索引键的唯一性(3/4):唯一聚集索引上的唯一和非唯一非聚集索引
2015-06-10 16:18
549 查看
原文:索引键的唯一性(3/4):唯一聚集索引上的唯一和非唯一非聚集索引在上篇文章里,我讨论了唯一和非唯一聚集索引的区别。我们已经知道,SQL Server内部使用4 bytes的uniquifier来保证非唯一聚集索引行唯一。今天我们来看下唯一聚集索引上,唯一和非唯一非聚集索引的区别。当我们在表上定义[b]PRIMARY KEY[/b]约束时,SQL Server会为我们创建唯一聚集索引;另外我们可以通过[b]CREATE UNIQUE CLUSTERED INDEX[/b]语句在表上创建唯一聚集索引。下面的代码会创建customers表,然后在它上面创建唯一聚集索引,最后在表上创建唯一和非唯一非聚集索引。
在2个非聚集索引创建后,我们可以使用DMV [b]sys.dm_db_index_physical_stats[/b]来查看索引的相关信息。

我们可以看到,唯一非聚集索引的记录长度是107 bytes,非唯一非聚集索引的记录长度是111 bytes。因此这2个索引的内部存储格式肯定不同。我们从唯一非聚集索引开始分析。
我们可以通过[b]DBCC IND[/b]命令找出索引根页,聚集索引的INDEX ID为1,非聚集索引的INDEX ID从2开始,依次递增,这里应该是2和3。
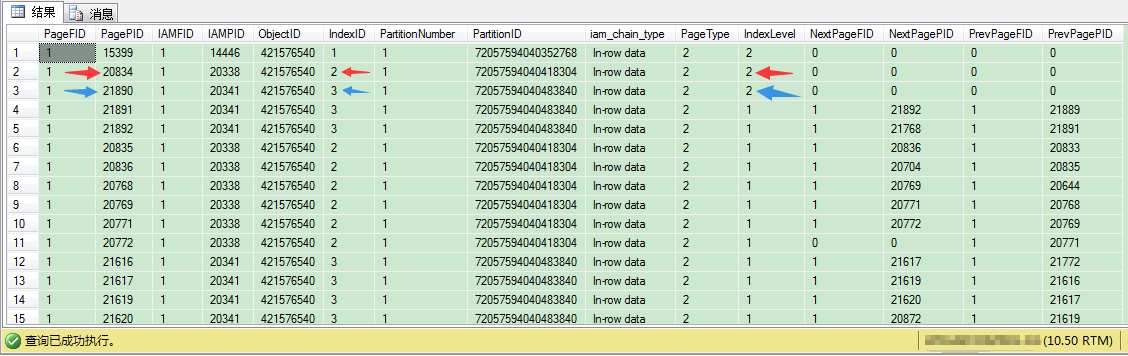
从这里我们可以看出,唯一非聚集索引的根页是20834,非唯一非聚集索引的根页是21890。
我们看下唯一非聚集索引的根页内容:
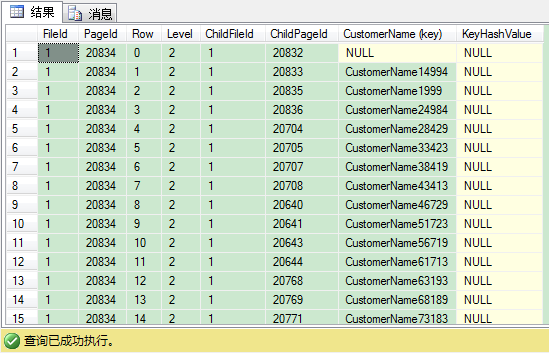
从图中我们可以看到,每条索引记录包含非聚集键(这里是唯一的)——即CustomerName列。
我们换参数1再来看看根页信息:
