hiho一下 第四十八周
2015-05-31 17:17
274 查看
题目名称:拓扑排序·二
题目链接:http://hihocoder.com/contest/hiho48/problem/1
小Hi和小Ho所在学校的校园网被黑客入侵并投放了病毒。这事在校内BBS上立刻引起了大家的讨论,当然小Hi和小Ho也参与到了其中。从大家各自了解的情况中,小Hi和小Ho整理得到了以下的信息:
校园网主干是由N个节点(编号1..N)组成,这些节点之间有一些单向的网路连接。若存在一条网路连接(u,v)链接了节点u和节点v,则节点u可以向节点v发送信息,但是节点v不能通过该链接向节点u发送信息。
在刚感染病毒时,校园网立刻切断了一些网络链接,恰好使得剩下网络连接不存在环,避免了节点被反复感染。也就是说从节点i扩散出的病毒,一定不会再回到节点i。
当1个病毒感染了节点后,它并不会检查这个节点是否被感染,而是直接将自身的拷贝向所有邻居节点发送,它自身则会留在当前节点。所以一个节点有可能存在多个病毒。
现在已经知道黑客在一开始在K个节点上分别投放了一个病毒。
举个例子,假设切断部分网络连接后学校网络如下图所示,由4个节点和4条链接构成。最开始只有节点1上有病毒。
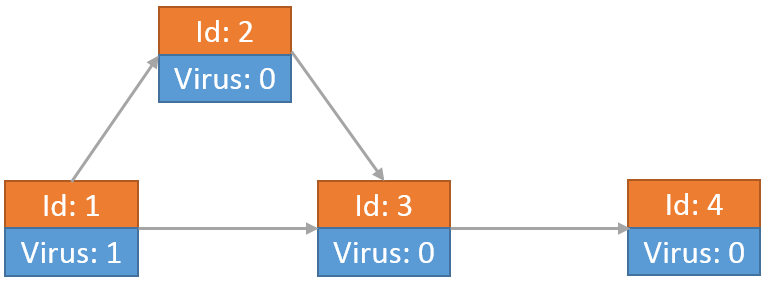
最开始节点1向节点2和节点3传送了病毒,自身留有1个病毒:
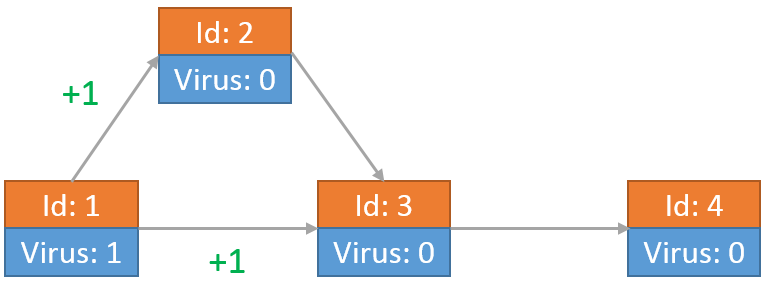
其中一个病毒到达节点2后,向节点3传送了一个病毒。另一个到达节点3的病毒向节点4发送自己的拷贝:
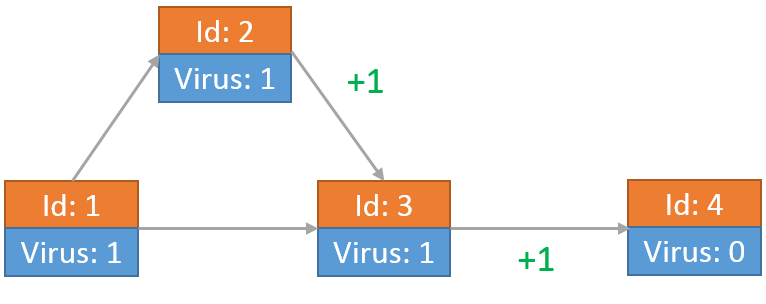
当从节点2传送到节点3的病毒到达之后,该病毒又发送了一份自己的拷贝向节点4。此时节点3上留有2个病毒:
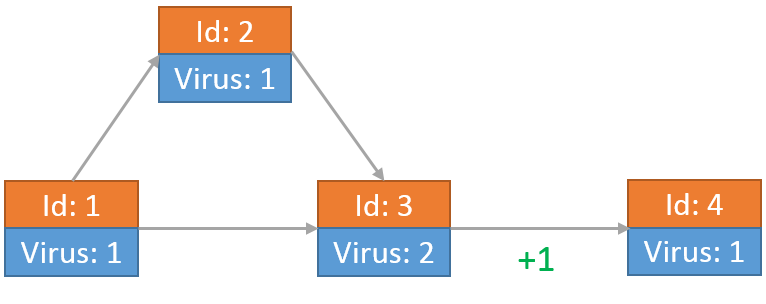
最后每个节点上的病毒为:
小Hi和小Ho根据目前的情况发现一段时间之后,所有的节点病毒数量一定不会再发生变化。那么对于整个网络来说,最后会有多少个病毒呢?
