编写基于机器学习的程序,有哪些编写和调试的经验和窍门?
2015-04-24 17:51
204 查看
最近做了一个课程作业,用matlab编程一个分类器,由于是控制和弱电出身,
对于这种数据处理的程序不是很熟悉,所以很是费劲,而这个作业数据只是两维的特征,最后出来的效果还是不如matlab自带的程序。
深感机器学习的算法非常抽象,而且实际实现时,有很多细节资料上没有提到。
而且如果要优化算法效率、提高适用性和可靠性,更是要对算法理解很透彻,感觉这点很难,因为对数学要求特别高,而且数据特征维数大了,根本不知道该如何调试·····
求高人们指点一二!!修改
举报
1
条评论 分享 • 邀请回答
Joey Teng、王宇恒、你好凯蒂 等
87 人赞同
机器学习方向的博士生,个人有几点体会。
1. 尽最大可能复用别人的代码。哪怕编译等等很麻烦,也可以在调试上省很多很多时间。血的教训。
2. 多把数据可视化出来,很多问题你看数字很难有直观感受,但往往一画出来就会发现哪里错了。这在高维数据下尤其明显。
3. 调试的时候和普通程序一样,看到结果不对就逆推,找到问题是从哪个地方开始引入,从哪句话开始实际数值和你的期待不一样的。定位问题就成功了一大半。可以用非常简单的数据代入验证,这样你也知道正确的结果是什么。
4. 关于工具的选择,原则实是先确认算法是对的,再调优实现。具体说先用matlab/python之类方便可视化的工具快速迭代找到一个能得到正确结果的算法。然后再用c++/mex优化速度。否则一个跑的很快的屎还是一坨屎。
87 发布于
2014-04-26 13
条评论
函阵、Yao
Wu、王海鹏 等 33 人赞同
作为一个纯做机器学习,主要搞probabilistic graphical model的苦逼Ph.D,大多数时间实际上是在推公式好吧摔!!!anyway,说说自己编写、调试机器学习程序的经验吧。
1,要用print !
大多数机器学习方法是优化问题,一般是迭代求解,算法一般就是gradient descent的各种变种。自己编写的时候,尽量打印每轮迭代时model的信息,包括目标函数值、训练数据上的错误率,甚至测试数据上的错误率,probabilistic model经常打印log-likelihood。举个例子,如果迭代中,目标函数值增加了(diverge
了),先检查是否是learning rate设的过大(最常见),gradient的正负搞反了(也很常见。。),如果不是,基本就要断点调试了。再比如,如果训练错误率一直在下降,测试错误率开始上升,那就是过拟合了。
2,先在toy/simulated的data上测试通过
real data一般有不少预处理的问题,数据本身也有很多不符合模型假设的“个性”,很多时候,会影响你对机器学习模型、算法本身正确性的判断。最重要的,这样调试大大节省了时间。
3,不要吝啬注释
机器学习核心算法的程序,通常非常短小,但是如果没有注释,可读性会很差。因为代码背后是公式。对绝大多数凡人来说,公式本身就已晦涩,从代码里面读出公式,搞清楚程序在干吗,更是坑爹。所以,为了自己跟他人的身心健康,请加注释。
4,如果专注机器学习算法本身,复用别人的代码要慎重。
当你自己提了一个模型、算法,想投NIPS、ICML、AIStats、UAI,需要对比前人的算法时,如果不是特别难,建议自己动手实现前人的方法(实际上,这是当年老板给我的忠告)。。首先,如果你只是把别人的代码当做一个黑盒子,很难得到自己的方法为啥好,别人的方法为啥差的insight,如果不幸自己的方法差,也很难找到改进自己方法的窍门。再者,最新提出的方法,一般没有可用的高质量代码。注意!!如果你的主要目标不是提出新的算法,而是想在某个应用上做出好的正确率,那么按 @grapeot说的,尽可能复用别人的代码。
5,先编写简单的机器学习算法练手
比如logistic regression, 比如EM for Gaussian Mixture, 比如SVM。先用最简单的实现。logistic regression就用gradient descent,linear svm就用sub-gradient decent。加了各种kernel的svm就用naive的quadratic programming,熟悉一些了,也可以用SMO。磨刀不误砍柴工,能学到很多。
6, 机器学习程序中的小bug很难发现
难发现的原因在于,有小bug的程序工作的很好,没有任何错误的征兆~~甚至有些时候,带小bug的程序,会比没bug的程序得到的正确率更高...(有多年ML经验的人,肯定遇到过这样的情况)。原因是小bug会起到某种regularization的作用,防止了过拟合。所以尽人力后,顺其自然吧。。。
p.s.题外话,这个现象曾在12年NIPS的时候,被一个机器学习的大牛Dietterich拿来调侃巨牛Hinton提出的dropout方法。Hinton当时说,如果我的方法work得好,是因为有bug,那一定是世上最好的bug~~因为我的程序总是在赢各种竞赛。。
33 编辑于
2014-06-14 3
条评论
刘晓彤、Ger
Young、张翔 等 9 人赞同
所有机器学习问题都可以转化成一个优化问题,所以先学习优化,特别是凸优化,先看无约束条件的优化,再学有约束条件的优化。你会发现所有分类器都差不多,只是目标方程不一样,约束条件不一样吧了。
9 发布于
2014-05-02 2
条评论
刘晓彤、Shen
Li、Auguste 等 15 人赞同
建议lz去Coursera听几节Machine Learning的课Coursera.org,然后做一下对应的作业。作业就是用MATLAB编的,如果你能把作业里面的代码都理解好了。我觉得应该就算入门了吧~
而且你可以趁此机会熟悉熟悉MATLAB的矩阵化运算,以及其他的常用指令。
至于难不难,我觉得学控制的同学,应该有足够的数学基础(线性代数+概率论)去理解的哈。
同学你也可以参考一下我的代码zihaolucky/Machine-Learning-and-UFLDL ·