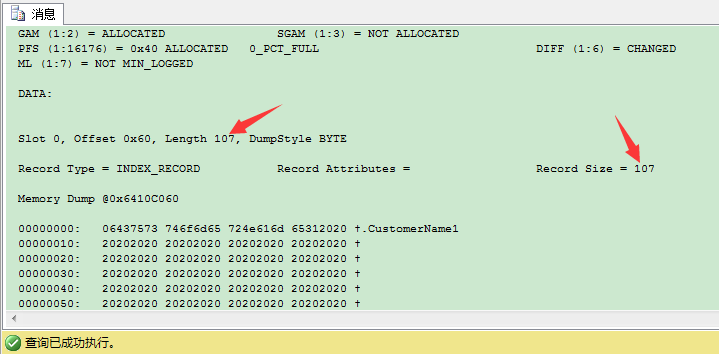
这里的107 bytes包含下列信息:
1 byte: 状态位
n bytes:非唯一聚集索引键——这里是CustomerName列,100 bytes
4 bytes:页ID(PageID)
2 bytes:文件ID(FileID)
在唯一非聚集索引里,所有非叶子层的每条索引记录都包含这107 bytes信息。因此,你的非聚集索引键大小会影响到每个索引页可以存储多少条索引记录。这样的话,这个例子的[b]CHAR(100),[/b]并不是一个很好的索引键。
我们继续往下看,索引叶子层的存储情况:
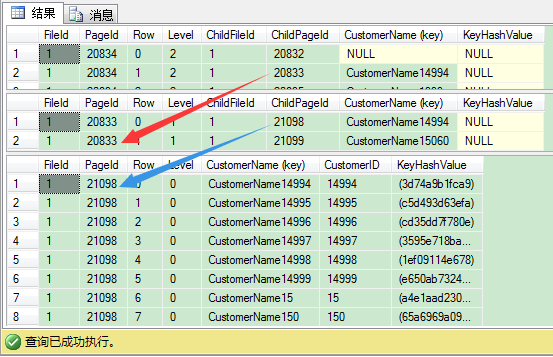
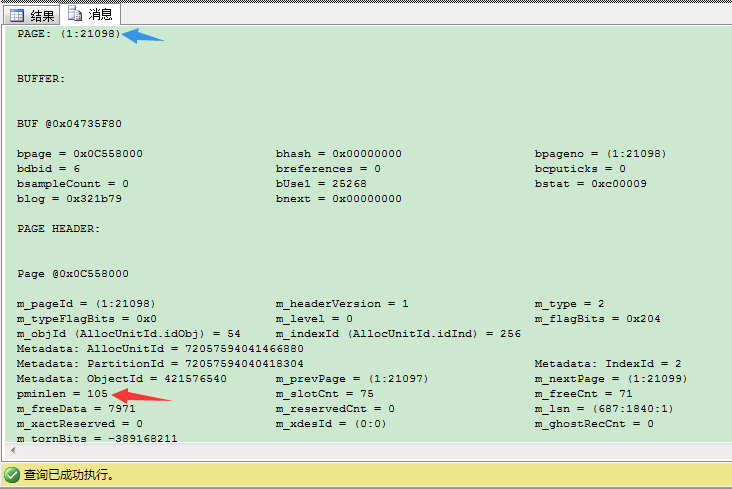
从图中我们可以看到,SQL Server在叶子层这里保存聚集键(即[b]CustomerID[/b]列的值)。这个值是SQL Server用来指向聚集索引里对应记录的指针。手上有了这个值,SQL Server就可以在聚集索引找到对应记录——通过[b]聚集索引查找(Clustered Index Seek)[/b]运算符。这和在堆表上定义的非聚集索引有重大区别。因为在堆表里,SQL Server使用叶子层的HEAP RID直接指向数据页里存储的对应记录。因此,SQL Server不用访问额外索引,就可以直接正确读取到数据页。
这也意味着SQL Server在堆表上通过非聚集索引找记录,比在聚集表上通过非聚集索引找记录快很多,因为SQL Server不需要执行额外的[b]聚集索引查找(Clustered Index Seek)[/b]运算符。因此在堆表上可以读取更少的页正确找到记录。当不要高估这个细节,想想在堆表通过使用非聚集索引,性能上可以有多少好处。事实上,SQL Server总是尽量把索引页放在缓存区管理器里,因此对于SQL Server来说,使用额外的[b]聚集索引查找(Clustered Index Seek)[/b]从聚集索引里找回记录,成本更低。
