hadoop学习笔记(1)
2015-06-02 20:40
190 查看
1.inputformat()和inputsplit
2.outputFormat()
3.Map(输入Key,输入Value,输出Key,输出value)
4.Reduce()
用Map()类推
5.context对象
使用MapContext进行MapReduce间的通信充当OutputCollector和Reporter的角色
6.job的配置
统一由Configurartion来完成。
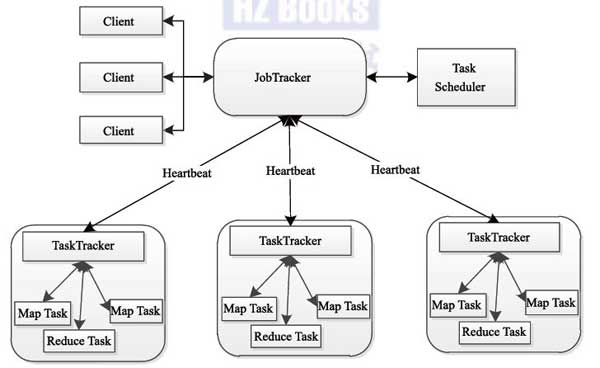
控制流:负责控制和调度Mapreduce的job的是jobTracker,负责运行的是TaskTracker(Map Task和Reduce Task)不是一个完整的job,即:jobTracker调度任务给TaskTracker,TaskTracker执行任务,返回调度结果。
数据流:数据经过inputformat处理生产相应数目的inputsplit,输入到Map中,Map读取inputsplit指定位置的数据,按照设定的方式处理数据,最后写到指定位置(如:本地磁盘),reduce读取map输出的数据,合并value,然后输出到HDFS上
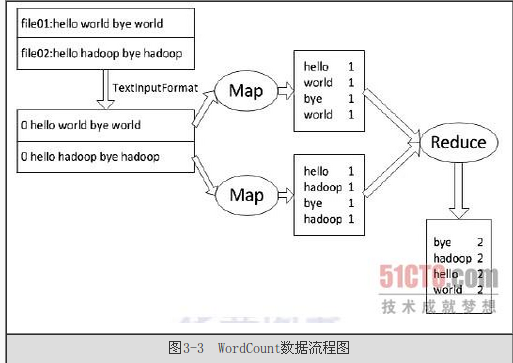
~format():用来生产供Map使用的 <key,value>(调用getRecord()方法生产RecordReader,RecordReader再通过creatKey()和creatValue(创建<key,value>) ~split:存储和把输入的数据(分片长度和一个记录数据位置的数组)传送给每一个单独的Map(可以通过inputformat()来设置)。
2.outputFormat()
对于每种输入格式都有一种输出格式与其对应。
3.Map(输入Key,输入Value,输出Key,输出value)
接收经过inputformat处理的<k1,v1>输出<k2,v2> 继承Maper抽象类,四个类型的参数
4.Reduce()
用Map()类推
5.context对象
使用MapContext进行MapReduce间的通信充当OutputCollector和Reporter的角色
6.job的配置
统一由Configurartion来完成。
控制流:负责控制和调度Mapreduce的job的是jobTracker,负责运行的是TaskTracker(Map Task和Reduce Task)不是一个完整的job,即:jobTracker调度任务给TaskTracker,TaskTracker执行任务,返回调度结果。
数据流:数据经过inputformat处理生产相应数目的inputsplit,输入到Map中,Map读取inputsplit指定位置的数据,按照设定的方式处理数据,最后写到指定位置(如:本地磁盘),reduce读取map输出的数据,合并value,然后输出到HDFS上

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 单机版搭建Hadoop环境图文教程详解
- hadoop常见错误以及处理方法详解
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- Apache Hadoop版本详解
- linux下搭建hadoop环境步骤分享
- hadoop client与datanode的通信协议分析
- hadoop中一些常用的命令介绍
- Hadoop单机版和全分布式(集群)安装
- 用PHP和Shell写Hadoop的MapReduce程序
- hadoop map-reduce中的文件并发操作
- Hadoop1.2中配置伪分布式的实例
- java结合HADOOP集群文件上传下载
- 用python + hadoop streaming 分布式编程(一) -- 原理介绍,样例程序与本地调试
- Hadoop安装感悟
- hadoop安装lzo