracy: %2.1f%%\n', 100*accuracy);
% Print out accuracy on the test set.
accuracy = binary_classifier_accuracy(theta,test.X,test.y);
fprintf('Test accuracy: %2.1f%%\n', 100*accuracy);load_mnist.m文件
%载入数据的函数
function[train,test]=load_mnist(binary_digits)
%X为训练数据的特征,y为训练数据的标签
%X:784*60000 60000个训练样本 每个样本784个特征
%y: 1*60000 60000个训练样本的标签
X=loadMNISTImages('train-images.idx3-ubyte');
y=loadMNISTLabels('train-labels.idx1-ubyte')';%取了转置
%只选取标签为0或1的数据
if(binary_digits)
X=[X(:,y==1),X(:,y==0)]; %只取y=1和y=0的列
y=[y(y==1),y(y==0)];%只取y=1和y=0的列
end
%shuffle过程
%产生从1:length(y)的随机序列
I = randperm(length(y));
X=X(:,I);
y=y(I);
%对X归一化,使均值为0
%X:784*12665
%关于std函数,第三个参数2表示按行求标准差
%s 784*1 m 784*1
s=std(X,0,2);
%repmat用来复制矩阵
s1=repmat(s,1,size(X,2));
m=mean(X,2);
m1=repmat(m,1,size(X,2));
%s+0.1防止除数为0
X=(X-m1)./(s1+0.1);
train.X=X;
train.y=y;
%X为测试数据的特征,y为测试数据的标签
%X:784*10000 10000个训练样本 每个样本784个特征
%y: 1*10000 10000个训练样本的标签
X=loadMNISTImages('t10k-images.idx3-ubyte');
y=loadMNISTLabels('t10k-labels.idx1-ubyte')';
%只选取标签为0或1的数据
if (binary_digits)
X = [ X(:,y==0), X(:,y==1) ]; %只取y=1和y=0的列
y = [ y(y==0), y(y==1) ]; %只取y=1和y=0的列
end
%shuffle过程
%产生从1:length(y)的随机序列
I = randperm(length(y));
y=y(I);
X=X(:,I);
% 用和训练集一样的均值和标准差作归一化
s2=repmat(s,1,size(X,2));
m2=repmat(m,1,size(X,2));
X=(X-m2)./(s2+0.1);
% Place these in the testing set
test.X=X;
test.y=y;
endlogistic_regression.m文件
%计算J(theta)和梯度 function [f,g] = logistic_regression(theta, X,y) %theta 785*1 %X 785*12665 785个特征 12665个样本 %y 1*12665 12665个标签 m=size(X,2); %J(theta),损失函数 f=-sum(y.*log(sigmoid(theta'*X))+(1-y).*log(1-sigmoid(theta'*X))); %梯度 g = X*(sigmoid(theta'*X)-y)'; end
binary_classifier_accuracy.m文件
%准确率计算函数 function accuracy=binary_classifier_accuracy(theta, X,y) correct=sum(y == (sigmoid(theta'*X) > 0.5)); accuracy = correct / length(y);
sigmoid.m文件
function h=sigmoid(a) h=1./(1+exp(-a));

相关文章推荐
- 2.Logistic Regression
- 【Linux探索之旅】第一部分第二课:下载Linux,免费的噢
- 云架构指挥调度平台技术方案建议书
- CADMeister.v6.1-ISO 1DVD
- 怎么判断mp4文件的第一个关键帧在什么位置
- android有时无法读取url图片资源
- 简易Java(04):Java如何进行静态类型检查?
- Table View 学习
- 腾讯云搜纠错(QC)系统----用户的每一次错误搜索都能获得惊喜
- OJ积累--商品销售
- 查看树莓派的CPU温度
- Android的第二次增加SurfaceView基本使用
- JAVA 安全性转码代码(包括sql注入,跨站脚本)
- 解决gnuplot中'Terminal type set to 'unknown'不能显示绘图的问题
- COPRA RF 2005 SR1最新版 (冷弯成型,轧辊设计)
- 自适应屏幕大小的网页是怎么做出来的
- Rhel6.5_Nginx1.45_Php5.59_MySQL5.6.16编译安装(集成LNMP环境)
- 获取日志$6到$NF的字段
- Android Choreographer 源码笔记
- Android Studio开发JNI工程