大数据处理的架构逻辑
2015-05-27 21:25
232 查看
大数据系统的逻辑大数据近几年炙手可热。随着互联网和移动互联网的发展,特别是搜索、社交、自媒体和电商等所谓Web2.0应用的全面展开,相关公司的手上积累了大量的数据:从互联网收集的网页数据;用户输入的博客、微博、聊天记录;用户的购买、浏览记录等。这些数据当中蕴含着大量的关于用户行为等的信息。对这些信息的掌握可以帮助公司进行精准的广告投放、有的放矢的推荐和提供个性化的服务。
大数据处理,跟所有的数据处理一样,主要是解决两个问题:
•数据保存
•数据操作
还有一个比较次要的,也就是处理结果的展现。开发一种可以处理各种形式/特征的通用的数据存储和处理方式是不可能的,因此为了解决大数据的上述两个问题,首先必须了解它的特点。
大数据的特点
在《大数据时代》中,维克托·迈尔-舍恩伯格及肯尼斯·库克耶提到了大数据的4V特点:
Value(价值)
Velocity(速度)
Variety(多样性)、
Volume(体量)
从大数据系统的逻辑据本身的特点来说,这是没有问题的。但从数据存储和处理的技术角度来说,大数据具有以下特点:
数据单向增加。大数据所处理的对象数据是随着时间而累积的,具有Write-once-read-many的数据访问特点,基本没有删除(偶尔?)和修改等的操作。
数据形态多样,很难正规化到可以用传统DB保存的形式。当然,一些传统的DB也进行了相应的扩充以保存这样的数据,但是传统DB的查询、处理方法几乎用不上。
数据的价值随时间递减。实时的数据价值最大,一些历史数据在趋势分析中也有很大的作用,但价值随时间递减的总趋势不变。
数据在一个或多个数据中心的集群的大量机器中保存。由于服务器利用普通的商用硬件,再加上大量的数据读写,导致硬件故障发生频率比较高。
数据的利用主要有两种形式:一种是对数据全体或抽取的一部分作各种变换、查询操作。另一种是对数据全体作各种挖掘等的批处理操作。
数据保存
数据保存涉涉及到两个问题:数据的表达和数据的存储。
鉴于大数据形态的多样性,很难用一种统一的结构化方法对数据建模。现在采用的基本策略都是用一个统一的大表(Bigtable)来保存。在大表中,所有的数据(包括键值)都以字符串的形式保存,将字符串的内部格式的控制权交给该数据的用户。该方案在简化数据模型的同时,也增加了数据用户的负担。因此这是权衡利弊的一个结果。而且这种存储格式也决定了计算框架的选择。这是由谷歌首先提出,并应用在它的一系列产品中。在Hadoop中也有它的对应实现:HBase。
Bigtable的数据模型简化为以下的数据对:
(row: string, column: string,time: int64)→stirng
也即,从行键、列键、时间戳到数据值的一个对应关系。如上所述,行键、列键和数据值均采用字符串表示,并由用户指定这些这些字符串的格式。
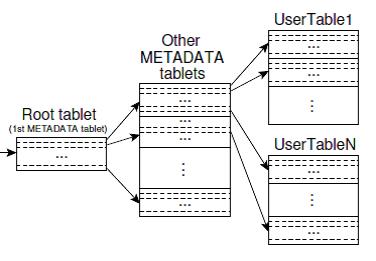
与传统的关系数据库类似,也需要解决数据的索引、查询问题。同时还要保证尽可能的平行查找以提高性能。在Bigtable中,数据以片(Tablet)为单位保存,Tablet为一系列连续数据行的集合,由主服务器(Master Server)和Tablet服务器的两级结构来搜索(见下图)。Tablet可以增/删,也可以合并。
在绝大多数应用中,Bigtable是稀疏的。因此在Tablet中保存数据时利用Google的SStable文件格式,SSTable是一致、有序、不可变的(Key,Value)对。Key和Value都可以是任意字节的字符串。