GitHub . Lecture和code都有了。不过,如果你要跟那门课,还是自己完成吧,有honor code规则的哈。
至于vczh同学提到的“那些模型训练出来的系数是不可理解的,调试他们干什么……”.确实如此,机器学习,就是学习出那些参数,以最好地贴近数据模式啊。这个是算法。需要优化的,可能是你程序的速度。
15 编辑于
2014-04-26 添加评论
beyond love、caporion、周冠权 等
59 人赞同
首先关于语言的选择,个人认为还是Matlab比较合适,因为目前在学术领域,用Matlab的人感觉还是相对多一点的。题主如果在写代码的过程中遇到了问题,也比较方便向别人请教。目测开源的机器学习库也是Matlab更多。当然如果对程序速度有严格要求,就可以考虑C++。
其次对于题主你来讲,最重要的问题是要明确自己的目的。
说实话,如果只是一个课程作业的话,完全没必要深入到很多算法的细节,只要了解了算法的大体流程即可,再选择别人实现好的算法,多次测试,一般结果是可以让人满意的。
但如果题主是想继续在机器学习领域深入研究的话,了解算法细节就是必不可少的了。不过即便这样,还是要从简单入手逐渐加深难度。否则学习曲线太陡,一般人都hold不住。
(另外自己感觉机器学习还算是入门容易精通难的,深入研究充满了大量细节和数学,研究者们也在一直outperform其他人……( ̄ε ̄;))
所以,综上,题主最好从简单入手!( ̄ε ̄;)
先了解基本算法思路,再使用现成代码进行实验!
在此,我强烈推荐一个模式识别库 PRTools5!在这里下载:Software - Pattern Recognition
Tools,作者叫R.P.W.
Duin。
这个库最大的优点就是简单方便,而且实现了大量大量常用算法,对于初学者,完全可以上手就用,避免陷入细节的泥潭。而且都经过大量测试,基本没有严重bug。简单举几个栗子:
首先,需要构造两个数据集:
其中,prdataset是PRTools5中的函数,目的就是构造数据集……
X是训练数据矩阵,每一行是一个数据点(一个object),每列是一个特征(feature)。Y是一个列向量,代表数据X的标签。怎么样,简单吧……
之后,就可以进行分类(classification)了!
其中,w1, w2, w3, w4 就是训练好的分类器了。knnc是knn…qdc是Quadratic Bayes Normal Classifier,svc是svc……naivebc是Naive Bayes。
至于各种参数呢?函数都已经自动选择了,当然题主根据自己要处理的具体问题,也完全可以手动指定。
之后就可以测试结果了,我们选择B作为测试集。
这里的e就是classification error……当然也可以选择其他函数,使用其他判断标准。
但鉴于题主的数据是二维的,因此可视化是一个很好很强大的手段。(二维的!这年头哪还有这么好的事└(T_T;)┘……)。以下举例:
此处使用了PRTools5自带的数据生成函数,A、B都是二维数据,2 classes,每类中有50(400)个objects。
……不用解释。
结果如下:
这时真相大白,原来gendatb是生成banana形状的数据…………而且显然,对于这种数据,knn的效果最好。
总之PRTools5是一个非常强大的模式识别库。
而且这时再看,机器学习也就不麻烦且不抽象了吧~~
59 编辑于
2014-05-01 5
条评论
北落、陈应佳、陈狄 等
17 人赞同
不知道题主要写编写的是哪个分类器,不同分类器的编写复杂度相差非常大。像KNN,几句话就能写出来,而像SVM,要复杂得多。
相对于其它语言,我觉得MATLAB是我遇到的最容易上手的。最大的优势是方便查看各变量值与调试。
说说我认为一些有用的技巧:
1. 比较复杂的算法,可以先用数学语言把大概流程写出来,这样编程的时候有个参照。对算法流程非常清楚,是将它代码实现的必要条件。
2. 由简入难。先实现算法的一些基本功能,而扩展功能留到后面做。
3. 边写边调试,尤其是自己对编程语言不太熟悉的情况下,犯错的机率非常大。如果写了几百行再调试,那绝对是个巨大的工程。所以建议每写个几行,就F5运行下,查看下各个变量的值,看与自己想像的是否一样。这样便于即时发现问题,改正问题。
另外,刚开始编写,不建议把代码写在function里,然后用主程序调用,这样不方便查看变量值与调试。我倾向先在主程序里把代码功能实现,调试确定没问题了,再把它转移到一个function里,保持主程序代码的简洁。当然这种方法对Python, C之类的语言没有用处。
4. 自己构造一个简单的样例来调试程序。一个简单的样例,自己能清楚的判断程序输出结果是否正确。而如果是很复杂的样例,判断起来就麻烦得多。
暂时想到的就这么多,希望能有帮助。
17 发布于
2014-04-26 3
条评论
Michael Jackson 赞同
机器学习coding比较蛋疼啊
我比较笨 一般是这么搞得
1,找个别人写好的程序1先跑,这时候一般都是matlab等好调试的语言 跑对了ok下一步
2,理解程序1内在算法,根据需求改进成自己的版本2,语言跟上面相同,这个如果效果还行,就可以作为正确答案
3,按照自己的版本2改写成c等高效语言,然后跟版本2每一步每个值对每个值的跟踪调试,遇到随机数的地方就设置成一样的值,挑对了再改回去,保证每个地方跟正确答案一致,这样出来的东西应该正确性就可以保证了。就是过程有点蛋疼了
1 发布于
2015-03-26 1
条评论
安如磐石 赞同
弄出代价函数,选择最优化的方法,就这样。过程中,要想办法算出参数的梯度
1 发布于
2015-01-26 添加评论
Paul Meng、于鑫、安迪 等
9 人赞同
你搞机器学习的时候,那些模型训练出来的系数是不可理解的,调试他们干什么……
9 发布于
2014-04-26 6
条评论
Michael Jackson 赞同