提示:拓扑排序的应用
第1行:3个整数N,M,K,1≤K≤N≤100,000,1≤M≤500,000
第2行:K个整数A[i],A[i]表示黑客在节点A[i]上放了1个病毒。1≤A[i]≤N
第3..M+2行:每行2个整数 u,v,表示存在一条从节点u到节点v的网络链接。数据保证为无环图。1≤u,v≤N
第1行:1个整数,表示最后整个网络的病毒数量 MOD 142857
样例输入
样例输出
小Hi:对于这个问题小Ho你有什么想法么?
小Ho:有,对于一个病毒来说它总会传递到一个没有邻居的节点,那我直接使用dfs模拟整个过程不就能够得到结果了吗?
小Hi:小Ho你真聪明,立刻就看穿了这个问题的本质。
小Ho:那当然啦。<得意>
小Hi:那么小Ho,我这里有这样一个网络:

这里一共有n个节点,对于节点i,它总是连接着节点i+1和节点i+2。一开始只有节点1被感染,你算算最后n个节点一共有多少个病毒?
小Ho:很显然,节点1最后只有1个病毒;节点2也只有1个病毒;节点3会接受从节点1和节点2过来的病毒,所以有2个病毒;后面依次是节点4有3个病毒,节点5有5个病毒…它们好像刚好是费波拉契数列?
小Hi:你说的没错。对于这个网络,编号为i的节点最后感染的病毒数量就是斐波拉契数列的第i项。而斐波拉契数列的增长是很惊人的,当i到达一定值时,其电脑感染的病毒数量就会很大了。
小Ho:那这又有什么关系呢?反正能得到解不是么?
小Hi:能得到解那是当然了,但是你有想过需要花费多少时间么?在你的dfs算法中,每一次进入函数就等于模拟一个病毒进入电脑。如果最后结果有10亿个病毒,那么你就需要执行10亿次函数,假设电脑每秒钟可以执行1亿次函数,那么你的dfs就需要运行10秒。如果结果有100亿,1000亿呢?
小Ho:运行时间上好像是有问题,那我应该如何解决时间的问题呢?
小Hi:其实也很简单啦。你再想想,在我们最后得到结果上每各节点病毒数量有什么关系么?
小Ho:嗯<思考>…我发现了!对于节点i来说,它最后的病毒数好像总是等于所有能够达到它的节点病毒数之和。就用你提到的那个斐波拉契数列来说,能够达到节点i的节点是节点i-1和节点i-2,所以节点i的病毒数是节点i-1和节点i-2的病毒数之和。这刚好就是斐波拉契数列的递推公式嘛!
小Hi:对,正是这样。对于一个节点i来说,如果我们能够先计算出它所有前驱节点的病毒数量,就可以直接推算出它最后的病毒数量了。
小Ho:但是怎么来计算所有前驱节点呢?