现在我们来分析下非唯一非聚集索引。先来看看根页:
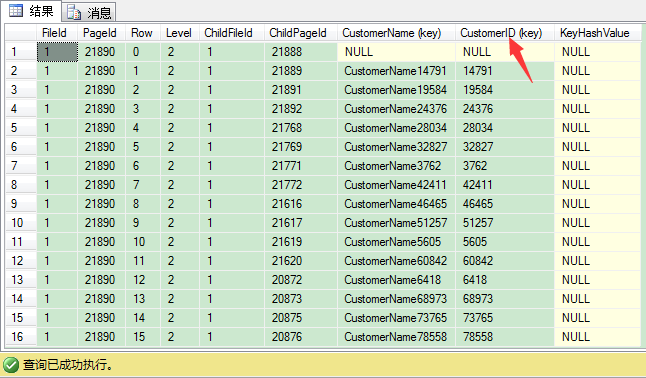
从上图可以看出,非唯一非聚集索引根页里,SQL Server这里保存里非聚集索引键和聚集索引键,这个和刚才的唯一聚集索引根页是不一样的。
SQL Server这里需要使用唯一聚集键来使非唯一非聚集索引键唯一。这在非唯一非聚集索引的[b]每一层[/b]都会保存,从索引根页到叶子层。这就是说你需要更多的存储空间来保存索引,因为SQL Server在[b]每条索引记录[/b]里不仅保存唯一聚集键,也保存非唯一非聚集索引键。因此当你选择不好的聚集键(像 [b]CHAR(100)[/b]等)时,情况会变得更糟。
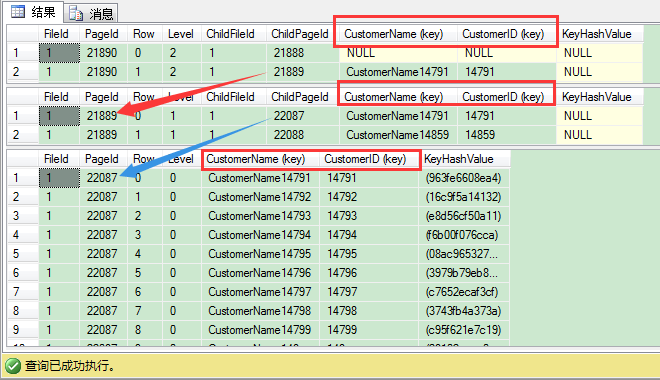
我们换参数1再来看看根页信息:
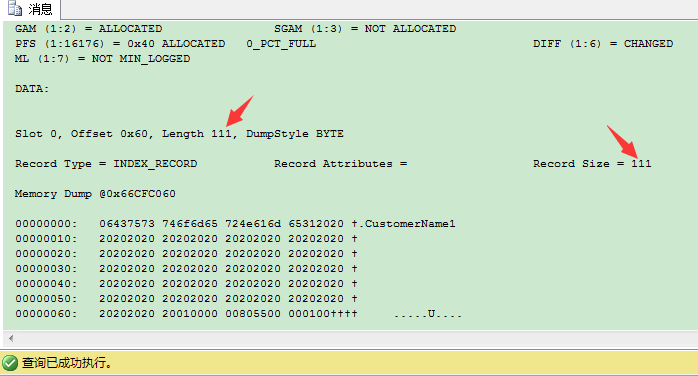
这111 bytes包括:
1 byte:状态位
n bytes:非唯一非聚集索引键——这里是CustomerName列,100 bytes
n bytes:唯一聚集索引键——这里是CustomerID列,4 bytes
4 bytes:页ID(PageID)
2 bytes:文件ID(FileID)
当你把这些字节长度汇总后,你就得到了刚才提到的111 bytes。因此在你创建非唯一非聚集索引时,就要考虑到这些额外存储,因为它会影响到你的非聚集索引的每一层。
在这个系列的下篇文章里,我们最后来看下在非唯一聚集索引上,唯一和非唯一非聚集索引的区别,请继续关注!