选好模型和最优化的算法。从最简单和常见的模型开始(logistic regression,decision tree ,KNN等等);MATLAB里的分类器用的最优化算法基本都是很sophisticated的,简单的梯度下降什么的肯定搞不过人家的。
准备好测试用的程序和数据,包括测试在训练数据和测试数据上的误差,画learning curve,ROC曲线啦,etc。这些测试结果就像仪表盘一样,让你清楚自己现在所处的情况。
cross validation (n-fold, loocv,etc)+ grid search 来选参数,libsvm 就是这么做的。(跑程序的时候你可以去看看电影什么的)
不过你这个是二维的特征啊,直接画个图出来看看呗。
1 发布于
2014-04-26 添加评论
感觉语言选好自己喜欢的就可以啦...不过还是推荐python现在theano,scikit-learn什么的都很好用.
我觉得要先理解一些基础概念,知道为什么这么做
理解了的话就可以尽量参考一下已有的代码(对象和类的定义)
然后试着"想象一下"矩阵运算是怎么操作的,用手多写写shape之间转换关系?
应该还要有一台运算速度快的电脑吧
最主要还是理解概念,为什么这么做,这么做会怎么样吧
推荐Andrew Ng的Cousera课程
目前正好讲到了机器学习系统设计和修复~
0 发布于
2014-04-29 添加评论
胡国华、Michael
Jackson 赞同
Python?讨厌它的代码采取的那种缩进格式!!
2 发布于
2014-04-26 2
条评论 感谢
更多
张三皮、王高斌、mwcc 赞同
既然你已经知道 MATLAB 有这个功能了,那么就看看 MATLAB 的帮助文档是怎么实现这个算法的吧。
-------------接下来是黑 MATLAB 的分割线---------------
哈哈,看不到源代码吧,哈哈,MATLAB 是闭源软件!还不趁早用 Python!
3 发布于
2014-04-26 7
条评论
陈应佳、匿名用户、Michael
Jackson 赞同
个人体会:补充一些其他的
简单算法多用别人的程序,然而以后题主需要写别人没有现成的复杂的程序的时候,有这么几点个人体会:
1、很多算法是基于数学优化设计的,存在优化目标,比如概率模型里的最大似然估计或最大后验,然后使用迭代的算法(EM,梯度下降,牛顿法等等)进行优化,因此在迭代的过程中可以把优化的目标输出出来,看看是不是真的得到了优化。
2、有的时候优化了没错但优化的时候就优化到NAN去了(写的Java)...这种时候需要采用倒推的方法一步一步回溯,看是哪里出现了第一个NAN,是不是对应的求解公式有没有写错,尤其是数学公式里的各种下标有没有弄混。
3、如之前各位答案说的,把中间结果画出来看看
4、机器学习算法调试确实是一个很难的问题,记得以前看过一个段子说某deep learning大牛设计了算法号称有性能提升,然后开源了代码发了论文,结果被人检查出来代码里有错误,把bug改了之后性能就下降了。不知道是谁是真是假...
不知道题主说的适用性和可靠性是什么意思。运行效率的话,我认为更多的是对数据结构和算法的理解,对算法复杂度的分析和优化,以及编程的优化,需要题主多多练习编程。
3 发布于
2014-04-27 添加评论
守望孤独、Michael
Jackson 赞同
最近在研究最小二乘支持向量机,可以看看支持向量机(SVM)的资料/article/1350687.html
2 发布于
2014-05-02 添加评论
蛋丁、张三皮 赞同
学习一下Learning Theory,了解bias和variance的区别以及产生原因对设计好的feature,以及debug ML算法非常重要。
如果英语比较好的话,强烈推荐看一下Stanford教授Andrew Ng关于应用以及debug ML算法的建议 (slides在这里)。这是Stanford计算机系Machine
Learning课程的材料,这里面的提供的方法在实际使用ML算法的过程中很有效。
2 发布于
2014-05-03 添加评论
Michael Jackson 赞同
那些代码其实一点也不抽象,必须理解他们到非常不抽象的地步,并且深刻理解课题,以及课题和这些代码的关系。ML的结果经常会有很多难以理解的时候,只能多看多想, 有时候要换换features 能得到更好的结果。但是一切的根源来自对问题的深刻理解。
1 发布于
2014-04-26 添加评论
Michael Jackson 赞同
<<Machine learning A Probabilistic Perspective>>超详细的机器学习书(我在研习中),代码在github上,网址在书的介绍中,基本全是matble实现的,有些有c/c++。BTW,关注机器学习方面大牛的微博Twitter、github、blog etc,有些问题他们从上往下看,比我们要清楚的多,也好理解的多。Ps:我是菜鸟,努力学习。
书名怎么会消失呢。。
1 编辑于
2014-04-27 2
条评论
cross validation
0 发布于
2014-04-26 添加评论
自己编写一个test的数据,随即值的种子设成固定的,用来检验程序有没有写对
0 发布于
2014-05-02 添加评论
熟练使用CVX, 可以在一定程度上检查机器学习算法的中间输出.
0 发布于
2015-04-08 添加评论 感谢
更多
原文地址:http://m.zhihu.com/question/23553643
对于这种数据处理的程序不是很熟悉,所以很是费劲,而这个作业数据只是两维的特征,最后出来的效果还是不如matlab自带的程序。
深感机器学习的算法非常抽象,而且实际实现时,有很多细节资料上没有提到。
而且如果要优化算法效率、提高适用性和可靠性,更是要对算法理解很透彻,感觉这点很难,因为对数学要求特别高,而且数据特征维数大了,根本不知道该如何调试·····
求高人们指点一二!!修改
举报
1
条评论 分享 • 邀请回答
21 个回答

