决策树——ID3和C4.5
2015-05-13 09:13
232 查看
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
构建决策树的过程:
关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1. 属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2. 属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3. 属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类的启发式分类,它决定了拓扑结构及分裂点split_point的选择。
属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心算法。
熵越大,越混乱,越稳定(熵表示混乱程度,越混乱表明越不需要维持,则越稳定;越整齐越需要维持,越不稳定)。
期望信息越小,信息增益越大,从而纯度越高。我们需要找的是最“纯”的特征。
设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
=-\sum%20^m_{i=1}p_ilog_2(p_i))
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
=\sum%20^v_{j=1}\frac{|D_j|}{|D|}info(D_j))
而信息增益即为两者的差值:
=info(D)-info_A(D))
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。下面我们继续用SNS社区中不真实账号检测的例子说明如何使用ID3算法构造决策树。为了简单起见,我们假设训练集合包含10个元素:
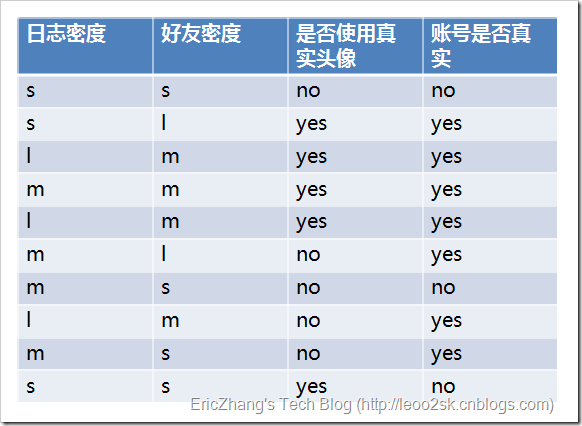
其中s、m和l分别表示小、中和大。
设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。
=-0.7log_20.7-0.3log_20.3=0.7*0.51+0.3*1.74=0.879)
=0.3*(-\frac{0}{3}log_2\frac{0}{3}-\frac{3}{3}log_2\frac{3}{3})+0.4*(-\frac{1}{4}log_2\frac{1}{4}-\frac{3}{4}log_2\frac{3}{4})+0.3*(-\frac{1}{3}log_2\frac{1}{3}-\frac{2}{3}log_2\frac{2}{3})=0+0.326+0.277=0.603)
=0.879-0.603=0.276)
因此日志密度的信息增益是0.276。
用同样方法得到H和F的信息增益分别为0.033和0.553。
因为F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示:
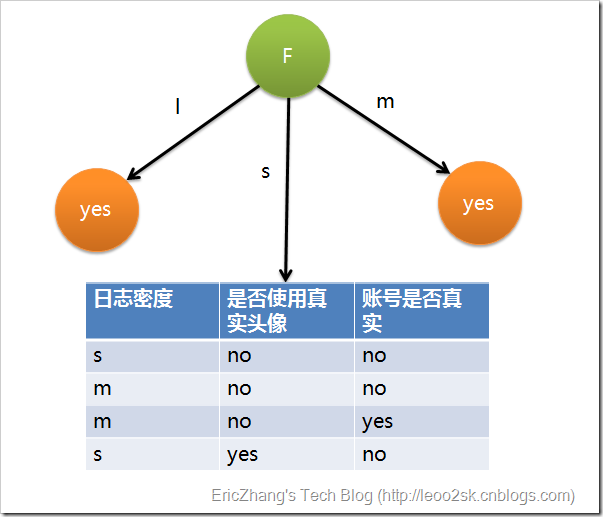
在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。
上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法:
先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。
ratio)的信息增益扩充,试图克服这个偏倚。
C4.5算法实现步骤:
1)求“分裂信息” :
=-\sum%20^v_{j=1}\frac{|D_j|}{|D|}log_2(\frac{|D_j|}{|D|}))
2)求熵:
3)划分期望:
4)信息增益:
5)增益率:
=\frac{gain(A)}{split\_info(A)})
C4.5选择具有最大增益率的属性作为分裂属性。
建议参考机械工业出版社《数据挖掘概念与技术》第3版,P213-P220,更容易明白。
——————————————————————————我是华丽丽的分割线——————————————————————————
欢迎互相讨论交流,望不吝赐教。
构建决策树的过程:
关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1. 属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2. 属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3. 属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类的启发式分类,它决定了拓扑结构及分裂点split_point的选择。
属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心算法。
ID3算法
ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。熵越大,越混乱,越稳定(熵表示混乱程度,越混乱表明越不需要维持,则越稳定;越整齐越需要维持,越不稳定)。
期望信息越小,信息增益越大,从而纯度越高。我们需要找的是最“纯”的特征。
设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
而信息增益即为两者的差值:
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。下面我们继续用SNS社区中不真实账号检测的例子说明如何使用ID3算法构造决策树。为了简单起见,我们假设训练集合包含10个元素:
其中s、m和l分别表示小、中和大。
设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。
因此日志密度的信息增益是0.276。
用同样方法得到H和F的信息增益分别为0.033和0.553。
因为F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示:
在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。
上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法:
先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。
C4.5算法
ID3算法存在一个问题,就是偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。ID3的后继算法C4.5使用增益率(gainratio)的信息增益扩充,试图克服这个偏倚。
C4.5算法实现步骤:
1)求“分裂信息” :
2)求熵:
3)划分期望:
4)信息增益:
5)增益率:
C4.5选择具有最大增益率的属性作为分裂属性。
建议参考机械工业出版社《数据挖掘概念与技术》第3版,P213-P220,更容易明白。
——————————————————————————我是华丽丽的分割线——————————————————————————
欢迎互相讨论交流,望不吝赐教。

相关文章推荐
- 初窥决策树中的ID3和C4.5
- 决策树之ID3、C4.5、C5.0算法
- 【用python实现《统计学习方法》】之决策树C4.5/ID3
- 决策树中ID3、C4.5、CART
- 决策树之ID3、C4.5、C5.0等五大算法
- 机器学习系列(5):决策树之ID3和C4.5
- 《统计学习方法》读书笔记-----决策树:ID3,C4.5生成算法和剪枝
- 决策树 (Decision Tree) 原理简述及相关算法(ID3,C4.5)
- 转载]决策树ID3、C4.5、CART科普
- ID3决策树原理分析及python实现
- 决策树之C4.5实现(离散属性与连续,属性并存)
- 《统计学习方法》读书笔记-----决策树:ID3,C4.5生成算法和剪枝
- 决策树C4.5
- 决策树(ID3、C4.5、CART、随机森林)
- ID3、C4.5、CART、RandomForest的原理
- [每日问答]ID3,C4.5,CART的区别是什么?
- ID3、C4.5、CART三种决策树的区别
- ID3、C4.5和cart算法比较(转)
- python之实战----决策树(ID3,C4.5,CART)战sin(x)+随机噪声
- 《统计学习方法》读书笔记-----决策树:ID3,C4.5生成算法和剪枝