基于Corosync+Pacemaker+DRBD实现MySQL高可用集群
2015-06-11 23:17
956 查看
前言
在众多的高可用集群解决方案中,除了Heartbeat之外,Corosync也能提供类似于Heartbeat一样的功能,而且目前RedHat官方提供的高可用集群解决方案的程序包都以Corosync为主,所以在未来的日子Corosync会逐渐取代Heartbeat。本文带来的是基于Corosync + Pacemaker+DRBD的MySQL高可用集群解决方案。相关介绍
CorosyncCorosync是从OpenAIS中分支出来的一个项目,它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等。Corosync识别节点是通过authkey来实现的,不同于heartbeat v1 v2,Corosync的authkey是通过corosync-keygen命令生成的,具有更高的安全性。Corosync目前有两个主流的版本:v1和v2,两个版本差别较大,v1没有有投票功能,需要借助cman实现,v2支持投票功能。PacemakerPacemaker是从heartbeat v3版本中分裂出来专门用于管理高可用集群的组件,功能十分强大。它利用集群基础构件(OpenAIS 或heartbeat)提供的消息和成员管理能力来探测并从节点或资源级别的故障中恢复,以实现群集服务(亦称资源)的最大可用性。DRBD
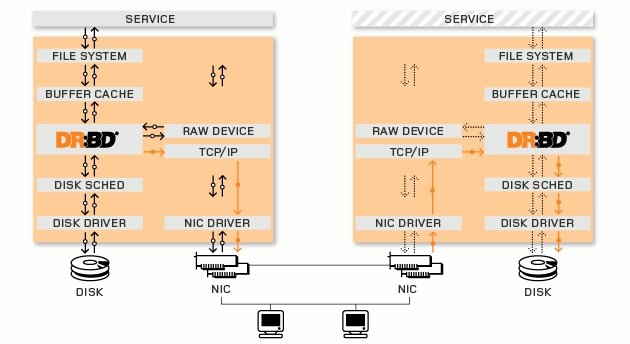
DRBD是由内核模块和相关脚本而构成,用以构建高可用性的集群。其实现方式是通过网络来镜像整个设备。可以把它看作是一种网络RAID。DRBD负责接收数据,把数据写到本地磁盘,然后发送给另一个主机,另一个主机再将数据存到自己的磁盘中。下面是DRBD的系统结构图
高可用解决方案
实验拓扑
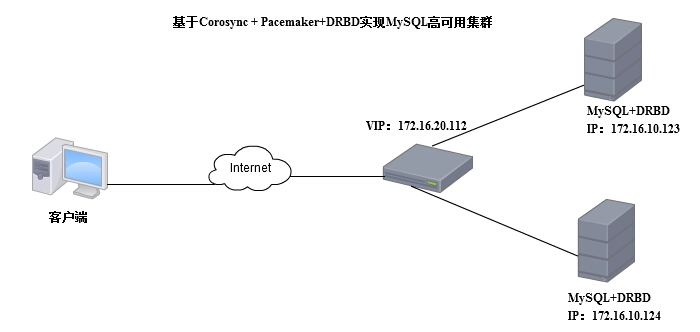
实验环境node1:172.16.10.123 MariaDB DRBD CentOS6.6
node2:172.16.10.124 MariaDB DRBD CentOS6.6VIP:192.168.1.121配置过程
配置HA的前提:时间同步、基于主机名互相通信、SSH互信请确保两个节点时间同步,可用ntpdate向时间服务器同步

安装mysql
准备DRBD分区

初始化资源并启动服务

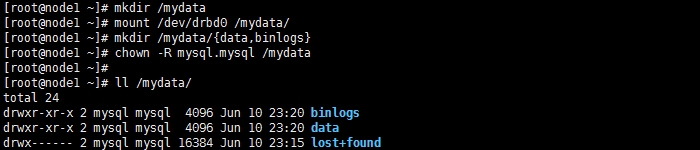
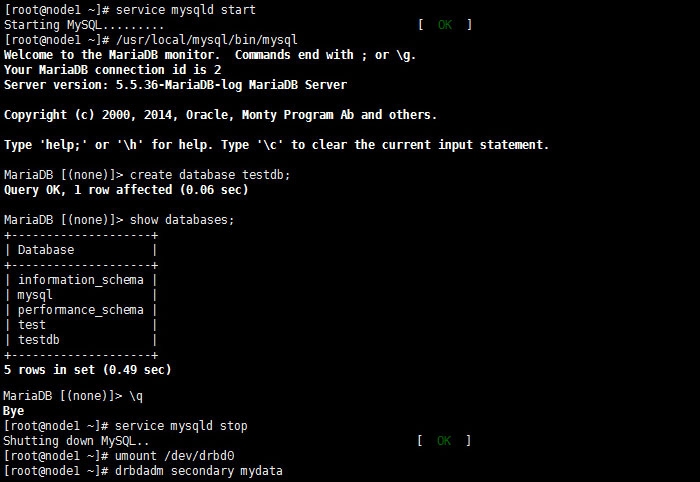
在另一个节点上测试