grapeot,专注抠腚二十年
Joey Teng、王宇恒、你好凯蒂 等87 人赞同
机器学习方向的博士生,个人有几点体会。
1. 尽最大可能复用别人的代码。哪怕编译等等很麻烦,也可以在调试上省很多很多时间。血的教训。
2. 多把数据可视化出来,很多问题你看数字很难有直观感受,但往往一画出来就会发现哪里错了。这在高维数据下尤其明显。
3. 调试的时候和普通程序一样,看到结果不对就逆推,找到问题是从哪个地方开始引入,从哪句话开始实际数值和你的期待不一样的。定位问题就成功了一大半。可以用非常简单的数据代入验证,这样你也知道正确的结果是什么。
4. 关于工具的选择,原则实是先确认算法是对的,再调优实现。具体说先用matlab/python之类方便可视化的工具快速迭代找到一个能得到正确结果的算法。然后再用c++/mex优化速度。否则一个跑的很快的屎还是一坨屎。
87 发布于
2014-04-26 13
条评论

评委同学,立场不该影响对事实的判断。
函阵、YaoWu、王海鹏 等 33 人赞同
作为一个纯做机器学习,主要搞probabilistic graphical model的苦逼Ph.D,大多数时间实际上是在推公式好吧摔!!!anyway,说说自己编写、调试机器学习程序的经验吧。
1,要用print !
大多数机器学习方法是优化问题,一般是迭代求解,算法一般就是gradient descent的各种变种。自己编写的时候,尽量打印每轮迭代时model的信息,包括目标函数值、训练数据上的错误率,甚至测试数据上的错误率,probabilistic model经常打印log-likelihood。举个例子,如果迭代中,目标函数值增加了(diverge
了),先检查是否是learning rate设的过大(最常见),gradient的正负搞反了(也很常见。。),如果不是,基本就要断点调试了。再比如,如果训练错误率一直在下降,测试错误率开始上升,那就是过拟合了。
2,先在toy/simulated的data上测试通过
real data一般有不少预处理的问题,数据本身也有很多不符合模型假设的“个性”,很多时候,会影响你对机器学习模型、算法本身正确性的判断。最重要的,这样调试大大节省了时间。
3,不要吝啬注释
机器学习核心算法的程序,通常非常短小,但是如果没有注释,可读性会很差。因为代码背后是公式。对绝大多数凡人来说,公式本身就已晦涩,从代码里面读出公式,搞清楚程序在干吗,更是坑爹。所以,为了自己跟他人的身心健康,请加注释。
4,如果专注机器学习算法本身,复用别人的代码要慎重。
当你自己提了一个模型、算法,想投NIPS、ICML、AIStats、UAI,需要对比前人的算法时,如果不是特别难,建议自己动手实现前人的方法(实际上,这是当年老板给我的忠告)。。首先,如果你只是把别人的代码当做一个黑盒子,很难得到自己的方法为啥好,别人的方法为啥差的insight,如果不幸自己的方法差,也很难找到改进自己方法的窍门。再者,最新提出的方法,一般没有可用的高质量代码。注意!!如果你的主要目标不是提出新的算法,而是想在某个应用上做出好的正确率,那么按 @grapeot说的,尽可能复用别人的代码。
5,先编写简单的机器学习算法练手
比如logistic regression, 比如EM for Gaussian Mixture, 比如SVM。先用最简单的实现。logistic regression就用gradient descent,linear svm就用sub-gradient decent。加了各种kernel的svm就用naive的quadratic programming,熟悉一些了,也可以用SMO。磨刀不误砍柴工,能学到很多。
6, 机器学习程序中的小bug很难发现
难发现的原因在于,有小bug的程序工作的很好,没有任何错误的征兆~~甚至有些时候,带小bug的程序,会比没bug的程序得到的正确率更高...(有多年ML经验的人,肯定遇到过这样的情况)。原因是小bug会起到某种regularization的作用,防止了过拟合。所以尽人力后,顺其自然吧。。。
p.s.题外话,这个现象曾在12年NIPS的时候,被一个机器学习的大牛Dietterich拿来调侃巨牛Hinton提出的dropout方法。Hinton当时说,如果我的方法work得好,是因为有bug,那一定是世上最好的bug~~因为我的程序总是在赢各种竞赛。。
33 编辑于
2014-06-14 3
条评论

