自学抓去淘女郎所有模特美女的图片 手稿
2015-05-31 09:19
429 查看
摘要: 转行IT,自学python,淘女郎所有模特美女的图片,以模特名字建立文件名称,把对应的网站写入对应文件夹内。新手写代码,大神随便喷,感谢前辈的支持!
在百度传课上看到抓淘女郎模特照片,我看的免费视频没有看到抓去所有的图片,所以自己用刚学到的知识,把完整。
1,代码完成,抓到的最终效果如下:
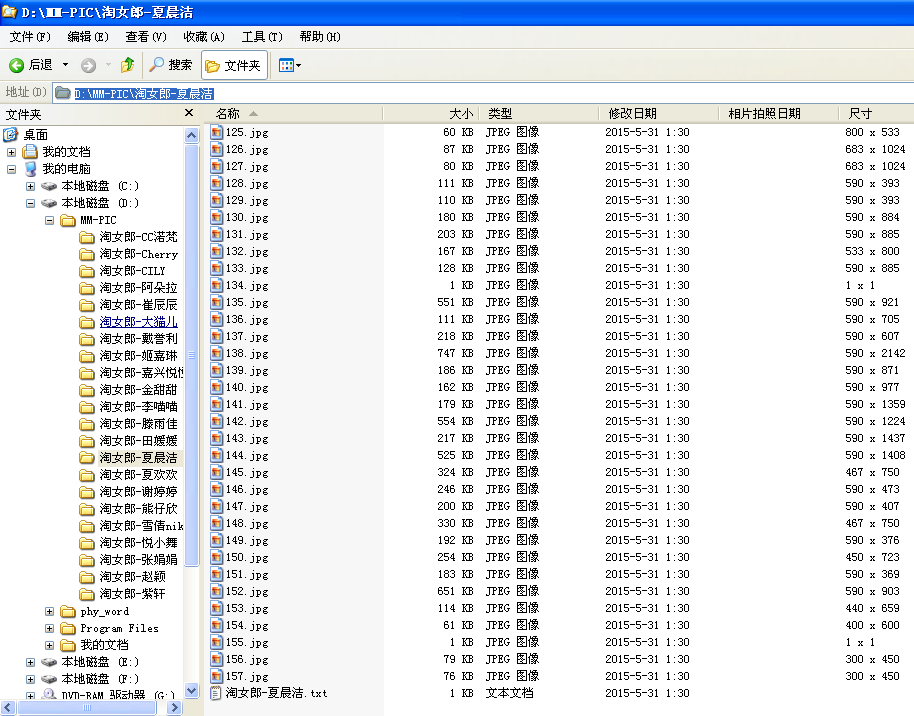
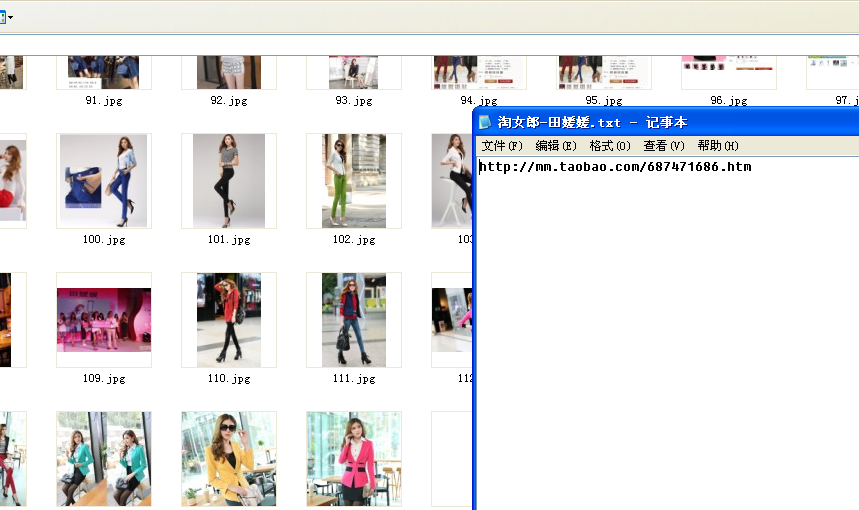
开始写代码:
1,分析网页:
http://mm.taobao.com/json/request_top_list.htm?type=0&page= 这个page=1到page=4000都可以。由于找不到上一层网页,所以没办法判断具体的页数是多少。
我的解决办法是新建文件夹的时候,由于出现同样的模特名字的文件,所以抓取会自动报错和停止
2,主代码:
--------------------------------------------------------------------------
i=1
mmurl='http://mm.taobao.com/json/request_top_list.htm?type=0&page='
while i<5:
url=mmurl+str(i) #得到网站地址
cont=urlcont(url) #得到第一页内容
t=getHrefs(cont) #找到第一页美女网站地址列表
y=getImgSrcs(t) #找到图片地址,并存档到对应文件夹内
i+=1
print'理论上下载图片张数:%s' %y
----------------------------------------------------------------------
这里我值设置了抓去前4页面的模特的代码,共40个模特,0页面和1页面是相同的。貌似是个无限循环啊。(后面可以把模特名字作比较,判断是否可以break,由于我没有抓到最后一页,4000X10X120张图片,我的硬盘估没了,所有没打算写break).下面的代码都是按顺序接着来的,不要在乎我这个新手的奇怪命名哦。
------------------------------------------------------------------------
#-*- coding: gbk -*-
import sys
import urllib2
import re
import os
from xinbuxing import Creatnewtxt
def urlcont(url):
up=urllib2.urlopen(url)
cont=up.read()
print cont
return cont #获得内容
----------------------------------------------------------------------
函数urlcont(),定义了打开,并阅读网页源代码。
有一点必须说明,cont有时候会变成淘宝的登入页面,不知道是反爬还是规定需要上线时间怎么的。遇到这种情况一般隔着6分钟在运行就可以了。
---------------------------------------------------------------------------
def getHrefs(cont):
re1=r'a href="(http:.*\.htm)" target'
c=re.compile(re1)
urlLists=re.findall(c,cont)
print '美女主页列表:%s' %urlLists
print '美女主页张数:%s' %len(urlLists)
print'\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\'