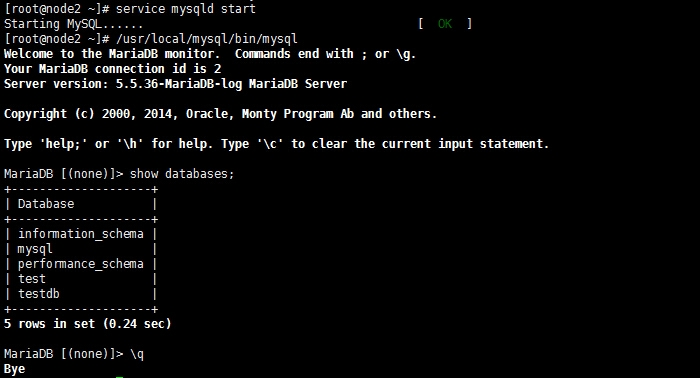
数据同步成功,接下来关闭所有服务

配置corosync资源,实现高可用定义DRBD资源

定义DRBD主从资源

定义mysql所需资源

定义组及各资源约束关系

查看所有资源信息

授权一个远程用户做测试
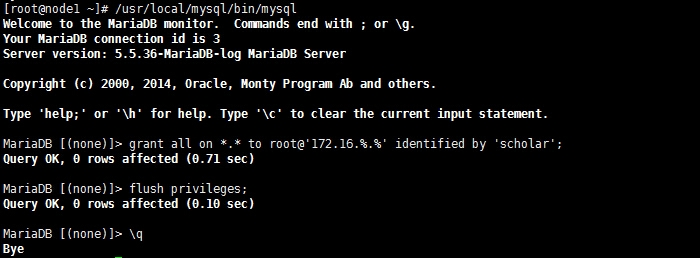
在其他主机登陆测试

此时模拟主节点故障
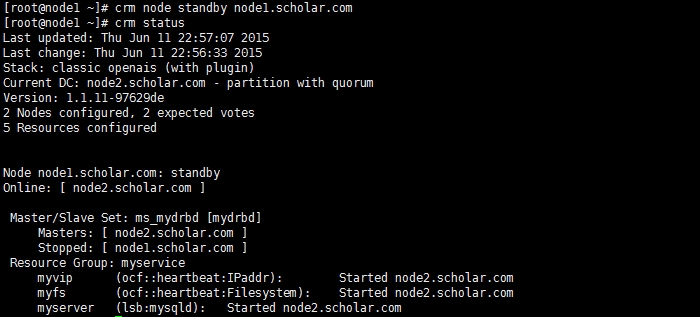
此时,资源被转移到了node2上,继续用远程主机登陆测试
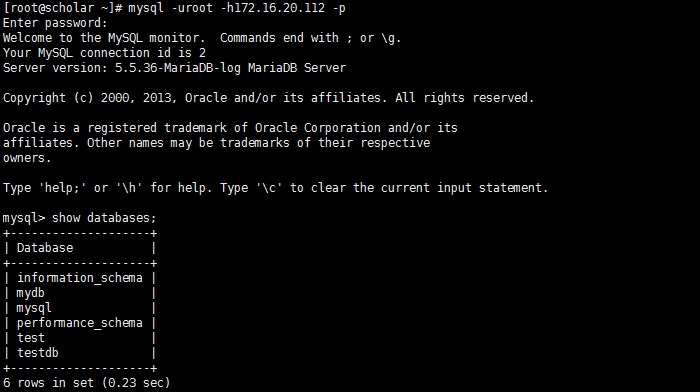
数据没有受到任何影响,高可用目的实现,至此,基于Corosync + Pacemaker+DRBD的MySQL高可用集群实验完成The end本次实验就进行到这里了,实验过程出现了一个奇葩问题,至今不知何故,朋友们如果配置过程中遇到问题欢迎留言交流。以上仅为个人学习整理,如有错漏,大神勿喷~~~
在众多的高可用集群解决方案中,除了Heartbeat之外,Corosync也能提供类似于Heartbeat一样的功能,而且目前RedHat官方提供的高可用集群解决方案的程序包都以Corosync为主,所以在未来的日子Corosync会逐渐取代Heartbeat。本文带来的是基于Corosync + Pacemaker+DRBD的MySQL高可用集群解决方案。相关介绍
CorosyncCorosync是从OpenAIS中分支出来的一个项目,它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等。Corosync识别节点是通过authkey来实现的,不同于heartbeat v1 v2,Corosync的authkey是通过corosync-keygen命令生成的,具有更高的安全性。Corosync目前有两个主流的版本:v1和v2,两个版本差别较大,v1没有有投票功能,需要借助cman实现,v2支持投票功能。PacemakerPacemaker是从heartbeat v3版本中分裂出来专门用于管理高可用集群的组件,功能十分强大。它利用集群基础构件(OpenAIS 或heartbeat)提供的消息和成员管理能力来探测并从节点或资源级别的故障中恢复,以实现群集服务(亦称资源)的最大可用性。DRBD
DRBD是由内核模块和相关脚本而构成,用以构建高可用性的集群。其实现方式是通过网络来镜像整个设备。可以把它看作是一种网络RAID。DRBD负责接收数据,把数据写到本地磁盘,然后发送给另一个主机,另一个主机再将数据存到自己的磁盘中。下面是DRBD的系统结构图
高可用解决方案
实验拓扑
实验环境node1:172.16.10.123 MariaDB DRBD CentOS6.6
node2:172.16.10.124 MariaDB DRBD CentOS6.6VIP:192.168.1.121配置过程
配置HA的前提:时间同步、基于主机名互相通信、SSH互信请确保两个节点时间同步,可用ntpdate向时间服务器同步
[root@node1 ~]# ntpdate cn.pool.ntp.org基于主机名互相通信
[root@node1 ~]# vim /etc/hosts 172.16.10.123 node1.scholar.com node1 172.16.10.124 node2.scholar.com node2 [root@node1 ~]# vim /etc/sysconfig/network HOSTNAME=node1.scholar.com [root@node1 ~]# uname -n node1.scholar.com #两个节点都需如上操作SSH互信
[root@node1 ~]# ssh-keygen -t rsa -P '' [root@node1 ~]# ssh-copy-id -i .ssh/id_rsa.pub root@node2 [root@node2 ~]# ssh-keygen -t rsa -P '' [root@node2 ~]# ssh-copy-id -i .ssh/id_rsa.pub root@node1 [root@node1 ~]# date; ssh node2 'date' #测试 Wed Jun 10 16:27:47 CST 2015 Wed Jun 10 16:27:47 CST 2015安装所需程序包
#安装corosync + pacemaker,pacemaker依赖于corosync,会一并安装 [root@node1 ~]# yum install pacemaker -y #安装pacemaker配置接口,crmsh依赖于pssh,单独安装需解决依赖关系,需suse官方源 [root@node1 ~]# yum install crmsh -y #安装drbd [root@node1 ~]# yum install gcc gcc-c++ glibc flex kernel-devel kernel-headers -y [root@node1 ~]# tar xf drbd-8.4.3.tar.gz [root@node1 ~]# cd drbd-8.4.3 [root@node1 drbd-8.4.3]# ./configure --prefix=/usr --sysconfdir=/etc --localstatedir=/var --with-km [root@node1 drbd-8.4.3]# make && make install [root@node1 drbd-8.4.3]# modprobe drbd #两个节点都执行以上操作Corosync配置修改配置文件