秦杨帆
刘晓彤、GerYoung、张翔 等 9 人赞同
所有机器学习问题都可以转化成一个优化问题,所以先学习优化,特别是凸优化,先看无约束条件的优化,再学有约束条件的优化。你会发现所有分类器都差不多,只是目标方程不一样,约束条件不一样吧了。
9 发布于
2014-05-02 2
条评论

郑梓豪,At
data science team
刘晓彤、ShenLi、Auguste 等 15 人赞同
建议lz去Coursera听几节Machine Learning的课Coursera.org,然后做一下对应的作业。作业就是用MATLAB编的,如果你能把作业里面的代码都理解好了。我觉得应该就算入门了吧~
而且你可以趁此机会熟悉熟悉MATLAB的矩阵化运算,以及其他的常用指令。
至于难不难,我觉得学控制的同学,应该有足够的数学基础(线性代数+概率论)去理解的哈。
同学你也可以参考一下我的代码zihaolucky/Machine-Learning-and-UFLDL ·
GitHub . Lecture和code都有了。不过,如果你要跟那门课,还是自己完成吧,有honor code规则的哈。
至于vczh同学提到的“那些模型训练出来的系数是不可理解的,调试他们干什么……”.确实如此,机器学习,就是学习出那些参数,以最好地贴近数据模式啊。这个是算法。需要优化的,可能是你程序的速度。
15 编辑于
2014-04-26 添加评论