小Hi:这就要从图的性质入手了。我们现在的网络是没有环的,对于任意一个节点i,当它将自己所有的病毒都传送出去之后,它自身的病毒数量就不会改变了。那么我们不妨从没有前驱节点,也就是入度为0的节点开始考虑。
对于这些节点,它并不会再增加病毒数量。那么我们就根据它所关联的连接将病毒分发出去,然后这个节点就没有作用了。那不妨就删掉好了,它所关联的边也删掉。
这样图中又会产生一些新的没有入度的节点。这样一直删点,直到所有的点都被删掉,将所有点的病毒数量加起来不就是总的病毒数么?
我们不妨来看个例子,这里给定一个网络:
最开始只有节点1是入度为0的点,所以将它的病毒传送,然后删掉节点1:
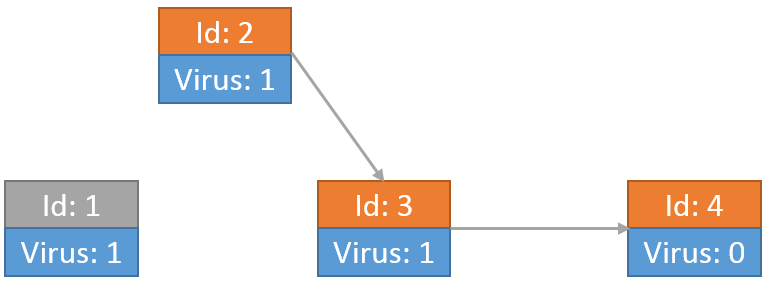
此时节点2成为了入度为0的点,同样将其删掉:
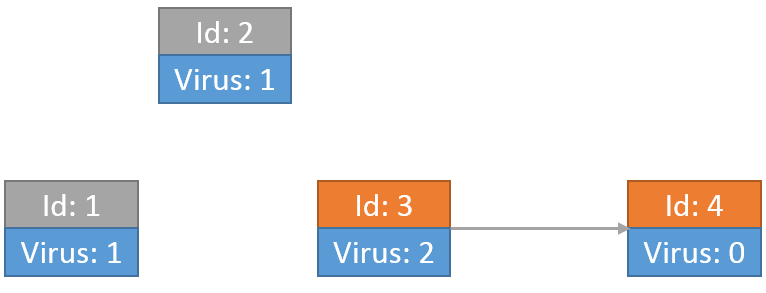
此时节点3为入度为0的点,同样操作:

最后只剩下节点4,因为它并没有后续节点,所以病毒感染的过程也就结束了。
小Ho:这不就是拓扑排序么!因为拓扑排序可以在O(n+m)的时间解决,整个问题的时间也减少到了O(n+m),那么再多的节点数都不怕了!
小Hi:没错,这样我们就完美地解决了这个问题。你能实现它么?
小Ho:没问题,就交给我吧!<自信>
思路:原题提示中已经说的很清楚了,不过得注意下中间相加的量可能溢出int
代码如下:
题目链接:http://hihocoder.com/contest/hiho48/problem/1
描述
小Hi和小Ho所在学校的校园网被黑客入侵并投放了病毒。这事在校内BBS上立刻引起了大家的讨论,当然小Hi和小Ho也参与到了其中。从大家各自了解的情况中,小Hi和小Ho整理得到了以下的信息:校园网主干是由N个节点(编号1..N)组成,这些节点之间有一些单向的网路连接。若存在一条网路连接(u,v)链接了节点u和节点v,则节点u可以向节点v发送信息,但是节点v不能通过该链接向节点u发送信息。
在刚感染病毒时,校园网立刻切断了一些网络链接,恰好使得剩下网络连接不存在环,避免了节点被反复感染。也就是说从节点i扩散出的病毒,一定不会再回到节点i。
当1个病毒感染了节点后,它并不会检查这个节点是否被感染,而是直接将自身的拷贝向所有邻居节点发送,它自身则会留在当前节点。所以一个节点有可能存在多个病毒。
现在已经知道黑客在一开始在K个节点上分别投放了一个病毒。
举个例子,假设切断部分网络连接后学校网络如下图所示,由4个节点和4条链接构成。最开始只有节点1上有病毒。
最开始节点1向节点2和节点3传送了病毒,自身留有1个病毒:
其中一个病毒到达节点2后,向节点3传送了一个病毒。另一个到达节点3的病毒向节点4发送自己的拷贝:
当从节点2传送到节点3的病毒到达之后,该病毒又发送了一份自己的拷贝向节点4。此时节点3上留有2个病毒:
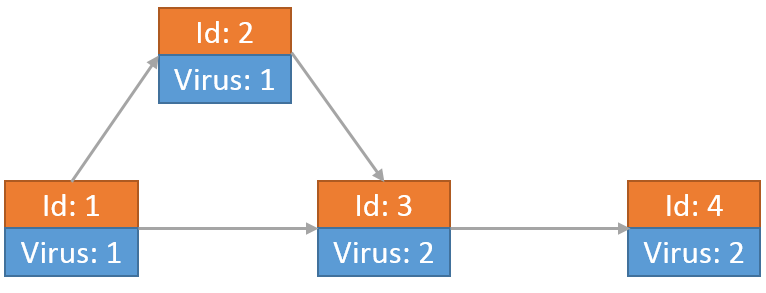
最后每个节点上的病毒为:
小Hi和小Ho根据目前的情况发现一段时间之后,所有的节点病毒数量一定不会再发生变化。那么对于整个网络来说,最后会有多少个病毒呢?
提示:拓扑排序的应用
输入
第1行:3个整数N,M,K,1≤K≤N≤100,000,1≤M≤500,000第2行:K个整数A[i],A[i]表示黑客在节点A[i]上放了1个病毒。1≤A[i]≤N
第3..M+2行:每行2个整数 u,v,表示存在一条从节点u到节点v的网络链接。数据保证为无环图。1≤u,v≤N
输出
第1行:1个整数,表示最后整个网络的病毒数量 MOD 142857样例输入
4 4 1 1 1 2 1 3 2 3 3 4
样例输出
6
提示:拓扑排序的应用
小Hi:对于这个问题小Ho你有什么想法么?小Ho:有,对于一个病毒来说它总会传递到一个没有邻居的节点,那我直接使用dfs模拟整个过程不就能够得到结果了吗?
小Hi:小Ho你真聪明,立刻就看穿了这个问题的本质。
小Ho:那当然啦。<得意>
小Hi:那么小Ho,我这里有这样一个网络:
这里一共有n个节点,对于节点i,它总是连接着节点i+1和节点i+2。一开始只有节点1被感染,你算算最后n个节点一共有多少个病毒?
小Ho:很显然,节点1最后只有1个病毒;节点2也只有1个病毒;节点3会接受从节点1和节点2过来的病毒,所以有2个病毒;后面依次是节点4有3个病毒,节点5有5个病毒…它们好像刚好是费波拉契数列?
小Hi:你说的没错。对于这个网络,编号为i的节点最后感染的病毒数量就是斐波拉契数列的第i项。而斐波拉契数列的增长是很惊人的,当i到达一定值时,其电脑感染的病毒数量就会很大了。
小Ho:那这又有什么关系呢?反正能得到解不是么?
小Hi:能得到解那是当然了,但是你有想过需要花费多少时间么?在你的dfs算法中,每一次进入函数就等于模拟一个病毒进入电脑。如果最后结果有10亿个病毒,那么你就需要执行10亿次函数,假设电脑每秒钟可以执行1亿次函数,那么你的dfs就需要运行10秒。如果结果有100亿,1000亿呢?
小Ho:运行时间上好像是有问题,那我应该如何解决时间的问题呢?
小Hi:其实也很简单啦。你再想想,在我们最后得到结果上每各节点病毒数量有什么关系么?
小Ho:嗯<思考>…我发现了!对于节点i来说,它最后的病毒数好像总是等于所有能够达到它的节点病毒数之和。就用你提到的那个斐波拉契数列来说,能够达到节点i的节点是节点i-1和节点i-2,所以节点i的病毒数是节点i-1和节点i-2的病毒数之和。这刚好就是斐波拉契数列的递推公式嘛!