[root@node1 ~]# cd /etc/corosync/
[root@node1 corosync]# mv corosync.conf.example corosync.conf
[root@node1 corosync]# vim corosync.conf
# Please read the corosync.conf.5 manual page
compatibility: whitetank
totem { #心跳信息传递层
version: 2 #版本
secauth: on #认证信息
threads: 0 #线程
interface { #定义心跳信息传递的接口
ringnumber: 0
bindnetaddr: 172.16.0.0 #绑定的网络地址,写网络地址
mcastaddr: 226.94.1.1 #多播地址
mcastport: 5405 #多播的端口
ttl: 1 #生存周期
}
}
logging { #日志
fileline: off
to_stderr: no #是否输出在屏幕上
to_logfile: yes #定义自己的日志
to_syslog: no #是否由syslog记录日志
logfile: /var/log/cluster/corosync.log #日志文件的存放路径
debug: off
timestamp: on #是否开启时间戳
logger_subsys {
subsys: AMF
debug: off
}
}
amf {
mode: disabled
}
service {
ver: 0
name: pacemaker #pacemaker作为corosync的插件进行工作
}
aisexec {
user: root
group: root
}生成认证文件[root@node1 corosync]# corosync-keygen Corosync Cluster Engine Authentication key generator. Gathering 1024 bits for key from /dev/random. Press keys on your keyboard to generate entropy. Press keys on your keyboard to generate entropy (bits = 736). ########此时拼命敲键盘产生随机数###########将配置文件及认证文件同步给另一个节点
安装mysql
[root@node1 ~]# vim /etc/mysql/my.cnf datadir = /mydata/data log-bin=/mydata/binlogs/ #两个节点都执行以上操作DRBD配置
准备DRBD分区
[root@node1 ~]# fdisk sdb
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-2610, default 1):
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-2610, default 2610): +10G
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
[root@node1 ~]# partx -a /dev/sdb
#另一个节点也执行此操作修改配置文件[root@node1 ~]# vim /etc/drbd.d/global_common.conf
global {
usage-count no;
# minor-count dialog-refresh disable-ip-verification
}
common {
protocol C;
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/dr
bd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/dr
bd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-em
ergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15
-- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
startup {
#wfc-timeout 120;
#degr-wfc-timeout 120;
}
disk {
on-io-error detach;
#fencing resource-only;
}
net {
cram-hmac-alg "sha1";
shared-secret "mydrbdlab";
}
syncer {
rate 1000M;
}
}
[root@node1 ~]# vim /etc/drbd.d/mydata.res
#定义一个资源/etc/drbd.d/mydata.res,内容如下
resource mydata {
on node1 {
device /dev/drbd0;
disk /dev/sdb1;
address 172.16.10.123:7789;