王丰,Data
is power.
beyond love、caporion、周冠权 等59 人赞同
首先关于语言的选择,个人认为还是Matlab比较合适,因为目前在学术领域,用Matlab的人感觉还是相对多一点的。题主如果在写代码的过程中遇到了问题,也比较方便向别人请教。目测开源的机器学习库也是Matlab更多。当然如果对程序速度有严格要求,就可以考虑C++。
其次对于题主你来讲,最重要的问题是要明确自己的目的。
说实话,如果只是一个课程作业的话,完全没必要深入到很多算法的细节,只要了解了算法的大体流程即可,再选择别人实现好的算法,多次测试,一般结果是可以让人满意的。
但如果题主是想继续在机器学习领域深入研究的话,了解算法细节就是必不可少的了。不过即便这样,还是要从简单入手逐渐加深难度。否则学习曲线太陡,一般人都hold不住。
(另外自己感觉机器学习还算是入门容易精通难的,深入研究充满了大量细节和数学,研究者们也在一直outperform其他人……( ̄ε ̄;))
所以,综上,题主最好从简单入手!( ̄ε ̄;)
先了解基本算法思路,再使用现成代码进行实验!
在此,我强烈推荐一个模式识别库 PRTools5!在这里下载:Software - Pattern Recognition
Tools,作者叫R.P.W.
Duin。
这个库最大的优点就是简单方便,而且实现了大量大量常用算法,对于初学者,完全可以上手就用,避免陷入细节的泥潭。而且都经过大量测试,基本没有严重bug。简单举几个栗子:
首先,需要构造两个数据集:
A = prdataset(X1, Y1) B = prdataset(X2, Y2)
其中,prdataset是PRTools5中的函数,目的就是构造数据集……
X是训练数据矩阵,每一行是一个数据点(一个object),每列是一个特征(feature)。Y是一个列向量,代表数据X的标签。怎么样,简单吧……
之后,就可以进行分类(classification)了!
w1 = knnc(A); w2 = qdc(A); w3 = svc(A); w4 = naivebc(A); % ......
其中,w1, w2, w3, w4 就是训练好的分类器了。knnc是knn…qdc是Quadratic Bayes Normal Classifier,svc是svc……naivebc是Naive Bayes。
至于各种参数呢?函数都已经自动选择了,当然题主根据自己要处理的具体问题,也完全可以手动指定。
之后就可以测试结果了,我们选择B作为测试集。
e1 = testd(B*w1); e2 = testd(B*w2); e3 = testd(B*w3); e4 = testd(B*w4); % ......
这里的e就是classification error……当然也可以选择其他函数,使用其他判断标准。
但鉴于题主的数据是二维的,因此可视化是一个很好很强大的手段。(二维的!这年头哪还有这么好的事└(T_T;)┘……)。以下举例:
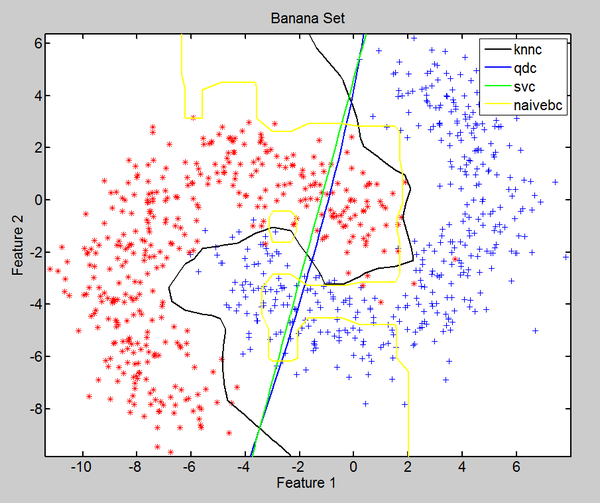
A = gendatb([50 50]); B = gendatb([400 400]);
此处使用了PRTools5自带的数据生成函数,A、B都是二维数据,2 classes,每类中有50(400)个objects。
w1 = knnc(A); w2 = qdc(A); w3 = svc(A); w4 = naivebc(A); % ......
……不用解释。
scatterd(B); % 做测试数据散点图 hold on h1 = plotc(w1); % 做出分类器边界图,以下类似 h2 = plotc(w2, 'b'); h3 = plotc(w3, 'g'); h4 = plotc(w4, 'y'); legend([h1, h2, h3, h4], 'knnc', 'qdc', 'svc', 'naivebc')
结果如下:
这时真相大白,原来gendatb是生成banana形状的数据…………而且显然,对于这种数据,knn的效果最好。
总之PRTools5是一个非常强大的模式识别库。
而且这时再看,机器学习也就不麻烦且不抽象了吧~~
59 编辑于
2014-05-01 5
条评论