小Hi:对,正是这样。对于一个节点i来说,如果我们能够先计算出它所有前驱节点的病毒数量,就可以直接推算出它最后的病毒数量了。
小Ho:但是怎么来计算所有前驱节点呢?
小Hi:这就要从图的性质入手了。我们现在的网络是没有环的,对于任意一个节点i,当它将自己所有的病毒都传送出去之后,它自身的病毒数量就不会改变了。那么我们不妨从没有前驱节点,也就是入度为0的节点开始考虑。
对于这些节点,它并不会再增加病毒数量。那么我们就根据它所关联的连接将病毒分发出去,然后这个节点就没有作用了。那不妨就删掉好了,它所关联的边也删掉。
这样图中又会产生一些新的没有入度的节点。这样一直删点,直到所有的点都被删掉,将所有点的病毒数量加起来不就是总的病毒数么?
我们不妨来看个例子,这里给定一个网络:
最开始只有节点1是入度为0的点,所以将它的病毒传送,然后删掉节点1:
此时节点2成为了入度为0的点,同样将其删掉:
此时节点3为入度为0的点,同样操作:
最后只剩下节点4,因为它并没有后续节点,所以病毒感染的过程也就结束了。
小Ho:这不就是拓扑排序么!因为拓扑排序可以在O(n+m)的时间解决,整个问题的时间也减少到了O(n+m),那么再多的节点数都不怕了!
小Hi:没错,这样我们就完美地解决了这个问题。你能实现它么?
小Ho:没问题,就交给我吧!<自信>
思路:原题提示中已经说的很清楚了,不过得注意下中间相加的量可能溢出int
代码如下:
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
#include<vector>
#include<stack>
using namespace std;
vector<int> vis[100005];
/*struct jd
{
int bd;
int d;
jd(int x=0,int y=0):bd(x),d(y){}
};*/
int main()
{
int n,m,k;
int a[100005],d[100005];
while(scanf("%d%d%d",&n,&m,&k)!=EOF)
{
memset(d,0,sizeof(d));
memset(a,0,sizeof(a));
for(int i=1;i<100002;i++)
vis[i].clear();
int s=0,sum=0;
for(int i=1;i<=k;i++)
{
scanf("%d",&s);
a[s]++;
}
for(int i=1;i<=m;i++)
{
int u,v;
scanf("%d%d",&u,&v);
vis[u].push_back(v);
d[v]++;
}
stack<int> q;
for(int i=1;i<=n;i++)
{
if(d[i]==0)
q.push(i);
}
while(!q.empty())
{
int f=q.top();
q.pop();
sum=(sum+a[f])%142857;
// cout<<a[f]<<endl;
for(int i=0;i<vis[f].size();i++)
{
int& h=vis[f][i];
// cout<<f<<endl;
d[h]--;
if(d[h]==0)
q.push(h);
a[h]=(a[h]+a[f])%142857;
}
}
printf("%d\n",sum%142857);
}
return 0;
}

相关文章推荐
- uml精粹——8.部署图 & 9.用例
- 如何不通过maven或者ant将项目打包成可执行的Jar包
- Freemarker-数字默认格式化问题
- 连载《一个程序猿的生命周期》-19.工作7年,对做技术的一点感悟和理解
- 数组转变成键值一维数组
- 通讯录(C语言、文件保存)
- poj 1700 Crossing River 【贪心】
- eclipse自动代码提示
- vim自动补全插件YouCompleteMe的安装及配置
- 周末闲着无聊分享一个自己写的带呼吸效果的android水波纹自定义view
- 数据库逆向框架代码生成工具:MyBatis Generator的使用
- HDU 2022 海选女主角
- Spring2.5学习2.4_Spring如何装配各种集合类的属性
- 服务端数据库的操作如何不阻塞
- ExtJs4.2示例中infinite-scroll出现PageMap asked for range which it does not have错误及解决
- Python学习之四sys.argv
- Lucene基础(四)-- 结合数据库使用
- cannot resolve getAttribute(java.lang.String)问题的解决
- 连载《一个程序员的成长历程》-19.工作7年,对做技术的一点感悟和理解
- 小火箭案例