meta-disk internal;
}
on node2 {
device /dev/drbd0;
disk /dev/sdb1;
address 172.16.10.124:7789;
meta-disk internal;
}
}将配置文件同步给另一个节点初始化资源并启动服务
[root@node1 ~]# drbdadm create-md mydata [root@node1 ~]# service drbd start #两个节点都要执行以上操作同步资源
#以上操作只在一个节点进行格式化DRBD分区
#以上操作只在一个节点执行挂载DRBD分区初始化数据库
[root@node1 ~]# /usr/local/mysql/scripts/mysql_install_db --user=mysql --datadir=/mydat a/data/ --basedir=/usr/local/mysql #初始化操作只执行一次即可测试数据是否同步
在另一个节点上测试
数据同步成功,接下来关闭所有服务
#另一个节点也关闭服务,确保开机不会自启
配置corosync资源,实现高可用定义DRBD资源
定义DRBD主从资源
定义mysql所需资源
定义组及各资源约束关系
查看所有资源信息
crm(live)configure# show node node1.scholar.com node node2.scholar.com primitive mydrbd ocf:linbit:drbd \ params drbd_resource=mydata \ op monitor role=Master interval=10s timeout=20s \ op monitor role=Slave interval=20s timeout=20s \ op start timeout=240s interval=0 \ op stop timeout=100s interval=0 primitive myfs Filesystem \ params device="/dev/drbd0" directory="/mydata" fstype=ext4 \ op monitor interval=20s timeout=60s \ op start timeout=60s interval=0 \ op stop timeout=60s interval=0 primitive myserver lsb:mysqld \ op monitor interval=30s timeout=20s primitive myvip IPaddr \ params ip=192.168.1.121 \ op monitor interval=30s timeout=20s group myservice myvip myfs myserver ms ms_mydrbd mydrbd \ meta master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true colocation myfs_with_ms_mydrbd_master inf: myfs ms_mydrbd:Master colocation myserver_with_myfs inf: myserver myfs order myfs_after_ms_mydrbd_master Mandatory: ms_mydrbd:promote myfs:start property cib-bootstrap-options: \ dc-version=1.1.11-97629de \ cluster-infrastructure="classic openais (with plugin)" \ expected-quorum-votes=2 \ stonith-enabled=false \ no-quorum-policy=ignore \ last-lrm-refresh=1434014581查看集群运行状态
授权一个远程用户做测试
在其他主机登陆测试
此时模拟主节点故障
此时,资源被转移到了node2上,继续用远程主机登陆测试
数据没有受到任何影响,高可用目的实现,至此,基于Corosync + Pacemaker+DRBD的MySQL高可用集群实验完成The end本次实验就进行到这里了,实验过程出现了一个奇葩问题,至今不知何故,朋友们如果配置过程中遇到问题欢迎留言交流。以上仅为个人学习整理,如有错漏,大神勿喷~~~

相关文章推荐
- MySQL中的integer 数据类型
- mysql中int、bigint、smallint 和 tinyint的区别与长度
- mysql load data 导出、导入 csv
- source命令执行SQL脚本文件
- linux下mysql添加用户
- mysql procedure
- mysql触发器
- Linux下高可用群集之corosync+openais+pacemaker+web+drbd
- MySQL 备份和恢复策略
- mac下安装mysql(转载)
- mysql 修改编码 Linux/Mac/Unix/通用(杜绝修改后无法启动的情况!)
- MySQL数据的导出、导入(mysql内部命令:mysqldump、mysql)
- mysql数据行转列
- Linux下修改MySQL编码的方法
- MySQL Server 日志
- MySQL 安全事宜
- MySQL 备份与恢复