Jason
Gu,
北落、陈应佳、陈狄 等17 人赞同
不知道题主要写编写的是哪个分类器,不同分类器的编写复杂度相差非常大。像KNN,几句话就能写出来,而像SVM,要复杂得多。
相对于其它语言,我觉得MATLAB是我遇到的最容易上手的。最大的优势是方便查看各变量值与调试。
说说我认为一些有用的技巧:
1. 比较复杂的算法,可以先用数学语言把大概流程写出来,这样编程的时候有个参照。对算法流程非常清楚,是将它代码实现的必要条件。
2. 由简入难。先实现算法的一些基本功能,而扩展功能留到后面做。
3. 边写边调试,尤其是自己对编程语言不太熟悉的情况下,犯错的机率非常大。如果写了几百行再调试,那绝对是个巨大的工程。所以建议每写个几行,就F5运行下,查看下各个变量的值,看与自己想像的是否一样。这样便于即时发现问题,改正问题。
另外,刚开始编写,不建议把代码写在function里,然后用主程序调用,这样不方便查看变量值与调试。我倾向先在主程序里把代码功能实现,调试确定没问题了,再把它转移到一个function里,保持主程序代码的简洁。当然这种方法对Python, C之类的语言没有用处。
4. 自己构造一个简单的样例来调试程序。一个简单的样例,自己能清楚的判断程序输出结果是否正确。而如果是很复杂的样例,判断起来就麻烦得多。
暂时想到的就这么多,希望能有帮助。
17 发布于
2014-04-26 3
条评论

Furukawa
Zhang,声纹语音识别研究者•工程师
Michael Jackson 赞同机器学习coding比较蛋疼啊
我比较笨 一般是这么搞得
1,找个别人写好的程序1先跑,这时候一般都是matlab等好调试的语言 跑对了ok下一步
2,理解程序1内在算法,根据需求改进成自己的版本2,语言跟上面相同,这个如果效果还行,就可以作为正确答案
3,按照自己的版本2改写成c等高效语言,然后跟版本2每一步每个值对每个值的跟踪调试,遇到随机数的地方就设置成一样的值,挑对了再改回去,保证每个地方跟正确答案一致,这样出来的东西应该正确性就可以保证了。就是过程有点蛋疼了
1 发布于
2015-03-26 1
条评论

Stark
Einstein,躬耕陇亩,不废天下志
安如磐石 赞同弄出代价函数,选择最优化的方法,就这样。过程中,要想办法算出参数的梯度
1 发布于
2015-01-26 添加评论

vczh,专业造轮子 https://github.com/vczh-libraries
Paul Meng、于鑫、安迪 等9 人赞同
你搞机器学习的时候,那些模型训练出来的系数是不可理解的,调试他们干什么……
9 发布于
2014-04-26 6
条评论
何磊,正在刷
MLAPP [进度 66%]
Michael Jackson 赞同选好模型和最优化的算法。从最简单和常见的模型开始(logistic regression,decision tree ,KNN等等);MATLAB里的分类器用的最优化算法基本都是很sophisticated的,简单的梯度下降什么的肯定搞不过人家的。
准备好测试用的程序和数据,包括测试在训练数据和测试数据上的误差,画learning curve,ROC曲线啦,etc。这些测试结果就像仪表盘一样,让你清楚自己现在所处的情况。
cross validation (n-fold, loocv,etc)+ grid search 来选参数,libsvm 就是这么做的。(跑程序的时候你可以去看看电影什么的)
不过你这个是二维的特征啊,直接画个图出来看看呗。
1 发布于
2014-04-26 添加评论

Roy薛,Sarah一生推
感觉语言选好自己喜欢的就可以啦...不过还是推荐python现在theano,scikit-learn什么的都很好用.我觉得要先理解一些基础概念,知道为什么这么做
理解了的话就可以尽量参考一下已有的代码(对象和类的定义)
然后试着"想象一下"矩阵运算是怎么操作的,用手多写写shape之间转换关系?
应该还要有一台运算速度快的电脑吧
最主要还是理解概念,为什么这么做,这么做会怎么样吧
推荐Andrew Ng的Cousera课程
目前正好讲到了机器学习系统设计和修复~
0 发布于
2014-04-29 添加评论

来三虎
胡国华、MichaelJackson 赞同
Python?讨厌它的代码采取的那种缩进格式!!
2 发布于
2014-04-26 2
条评论 感谢
更多

肖智博,我不会Matlab,不要再邀请我了
张三皮、王高斌、mwcc 赞同既然你已经知道 MATLAB 有这个功能了,那么就看看 MATLAB 的帮助文档是怎么实现这个算法的吧。
-------------接下来是黑 MATLAB 的分割线---------------
哈哈,看不到源代码吧,哈哈,MATLAB 是闭源软件!还不趁早用 Python!
3 发布于
2014-04-26 7
条评论