return urlLists #美女所有网站地列表
-----------------------------------------------------------------------------------
定义getHrefs(),来获得美女们的网网址
------------------------------------------------------------------------------------
def getName(cont):
name=[]
head=cont.find('<title>')
tail=cont.find('</title>',head+1)
c=cont[head+7:tail]
s=c.replace(' ', '')
#print s
return s
-------------------------------------------------------------------------
如果你仔细看模特网页的源代码,会发现<title>淘女郎 - 尹明月 </title>,我这个正则就是要“淘女郎 - 尹明月。这个函数就是获得模特的名字。下面是最重要的部分了
--------------------------------------------------------------------------------
def getImgSrcs(htmlist):
import urllib
y=0
for age in htmlist:
print '这个美女的地址是:%s' %age
print '----------------------美女主页--------------------:%s' %age
cont=urlcont(age)
#print'------------------------------------------------'
#print cont
g=getName(cont)
#regcall=r'^1\d{10}\b'
#MMcall=re.compile(regcall)
#mmnum=re.findall(MMcall,cont)
reg=r'src="(\S.*?\.jpg)"'
imageurl=re.compile(reg)
idic={}
idic[age]=re.findall(imageurl,cont)
#print idic[age] #获得美女图片列表
print '======================'
#print 's=%s' %s
#ss=s.decode('gbk')
#sss=s.replace(' ',' ')
#print ss
print g
os.mkdir('D:\\MM-PIC\\%s' %g)
os.chdir('D:\\MM-PIC\\%s' %g)
homedir=os.getcwd()
print homedir
x=0
for j in idic[age]:
print j
urllib.urlretrieve(j,'D:\\MM-PIC\\%s\\%s.jpg' %(g,x))
x+=1
print homedir
mm_name=str(g)+'.txt'
print g
Creatnewtxt(mm_name,age,'D:\\MM-PIC\\%s' %g)
print '这张页面图片张数:%s,' %x
y+=x
return y
---------------------------------------------------------------------------
刚学这个遇到很多问题,遇到很多前辈 指点,完成了我的第一个爬虫。再次感谢!
程序还有很多在功能上,结构上,命名的地方需要改进,比如抓美女的三维数据,联系方式,QQ(QQ这个我试了一下,没办到,网页QQ有的在图片上,还有一抓一大片数字,找不到具体的QQ等)
大概花了3天才解决问题,基本完成的,完成之后的欣喜,那种感觉,真爽!