-- Create a table with 393 length + 7 bytes overhead = 400 bytes -- Therefore 20 records can be stored on one page (8.096 / 400) = 20,24 CREATE TABLE Customers ( CustomerID INT NOT NULL, CustomerName CHAR(100) NOT NULL, CustomerAddress CHAR(100) NOT NULL, Comments CHAR(189) NOT NULL ) GO -- Create a unique clustered index on the previous created table CREATE UNIQUE CLUSTERED INDEX idx_Customers ON Customers(CustomerID) GO -- Insert 80.000 records DECLARE @i INT = 1 WHILE (@i <= 80000) BEGIN INSERT INTO Customers VALUES ( @i, 'CustomerName' + CAST(@i AS CHAR), 'CustomerAddress' + CAST(@i AS CHAR), 'Comments' + CAST(@i AS CHAR) ) SET @i += 1 END GO -- Create a unique non clustered index on the clustered table CREATE UNIQUE NONCLUSTERED INDEX idx_UniqueNCI_CustomerID ON Customers(CustomerName) GO -- Create a non-unique non clustered index on the clustered table CREATE NONCLUSTERED INDEX idx_NonUniqueNCI_CustomerID ON Customers(CustomerName) GO
在2个非聚集索引创建后,我们可以使用DMV [b]sys.dm_db_index_physical_stats[/b]来查看索引的相关信息。
-- Retrieve physical information about the unique non-clustered index
SELECT * FROM sys.dm_db_index_physical_stats
(
DB_ID('ALLOCATIONDB'),
OBJECT_ID('Customers'),
2,
NULL,
'DETAILED'
)
GO
-- Retrieve physical information about the non-unique non-clustered index
SELECT * FROM sys.dm_db_index_physical_stats
(
DB_ID('ALLOCATIONDB'),
OBJECT_ID('Customers'),
3,
NULL,
'DETAILED'
)
GO我们可以看到,唯一非聚集索引的记录长度是107 bytes,非唯一非聚集索引的记录长度是111 bytes。因此这2个索引的内部存储格式肯定不同。我们从唯一非聚集索引开始分析。
我们可以通过[b]DBCC IND[/b]命令找出索引根页,聚集索引的INDEX ID为1,非聚集索引的INDEX ID从2开始,依次递增,这里应该是2和3。
TRUNCATE TABLE dbo.sp_table_pages
INSERT INTO dbo.sp_table_pages
EXEC('DBCC IND(ALLOCATIONDB, Customers, -1)')
SELECT * FROM dbo.sp_table_pages ORDER BY IndexLevel DESC从这里我们可以看出,唯一非聚集索引的根页是20834,非唯一非聚集索引的根页是21890。
我们看下唯一非聚集索引的根页内容:
DBCC PAGE(ALLOCATIONDB, 1, 20834, 3) GO
从图中我们可以看到,每条索引记录包含非聚集键(这里是唯一的)——即CustomerName列。
我们换参数1再来看看根页信息:
DBCC TRACEON(3604) DBCC PAGE(ALLOCATIONDB, 1, 20834, 1) GO
这里的107 bytes包含下列信息:
1 byte: 状态位
n bytes:非唯一聚集索引键——这里是CustomerName列,100 bytes
4 bytes:页ID(PageID)
2 bytes:文件ID(FileID)