王养浩,我不懂机器学习
陈应佳、匿名用户、MichaelJackson 赞同
个人体会:补充一些其他的
简单算法多用别人的程序,然而以后题主需要写别人没有现成的复杂的程序的时候,有这么几点个人体会:
1、很多算法是基于数学优化设计的,存在优化目标,比如概率模型里的最大似然估计或最大后验,然后使用迭代的算法(EM,梯度下降,牛顿法等等)进行优化,因此在迭代的过程中可以把优化的目标输出出来,看看是不是真的得到了优化。
2、有的时候优化了没错但优化的时候就优化到NAN去了(写的Java)...这种时候需要采用倒推的方法一步一步回溯,看是哪里出现了第一个NAN,是不是对应的求解公式有没有写错,尤其是数学公式里的各种下标有没有弄混。
3、如之前各位答案说的,把中间结果画出来看看
4、机器学习算法调试确实是一个很难的问题,记得以前看过一个段子说某deep learning大牛设计了算法号称有性能提升,然后开源了代码发了论文,结果被人检查出来代码里有错误,把bug改了之后性能就下降了。不知道是谁是真是假...
不知道题主说的适用性和可靠性是什么意思。运行效率的话,我认为更多的是对数据结构和算法的理解,对算法复杂度的分析和优化,以及编程的优化,需要题主多多练习编程。
3 发布于
2014-04-27 添加评论

杨XX,铲屎官
守望孤独、MichaelJackson 赞同
最近在研究最小二乘支持向量机,可以看看支持向量机(SVM)的资料/article/1350687.html
2 发布于
2014-05-02 添加评论

Denzel
Zhang
蛋丁、张三皮 赞同学习一下Learning Theory,了解bias和variance的区别以及产生原因对设计好的feature,以及debug ML算法非常重要。
如果英语比较好的话,强烈推荐看一下Stanford教授Andrew Ng关于应用以及debug ML算法的建议 (slides在这里)。这是Stanford计算机系Machine
Learning课程的材料,这里面的提供的方法在实际使用ML算法的过程中很有效。
2 发布于
2014-05-03 添加评论

Sean
Go,思维有缺陷
Michael Jackson 赞同那些代码其实一点也不抽象,必须理解他们到非常不抽象的地步,并且深刻理解课题,以及课题和这些代码的关系。ML的结果经常会有很多难以理解的时候,只能多看多想, 有时候要换换features 能得到更好的结果。但是一切的根源来自对问题的深刻理解。
1 发布于
2014-04-26 添加评论

郑晶亮,没什么可说的
Michael Jackson 赞同<<Machine learning A Probabilistic Perspective>>超详细的机器学习书(我在研习中),代码在github上,网址在书的介绍中,基本全是matble实现的,有些有c/c++。BTW,关注机器学习方面大牛的微博Twitter、github、blog etc,有些问题他们从上往下看,比我们要清楚的多,也好理解的多。Ps:我是菜鸟,努力学习。
书名怎么会消失呢。。
1 编辑于
2014-04-27 2
条评论

versatran01
cross validation0 发布于
2014-04-26 添加评论

回笼觉教主
自己编写一个test的数据,随即值的种子设成固定的,用来检验程序有没有写对0 发布于
2014-05-02 添加评论
匿名用户
熟练使用CVX, 可以在一定程度上检查机器学习算法的中间输出.0 发布于
2015-04-08 添加评论 感谢
更多
原文地址:http://m.zhihu.com/question/23553643

相关文章推荐
- 几个DSP高手的经验介绍,编写基于DSP程序的注意事项
- 几个DSP高手的经验介绍,编写基于DSP程序的注意事项
- ZZ]几个DSP高手的经验介绍,编写基于DSP程序的注意事项[转帖]
- Spark程序开发-环境搭建-程序编写-Debug调试-项目提交
- keil程序在外部RAM中调试的问题总结(个人的一点经验总结)
- 编写一个基于控制台的聊天室程序 推荐
- JAVA程序编写经验
- [IOS]从零开始搭建基于Xcode7的IOS开发环境和免开发者帐号真机调试运行第一个IOS程序HelloWorld
- 用python + hadoop streaming 编写分布式程序的本地调试方法
- window上eclipse调试基于hadoop2.7.3的MapReduce程序
- 基于Asterisk的VoIP开发指南——(2)Asterisk AGI程序编写指南
- 编写Java程序,计算数字可以被哪些数字整除。
- 自己编写ASSERT()宏(对调试程序很有帮助)
- 需要求三个长方体的体积,请编写一个基于对象的程序
- 汇编试验五:编写、调试具有多个段的程序
- 重温最大流经验之巧用int 3下断点调试程序 and 快速定位死循环
- 基于Qt编写TCP通讯程序测试程序之超级详细教程
- vb编写串口调试程序
- [Reomting Debug] 巧用VS 的remote debug 功能远程调试程序 经验分享.
- 基于TX2440开发板在ADS1.2中编写LED的驱动(GPIO的使用)裸机程序