下面去继续学习爬虫,在麦子网上系统的学习python,如果写了好东西,再跟大家分享。
错误笔记:
第一个就是/xo1/xo0/之类的数据,ASCII报错,耗掉我大量的 时间,解决办法是,在使用参数前,print一下就好了。
第二个调用其他py里面的 函数,没在开头加 #-*- coding: UTF-8 -*- 会显示”SyntaxError: Non-ASCII character '\xb5' in file C:\Python27\myfile.py on line 4, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details“
第三个:淘宝网会禁止访问,跳到淘宝登入页面,我还一直以为是我程序有问题,把内容打印出来才发现。
第四个:decode()在os模块下不好用。
第五个:常常会被缩进,和中文’)搞的蛋碎,不过IDLE报错位置还是很准的,不是前面一个字符就是后面一个字符错了。
哦,忘了这个xingbuxing.py(勿喷)的代码:
#-*- coding: UTF-8 -*-
import os
def Creatnewtxt(txtname,text_cont,Dir):
t=os.getcwd()
print'old=%s' %t
os.chdir(Dir)
t=os.getcwd()
print'now=%s' %t
f=file(txtname,'w')
f.write(text_cont)
f.close()
f=file(txtname)
cont=f.readline()
print cont
f.close()
if __name__ == '__main__':
d='d:\\'
Creatnewtxt('fuhan.txt','you are the best','d:\\')
还有正则测试器RegexTester.exe比较好用。!
如果有美女想要了解我,可以夹我口口:四六二九二九880,ye_mao
还有,本来想用cmd的ping命令来ping出那个page自大页的,但是先生访问不到主机,才发现,后面都变成相同的了。
不明白为什么。
在百度传课上看到抓淘女郎模特照片,我看的免费视频没有看到抓去所有的图片,所以自己用刚学到的知识,把完整。
1,代码完成,抓到的最终效果如下:
开始写代码:
1,分析网页:
http://mm.taobao.com/json/request_top_list.htm?type=0&page= 这个page=1到page=4000都可以。由于找不到上一层网页,所以没办法判断具体的页数是多少。
我的解决办法是新建文件夹的时候,由于出现同样的模特名字的文件,所以抓取会自动报错和停止
2,主代码:
--------------------------------------------------------------------------
i=1
mmurl='http://mm.taobao.com/json/request_top_list.htm?type=0&page='
while i<5:
url=mmurl+str(i) #得到网站地址
cont=urlcont(url) #得到第一页内容
t=getHrefs(cont) #找到第一页美女网站地址列表
y=getImgSrcs(t) #找到图片地址,并存档到对应文件夹内
i+=1
print'理论上下载图片张数:%s' %y
----------------------------------------------------------------------
这里我值设置了抓去前4页面的模特的代码,共40个模特,0页面和1页面是相同的。貌似是个无限循环啊。(后面可以把模特名字作比较,判断是否可以break,由于我没有抓到最后一页,4000X10X120张图片,我的硬盘估没了,所有没打算写break).下面的代码都是按顺序接着来的,不要在乎我这个新手的奇怪命名哦。
------------------------------------------------------------------------
#-*- coding: gbk -*-
import sys
import urllib2
import re
import os
from xinbuxing import Creatnewtxt
def urlcont(url):
up=urllib2.urlopen(url)
cont=up.read()
print cont
return cont #获得内容
----------------------------------------------------------------------
函数urlcont(),定义了打开,并阅读网页源代码。
有一点必须说明,cont有时候会变成淘宝的登入页面,不知道是反爬还是规定需要上线时间怎么的。遇到这种情况一般隔着6分钟在运行就可以了。
---------------------------------------------------------------------------
def getHrefs(cont):
re1=r'a href="(http:.*\.htm)" target'
c=re.compile(re1)
urlLists=re.findall(c,cont)
print '美女主页列表:%s' %urlLists
print '美女主页张数:%s' %len(urlLists)
print'\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\'
return urlLists #美女所有网站地列表
-----------------------------------------------------------------------------------
定义getHrefs(),来获得美女们的网网址
------------------------------------------------------------------------------------
def getName(cont):
name=[]
head=cont.find('<title>')
tail=cont.find('</title>',head+1)
c=cont[head+7:tail]
s=c.replace(' ', '')
#print s