实际上,数据的表达和数据的存储是紧密相关的。为了存储Bigtable的数据,谷歌提出了一个分布式文件系统GFS(Google File System)。相应地在Hadoop中也有一个对应的实现:HDFS(Hadoop DistributedFile System)。一个良好的存储解决方案需要解决以下几个问题:
大量数据的保存。唯一的选择只有分布式保存。当然在分布式保存的前提下,需要解决数据组织、访问接口和数据检索的问题。
数据的可靠性。在使用普通商用硬件的前提下,硬件故障的发生是不可避免的,因此提高可靠性的唯一选择就是数据的冗余备份。与此相关,主要需要解决故障检测、冗余备份的时机、数据一致性等问题。次要地,也涉及到冗余备份的安排,既保证可靠性尽量高,也要保证并发访问的速度尽量快。
数据的快速访问,也即数据访问的吞吐率。提高吞吐率的方法不外乎分布式保存和平行读取。为了消除瓶颈,需要保证对主控节点的访问尽量地少。
数据的处理
在对数据进行查询和处理时,由于一个数据集的数据分散在成百上千、甚至上万的计算机上,因此大规模平行处理框架就成为一个必然的选择。另外,由于数据的体量、及数据结构由用户决定的特点,传统的类似C/S的架构,已然不能处理。需要新的处理框架。

但无论是哪种处理框架,都需要解决以下几个问题:
尽可能避免大量数据在计算/存储节点间的移动。
将数据处理程序推到数据存储节点上。
处理应仅可能在不同的节点上平行进行。
在Hadoop中,提供了两种处理框架:HadoopMapReduce和Spark。前者比较适合对整个数据集的批处理操作,后者比较适合对整个数据集、或其中一部分进行反复的变换、查询等操作。
在后续文章中,将会就大数据处理系统的存储及处理的各个方面进行介绍。
大数据处理,跟所有的数据处理一样,主要是解决两个问题:
•数据保存
•数据操作
还有一个比较次要的,也就是处理结果的展现。开发一种可以处理各种形式/特征的通用的数据存储和处理方式是不可能的,因此为了解决大数据的上述两个问题,首先必须了解它的特点。
大数据的特点
在《大数据时代》中,维克托·迈尔-舍恩伯格及肯尼斯·库克耶提到了大数据的4V特点:
Value(价值)
Velocity(速度)
Variety(多样性)、
Volume(体量)
从大数据系统的逻辑据本身的特点来说,这是没有问题的。但从数据存储和处理的技术角度来说,大数据具有以下特点:
数据单向增加。大数据所处理的对象数据是随着时间而累积的,具有Write-once-read-many的数据访问特点,基本没有删除(偶尔?)和修改等的操作。
数据形态多样,很难正规化到可以用传统DB保存的形式。当然,一些传统的DB也进行了相应的扩充以保存这样的数据,但是传统DB的查询、处理方法几乎用不上。
数据的价值随时间递减。实时的数据价值最大,一些历史数据在趋势分析中也有很大的作用,但价值随时间递减的总趋势不变。
数据在一个或多个数据中心的集群的大量机器中保存。由于服务器利用普通的商用硬件,再加上大量的数据读写,导致硬件故障发生频率比较高。
数据的利用主要有两种形式:一种是对数据全体或抽取的一部分作各种变换、查询操作。另一种是对数据全体作各种挖掘等的批处理操作。
数据保存
数据保存涉涉及到两个问题:数据的表达和数据的存储。
鉴于大数据形态的多样性,很难用一种统一的结构化方法对数据建模。现在采用的基本策略都是用一个统一的大表(Bigtable)来保存。在大表中,所有的数据(包括键值)都以字符串的形式保存,将字符串的内部格式的控制权交给该数据的用户。该方案在简化数据模型的同时,也增加了数据用户的负担。因此这是权衡利弊的一个结果。而且这种存储格式也决定了计算框架的选择。这是由谷歌首先提出,并应用在它的一系列产品中。在Hadoop中也有它的对应实现:HBase。
Bigtable的数据模型简化为以下的数据对:
(row: string, column: string,time: int64)→stirng
也即,从行键、列键、时间戳到数据值的一个对应关系。如上所述,行键、列键和数据值均采用字符串表示,并由用户指定这些这些字符串的格式。
与传统的关系数据库类似,也需要解决数据的索引、查询问题。同时还要保证尽可能的平行查找以提高性能。在Bigtable中,数据以片(Tablet)为单位保存,Tablet为一系列连续数据行的集合,由主服务器(Master Server)和Tablet服务器的两级结构来搜索(见下图)。Tablet可以增/删,也可以合并。
在绝大多数应用中,Bigtable是稀疏的。因此在Tablet中保存数据时利用Google的SStable文件格式,SSTable是一致、有序、不可变的(Key,Value)对。Key和Value都可以是任意字节的字符串。
实际上,数据的表达和数据的存储是紧密相关的。为了存储Bigtable的数据,谷歌提出了一个分布式文件系统GFS(Google File System)。相应地在Hadoop中也有一个对应的实现:HDFS(Hadoop DistributedFile System)。一个良好的存储解决方案需要解决以下几个问题:
大量数据的保存。唯一的选择只有分布式保存。当然在分布式保存的前提下,需要解决数据组织、访问接口和数据检索的问题。
数据的可靠性。在使用普通商用硬件的前提下,硬件故障的发生是不可避免的,因此提高可靠性的唯一选择就是数据的冗余备份。与此相关,主要需要解决故障检测、冗余备份的时机、数据一致性等问题。次要地,也涉及到冗余备份的安排,既保证可靠性尽量高,也要保证并发访问的速度尽量快。
数据的快速访问,也即数据访问的吞吐率。提高吞吐率的方法不外乎分布式保存和平行读取。为了消除瓶颈,需要保证对主控节点的访问尽量地少。
数据的处理
在对数据进行查询和处理时,由于一个数据集的数据分散在成百上千、甚至上万的计算机上,因此大规模平行处理框架就成为一个必然的选择。另外,由于数据的体量、及数据结构由用户决定的特点,传统的类似C/S的架构,已然不能处理。需要新的处理框架。
但无论是哪种处理框架,都需要解决以下几个问题:
尽可能避免大量数据在计算/存储节点间的移动。
将数据处理程序推到数据存储节点上。
处理应仅可能在不同的节点上平行进行。
在Hadoop中,提供了两种处理框架:HadoopMapReduce和Spark。前者比较适合对整个数据集的批处理操作,后者比较适合对整个数据集、或其中一部分进行反复的变换、查询等操作。
在后续文章中,将会就大数据处理系统的存储及处理的各个方面进行介绍。

相关文章推荐
- 大数据处理的架构逻辑
- 大数据处理的架构逻辑
- 大数据处理的架构逻辑
- 大数据处理的架构逻辑
- 大数据处理的架构逻辑
- 大数据处理的架构逻辑
- SQL SERVER 2008用Select操作处理数据(二)——查询语句的逻辑流
- 日处理20亿数据_实时用户行为服务系统架构实践
- 【大数据处理架构】0.综述-资料楼
- 从 LinkedIn 的数据处理机制学习数据架构
- 自动筛选的逻辑(4)-对可见数据的处理
- Spring+Struts+Hibernate 架构中对Oracle9i中clob字段的处理之--新增数据篇
- Go Programming Blueprints 读书笔记(谈到了nsq/mgo处理数据持久化,但是业务逻辑不够复杂)
- 大数据架构简述(三):流处理、批处理、交互式查询
- android MVP 轻松理解MVP模式的数据传递与逻辑处理
- 组合逻辑与时序逻辑,逻辑的接口处数据稳定处理摘记
- 大数据实时处理系统架构
- Storm - 大数据Big Data实时处理架构
- 物联网数据采集处理架构