字节转换之大小端
2015-06-17 17:12
399 查看
今天有个任务是将字节文件转换成整型,我是采用C#的BinaryReader.ReadInt32来直接读取的,运行结果也很顺利,整型结果是1577,但是好奇心驱使我用Ultraedit打开了源文件,但是我发现16进制存储的数组是这样的
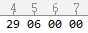
这是什么鬼…,读取结果:
0x29060000=0*16^0+0*16^1+0*16^2+0*16^3+6*16^4+0*16^5+9*16^6+2*16^7=688259072
这和1577完全不搭嘎啊,都溢出了…
于是乎问大牛,查资料,得知这是大小端问题,我的是小端,低位存低位地址,高位存高位地址。
读取的正确结果应该是:
0x00000629=9*16^0+2*16^1+6*16^2=1577
大端:高位存在低地址,低位存在高地址;
小端:高位存在高地址,低位存在低地址;(intel的x86,ARM普遍都是属于小端)
查询自己机器到底是大端还是小端的方法也不复杂
C#自带BitConverter封装的IsLittleEndian判断
C++判断也简单,采用Union的方式判断,因为在Union中所有的元素都放在一块内存空间中,mu.c的内存地址是和int型的变量i的起始地址对齐的,所以改变int型的值mu.i=1,如果为小端存储,则mu.c==1,反之,则为大端存储。详细可以参考:http://blog.csdn.net/anialy/article/details/8015183
上文是各种被大牛喷的结果,后来的童鞋们请打牢基础,被喷请自查…
这是什么鬼…,读取结果:
0x29060000=0*16^0+0*16^1+0*16^2+0*16^3+6*16^4+0*16^5+9*16^6+2*16^7=688259072
这和1577完全不搭嘎啊,都溢出了…
于是乎问大牛,查资料,得知这是大小端问题,我的是小端,低位存低位地址,高位存高位地址。
读取的正确结果应该是:
0x00000629=9*16^0+2*16^1+6*16^2=1577
大端:高位存在低地址,低位存在高地址;
小端:高位存在高地址,低位存在低地址;(intel的x86,ARM普遍都是属于小端)
查询自己机器到底是大端还是小端的方法也不复杂
C#自带BitConverter封装的IsLittleEndian判断
//判断大小端(BigEndian - LittleEndian, C#/Win小端,Java大端,网络传输大端) //数字或Unicode区分大小端(2的倍数的字节数) bool isLittle = BitConverter.IsLittleEndian; //数字 //方法一 int c = 97; byte[] cb = BitConverter.GetBytes(c);//小端 Array.Reverse(cb);//反转成大端 //方法二 int c2 = IPAddress.HostToNetworkOrder(c);//大端字节数 byte[] bb = System.BitConverter.GetBytes(c2);//字节数组 //文本(Unicode) string s = "code"; byte[] sbb = Encoding.BigEndianUnicode.GetBytes(s);//大端 byte[] sbs = Encoding.Unicode.GetBytes(s);//小端
C++判断也简单,采用Union的方式判断,因为在Union中所有的元素都放在一块内存空间中,mu.c的内存地址是和int型的变量i的起始地址对齐的,所以改变int型的值mu.i=1,如果为小端存储,则mu.c==1,反之,则为大端存储。详细可以参考:http://blog.csdn.net/anialy/article/details/8015183
void checkSystemBigOrLittle(void)
{
typedef union MyUnion
{
int i;
char c;
};
MyUnion mu;
mu.i = 1;
if(mu.c == 1)
{
printf("小端存储模式");
}
else if (mu.c == 0)
{
printf("大端存储模式");
}
else
{
printf("很抱歉,出错了");
}
}上文是各种被大牛喷的结果,后来的童鞋们请打牢基础,被喷请自查…

相关文章推荐
- Android之使用Http协议实现文件上传功能
- C#实现将千分位字符串转换成数字的方法
- oracle SCN跟TIMESTAMP之间转换
- C#将制定目录文件名转换成大写的方法
- C#实现Stream与byte[]之间的转换实例教程
- 在VBS中定义字节数组Byte()介绍
- C#中结构体和字节数组转换实现
- C#进制之间的相互转换详解
- 自己动手把ACCESS转换到SQLSERVER的方法
- C#实现HSL颜色值转换为RGB的方法
- C#利用微软自带库进行中文繁体和简体之间转换的方法
- php将字符串转换成16进制的方法
- php使用Image Magick将PDF文件转换为JPG文件的方法
- php对象和数组相互转换的方法
- 解析PHP自带的进位制之间的转换函数
- php将12小时制转换成24小时制的方法
- PHP中把对象转换为关联数组代码分享
- C#实现毫秒转换成时分秒的方法
- C#实现将像素转换为页面单位的方法
- C#调用mmpeg进行各种视频转换的类实例