DNN模型
2015-05-21 19:22
176 查看
Deep Neural Network(DNN)模型是基本的深度学习框架;
(一)神经元计算模型(感知机模型)
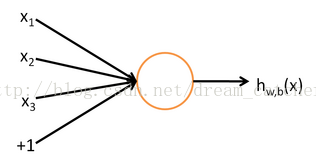
1.计算公式:

2.常见响应函数(非线性函数):
(1)logistic/sigmoid function:

(2)tanh function:
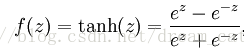
(3)step/binary function:

(4)rectifier function:

(5)analytic function:rectifier function的平滑近似:
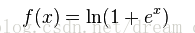
(二)DNN模型

1.结构:输入层(1层)——隐层(可以有多层)——输出层(1层)
2.符号表示:

3.计算公式:

(三)训练DNN模型
1.代价函数:
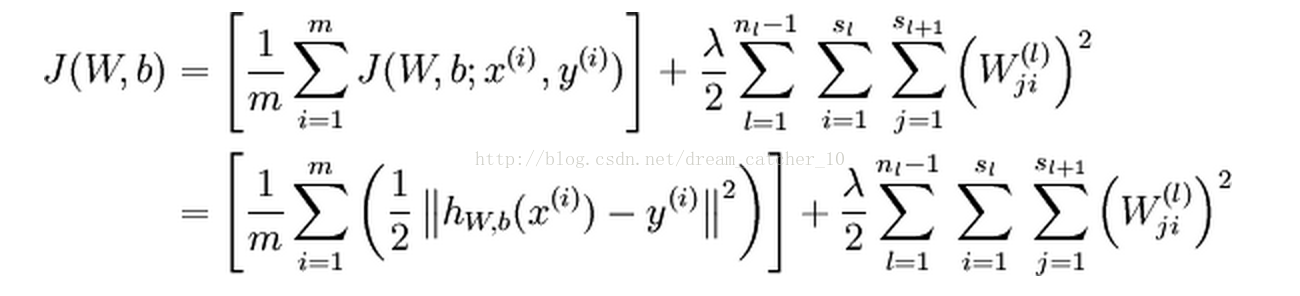
其中:

ps:(1)第一项是损失函数,采用平均平方误差(MSE);第二项是正则化约束,防止过拟合;
(2)代价函数J是非凸函数,优化时采用批量梯度下降法;
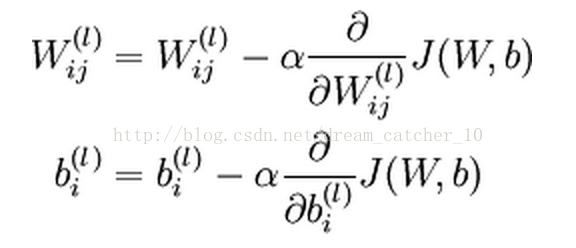
其中:

2.反向传播算法(BP算法):
(1)进行前向传导计算;
(2)计算残差:


(3)计算梯度:

ps:针对的是一个样本进入网络时的计算;
3.批量梯度下降法:
(1)初始化:

;w,b则随机初始化为比较小的数值;
(2)对于一个数量为m的batch,i = 1到m,依次用BP算法计算出梯度并进行累加:

(3)更新参数:

( 4)回到步骤(2),重新选择一个batch,继续迭代,不断减小J函数的值,从而求出参数w,b;
4.训练难度:
(1)标注数据稀少导致训练出来的深度神经网络过拟合;
(2)对于深度神经网络,通常会涉及到求解一个高度非凸优化问题,这种非凸优化问题的搜索区域中充斥着大量“坏”的局部极值,使用梯度下降法效果并不理想;
(3)使用梯度下降法之前会对深度神经网络进行权重的随机初始化,在利用反向传播算法计算残差时,随着网络层次的增加,残差会下降得特别快,导致前几层得权重更新缓慢;因此训练得到得深度神经网络只有后面几层网络具有效果;(梯度弥散问题)
ps:逐层贪婪训练方法可以很好地解决上述问题;
5.逐层贪婪训练方法:
(1)思想:逐层贪婪算法的主要思路是每次只训练网络中的一层,即我们首先训练一个只含一个隐藏层的网络,仅当这层网络训练结束之后才开始训练一个有两个隐藏层的网络,以此类推;在每一步中,我们把已经训练好的前
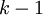
层固定,然后增加第

层(也就是将我们已经训练好的前
的输出作为输入);每一层的训练通常使用无监督方法(例如自动编码);这些各层单独训练所得到的权重被用来初始化深度网络的权重,然后对整个网络进行“微调”(即把所有层放在一起来优化有标签训练集上的训练误差);
(2)优点:
1)预训练阶段采用的是无监督学习方法,所需要的没有标签的数据来源广泛,极易获取;
2)当用无标签数据训练完网络后,相比于随机初始化而言,各层初始权重会位于参数空间中较好的位置上;然后我们可以从这些位置出发进一步微调权重;从经验上来说,以这些位置为起点开始梯度下降更有可能收敛到比较好的局部极值点,这是因为无标签数据已经提供了大量输入数据中包含的模式的先验信息;
(四)BP算法
Backpropagation Algorithm(BP)算法是一种利用神经网络求解梯度的算法,适用于从矩阵到实数的函数:

1.将目标函数化解成神经网络的形式,其中的未知数一般以输入或者权重的形式存在;

(1)网络的描述:
1)把 A 作为第一层到第二层的权重;
2)将第二层的激励减 x ,第二层使用了单位激励函数;
3)通过单位权重将结果不变地传到第三层,在第三层使用平方函数作为激励函数;
4)将第三层的所有激励相加;
(2)网络参数如下:
2.残差计算公式
(1)最后一层的残差:

(2)其他层的残差:

3.基于残差计算出梯度;
(1)未知数是输入:

(2)未知数是权重:

因此:

4.BP的思想:设目标函数为F,形式一般为范数形式,其残差的计算其实就是分别对每一层的z求导

(一)神经元计算模型(感知机模型)
1.计算公式:
2.常见响应函数(非线性函数):
(1)logistic/sigmoid function:
(2)tanh function:
(3)step/binary function:
(4)rectifier function:
(5)analytic function:rectifier function的平滑近似:
(二)DNN模型
1.结构:输入层(1层)——隐层(可以有多层)——输出层(1层)
2.符号表示:
3.计算公式:
(三)训练DNN模型
1.代价函数:
其中:
ps:(1)第一项是损失函数,采用平均平方误差(MSE);第二项是正则化约束,防止过拟合;
(2)代价函数J是非凸函数,优化时采用批量梯度下降法;
其中:
2.反向传播算法(BP算法):
(1)进行前向传导计算;
(2)计算残差:
(3)计算梯度:
ps:针对的是一个样本进入网络时的计算;
3.批量梯度下降法:
(1)初始化:
;w,b则随机初始化为比较小的数值;
(2)对于一个数量为m的batch,i = 1到m,依次用BP算法计算出梯度并进行累加:
(3)更新参数:
( 4)回到步骤(2),重新选择一个batch,继续迭代,不断减小J函数的值,从而求出参数w,b;
4.训练难度:
(1)标注数据稀少导致训练出来的深度神经网络过拟合;
(2)对于深度神经网络,通常会涉及到求解一个高度非凸优化问题,这种非凸优化问题的搜索区域中充斥着大量“坏”的局部极值,使用梯度下降法效果并不理想;
(3)使用梯度下降法之前会对深度神经网络进行权重的随机初始化,在利用反向传播算法计算残差时,随着网络层次的增加,残差会下降得特别快,导致前几层得权重更新缓慢;因此训练得到得深度神经网络只有后面几层网络具有效果;(梯度弥散问题)
ps:逐层贪婪训练方法可以很好地解决上述问题;
5.逐层贪婪训练方法:
(1)思想:逐层贪婪算法的主要思路是每次只训练网络中的一层,即我们首先训练一个只含一个隐藏层的网络,仅当这层网络训练结束之后才开始训练一个有两个隐藏层的网络,以此类推;在每一步中,我们把已经训练好的前
层固定,然后增加第
层(也就是将我们已经训练好的前
的输出作为输入);每一层的训练通常使用无监督方法(例如自动编码);这些各层单独训练所得到的权重被用来初始化深度网络的权重,然后对整个网络进行“微调”(即把所有层放在一起来优化有标签训练集上的训练误差);
(2)优点:
1)预训练阶段采用的是无监督学习方法,所需要的没有标签的数据来源广泛,极易获取;
2)当用无标签数据训练完网络后,相比于随机初始化而言,各层初始权重会位于参数空间中较好的位置上;然后我们可以从这些位置出发进一步微调权重;从经验上来说,以这些位置为起点开始梯度下降更有可能收敛到比较好的局部极值点,这是因为无标签数据已经提供了大量输入数据中包含的模式的先验信息;
(四)BP算法
Backpropagation Algorithm(BP)算法是一种利用神经网络求解梯度的算法,适用于从矩阵到实数的函数:
1.将目标函数化解成神经网络的形式,其中的未知数一般以输入或者权重的形式存在;
(1)网络的描述:
1)把 A 作为第一层到第二层的权重;
2)将第二层的激励减 x ,第二层使用了单位激励函数;
3)通过单位权重将结果不变地传到第三层,在第三层使用平方函数作为激励函数;
4)将第三层的所有激励相加;
(2)网络参数如下:
| 层 | 该层输入z | 权重 | 激励函数 f | 激励函数的导数f' | Delta |
| 1 | s | A | f(zi) = zi | f'(zi) = 1 | 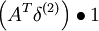 |
| 2 | As | I (单位向量) | f(zi) = zi − xi | f'(zi) = 1 | 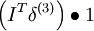 |
| 3 | As − x | 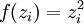 | f'(zi) = 2zi | f'(zi) = 2zi |
(1)最后一层的残差:
(2)其他层的残差:
3.基于残差计算出梯度;
(1)未知数是输入:
(2)未知数是权重:
因此:
4.BP的思想:设目标函数为F,形式一般为范数形式,其残差的计算其实就是分别对每一层的z求导

相关文章推荐
- 深度神经网络(DNN)模型与前向传播算法
- 声学模型学习笔记(二) DNN
- 深度神经网络(DNN)模型与前向传播算法
- 深度神经网络(DNN)模型与前向传播算法
- 声学模型学习笔记(三) DNN-HMM hybrid system
- Kaldi 训练一个 DNN 声学模型
- 声学模型学习笔记(四) dnn speedup
- 使用opencv3.20编译dnn模块,生成的库来加载caffe模型,从而在VS工程上跑。避坑锦集。
- OpenCV的dnn模块调用TesorFlow训练的MoblieNet模型
- TensorFlow中优化DNN模型tips
- 闲聊DNN CTR预估模型
- 深度神经网络(DNN)模型与前向传播算法
- 能在不同的深度学习框架之间转换模型?微软的MMdnn做到了
- cuDNN 5对RNN模型的性能优化
- 减小dnn模型大小的方法
- 用SVD压缩深度模型(DNN,CNN)的全连接层(fully-connected layer)
- dlib 17 dlib自带demo 基于DNN的车辆检测模型训练
- 深度神经网络(DNN)模型与前向传播算法
- 使用skflow内置的LR,DNN,Scikit-learn中的集成回归模型对“美国波士顿房价”进行预测