return s
-------------------------------------------------------------------------
如果你仔细看模特网页的源代码,会发现<title>淘女郎 - 尹明月 </title>,我这个正则就是要“淘女郎 - 尹明月。这个函数就是获得模特的名字。下面是最重要的部分了
--------------------------------------------------------------------------------
def getImgSrcs(htmlist):
import urllib
y=0
for age in htmlist:
print '这个美女的地址是:%s' %age
print '----------------------美女主页--------------------:%s' %age
cont=urlcont(age)
#print'------------------------------------------------'
#print cont
g=getName(cont)
#regcall=r'^1\d{10}\b'
#MMcall=re.compile(regcall)
#mmnum=re.findall(MMcall,cont)
reg=r'src="(\S.*?\.jpg)"'
imageurl=re.compile(reg)
idic={}
idic[age]=re.findall(imageurl,cont)
#print idic[age] #获得美女图片列表
print '======================'
#print 's=%s' %s
#ss=s.decode('gbk')
#sss=s.replace(' ',' ')
#print ss
print g
os.mkdir('D:\\MM-PIC\\%s' %g)
os.chdir('D:\\MM-PIC\\%s' %g)
homedir=os.getcwd()
print homedir
x=0
for j in idic[age]:
print j
urllib.urlretrieve(j,'D:\\MM-PIC\\%s\\%s.jpg' %(g,x))
x+=1
print homedir
mm_name=str(g)+'.txt'
print g
Creatnewtxt(mm_name,age,'D:\\MM-PIC\\%s' %g)
print '这张页面图片张数:%s,' %x
y+=x
return y
---------------------------------------------------------------------------
刚学这个遇到很多问题,遇到很多前辈 指点,完成了我的第一个爬虫。再次感谢!
程序还有很多在功能上,结构上,命名的地方需要改进,比如抓美女的三维数据,联系方式,QQ(QQ这个我试了一下,没办到,网页QQ有的在图片上,还有一抓一大片数字,找不到具体的QQ等)
大概花了3天才解决问题,基本完成的,完成之后的欣喜,那种感觉,真爽!
下面去继续学习爬虫,在麦子网上系统的学习python,如果写了好东西,再跟大家分享。
错误笔记:
第一个就是/xo1/xo0/之类的数据,ASCII报错,耗掉我大量的 时间,解决办法是,在使用参数前,print一下就好了。
第二个调用其他py里面的 函数,没在开头加 #-*- coding: UTF-8 -*- 会显示”SyntaxError: Non-ASCII character '\xb5' in file C:\Python27\myfile.py on line 4, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details“
第三个:淘宝网会禁止访问,跳到淘宝登入页面,我还一直以为是我程序有问题,把内容打印出来才发现。
第四个:decode()在os模块下不好用。
第五个:常常会被缩进,和中文’)搞的蛋碎,不过IDLE报错位置还是很准的,不是前面一个字符就是后面一个字符错了。
哦,忘了这个xingbuxing.py(勿喷)的代码:
#-*- coding: UTF-8 -*-
import os
def Creatnewtxt(txtname,text_cont,Dir):
t=os.getcwd()
print'old=%s' %t
os.chdir(Dir)
t=os.getcwd()
print'now=%s' %t
f=file(txtname,'w')
f.write(text_cont)
f.close()
f=file(txtname)
cont=f.readline()
print cont
f.close()
if __name__ == '__main__':
d='d:\\'
Creatnewtxt('fuhan.txt','you are the best','d:\\')
还有正则测试器RegexTester.exe比较好用。!
如果有美女想要了解我,可以夹我口口:四六二九二九880,ye_mao
还有,本来想用cmd的ping命令来ping出那个page自大页的,但是先生访问不到主机,才发现,后面都变成相同的了。
不明白为什么。

相关文章推荐
- C# 堆和栈
- 插入排序增强版
- 携程App的网络性能优化实践
- Error creating bean with name 'sessionFactory' defined in class path resource
- 菜鸟学Android笔记(十一):web开发概述
- LEMP stack On CentOS 7
- 作业1 目标2
- javascript学习代码--点击按钮显示内容
- HDU 1551 Cable master【二分答案】
- Android IOC模块,利用了Java反射和Java注解
- HDU1069
- 面向对象-基本思想
- 面向对象-三大特性
- oracle grid简介
- malloc函数与new函数
- m3u8多码率适配
- Network error IOException: Connection refused: connect
- Android loading界面的一种加载动态图片的方式
- android studio如何导入第三方库slidingmenu(gradle项目)
- C语言的数组初始化