在唯一非聚集索引里,所有非叶子层的每条索引记录都包含这107 bytes信息。因此,你的非聚集索引键大小会影响到每个索引页可以存储多少条索引记录。这样的话,这个例子的[b]CHAR(100),[/b]并不是一个很好的索引键。
我们继续往下看,索引叶子层的存储情况:
DBCC PAGE(ALLOCATIONDB, 1, 20834, 3)--根层 GO DBCC PAGE(ALLOCATIONDB, 1, 20833, 3)--中间层 GO DBCC PAGE(ALLOCATIONDB, 1, 21098, 3)--叶子层 GO
从图中我们可以看到,SQL Server在叶子层这里保存聚集键(即[b]CustomerID[/b]列的值)。这个值是SQL Server用来指向聚集索引里对应记录的指针。手上有了这个值,SQL Server就可以在聚集索引找到对应记录——通过[b]聚集索引查找(Clustered Index Seek)[/b]运算符。这和在堆表上定义的非聚集索引有重大区别。因为在堆表里,SQL Server使用叶子层的HEAP RID直接指向数据页里存储的对应记录。因此,SQL Server不用访问额外索引,就可以直接正确读取到数据页。
这也意味着SQL Server在堆表上通过非聚集索引找记录,比在聚集表上通过非聚集索引找记录快很多,因为SQL Server不需要执行额外的[b]聚集索引查找(Clustered Index Seek)[/b]运算符。因此在堆表上可以读取更少的页正确找到记录。当不要高估这个细节,想想在堆表通过使用非聚集索引,性能上可以有多少好处。事实上,SQL Server总是尽量把索引页放在缓存区管理器里,因此对于SQL Server来说,使用额外的[b]聚集索引查找(Clustered Index Seek)[/b]从聚集索引里找回记录,成本更低。
现在我们来分析下非唯一非聚集索引。先来看看根页:
DBCC PAGE(ALLOCATIONDB, 1, 21890, 3) GO
从上图可以看出,非唯一非聚集索引根页里,SQL Server这里保存里非聚集索引键和聚集索引键,这个和刚才的唯一聚集索引根页是不一样的。
SQL Server这里需要使用唯一聚集键来使非唯一非聚集索引键唯一。这在非唯一非聚集索引的[b]每一层[/b]都会保存,从索引根页到叶子层。这就是说你需要更多的存储空间来保存索引,因为SQL Server在[b]每条索引记录[/b]里不仅保存唯一聚集键,也保存非唯一非聚集索引键。因此当你选择不好的聚集键(像 [b]CHAR(100)[/b]等)时,情况会变得更糟。
DBCC PAGE(ALLOCATIONDB, 1, 21890, 3)--根层 GO DBCC PAGE(ALLOCATIONDB, 1, 21889, 3)--中间层 GO DBCC PAGE(ALLOCATIONDB, 1, 22087, 3)--叶子层 GO
我们换参数1再来看看根页信息:
DBCC TRACEON(3604) DBCC PAGE(ALLOCATIONDB, 1, 21890, 1) GO
这111 bytes包括:
1 byte:状态位
n bytes:非唯一非聚集索引键——这里是CustomerName列,100 bytes
n bytes:唯一聚集索引键——这里是CustomerID列,4 bytes
4 bytes:页ID(PageID)
2 bytes:文件ID(FileID)
当你把这些字节长度汇总后,你就得到了刚才提到的111 bytes。因此在你创建非唯一非聚集索引时,就要考虑到这些额外存储,因为它会影响到你的非聚集索引的每一层。
在这个系列的下篇文章里,我们最后来看下在非唯一聚集索引上,唯一和非唯一非聚集索引的区别,请继续关注!

相关文章推荐
- 索引键的唯一性(2/4):唯一与非唯一聚集索引
- 用Go语言做产品半年的一些感觉
- ZeroMQ的进阶
- 2-3 矢量格式图像-1-4
- mysql 不能对同一个表进行 update(delete) 和 select 联合操作
- NSString
- win2008 R2 64位系统下配置DCOM权限
- GRE逻辑写作解析
- cocos2.x cocos3.x创建命令
- Java 面试题
- 【工具使用】secureCRT中的中文乱码问题
- hdoj 1695 GCD 【容斥原理 + 欧拉函数】 【求两个区间里面的所有不重复质数对】
- lvs+keepalived+nginx (httpd)部署
- shell 各种循环判断
- 系统服务之蓝牙
- 打Android渠道包简易脚本
- ZOJ2006 (后缀自动机)
- MSM RF Driver Configuration
- [Python]网络爬虫(四):Opener与Handler的介绍和实例应用
- message queue & event loop