Scraping Web Pages With R
2015-04-16 16:45
453 查看
(This article was first published on OUseful.Info, the blog... » Rstats, and kindly contributed to
R-bloggers)
One of the things I tend to avoid doing in R, partly because there are better tools elsewhere, is screenscraping. With the release of the new
rvest package, I thought I’d have a go at what amounts to one of the simplest webscraping activites – grabbing HTML tables out of webpages.
The tables I had in my sights (when I can actually find them…) are the tables that appear on the newly designed FIA website that describe a range of timing results for F1 qualifying and races [quali
example,
race example].
Inspecting an example target web page, whilst a menu allows you to select several different results tables, a quick look at the underlying HTML source code reveals that all the tables relevant to the session (that is, a particular race, or complete qualifying
session) are described within a single page.
So how can we grab those tables down from a target page? The following recipe seems to do the trick:
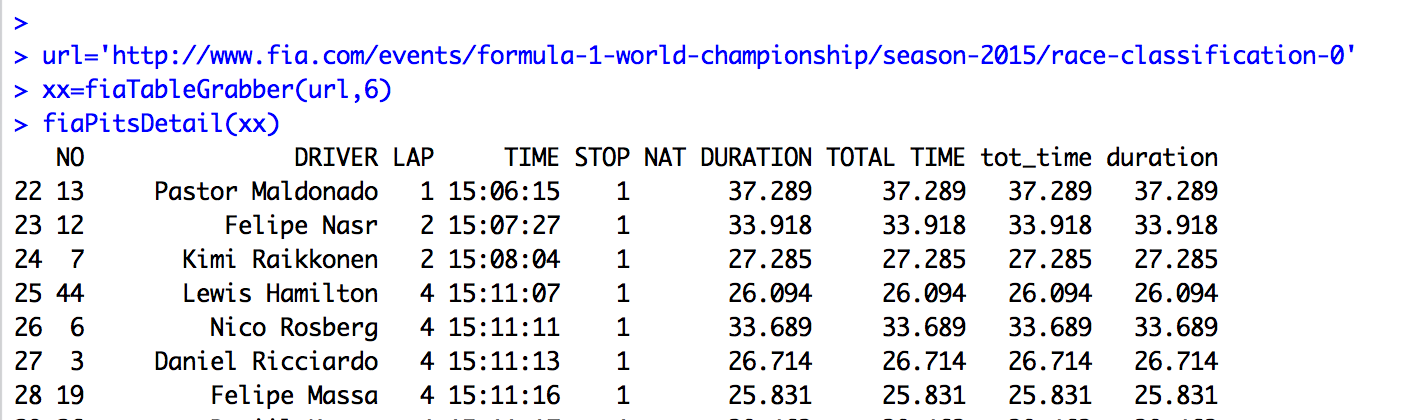
The fiaTableGrabber() grabs a particular table from a page with a particular URL (I really should grab the page separately and then extract whatever table from the fetched page, or at least cache the page (unless there is a cacheing option built-in?)
Depending on the table grabbed, we may then need to tidy it up. I hacked together a few sketch functions that tidy up (and remap) column names, convert “natural times” in minutes and seconds to seconds equivalent, and in the case of the race pits data, separate
out two tables that get merged into one.
So for example:

I’m still not convinced that R is the most natural, efficient, elegant or expressive language for scraping with, though…
PS In passing, I note the
release of the readxl Excel reading library (no external-to-R dependencies, compatible with various flavours of Excel spreadsheet).
PPS Looking at the above screenshot, it strikes me that if we look at the time of day of and the duration, we can tell if there is a track position (at least) change in the pits… So for example, ROS goes in at 15:11:11 with a 33.689 stop and RIC goes in
at 15:11:13 with a 26.714. So ROS enters the pits ahead of RIC and leaves after him? The following
lap chart from f1fanatic perhaps reinforces this view?

R-bloggers)
One of the things I tend to avoid doing in R, partly because there are better tools elsewhere, is screenscraping. With the release of the new
rvest package, I thought I’d have a go at what amounts to one of the simplest webscraping activites – grabbing HTML tables out of webpages.
The tables I had in my sights (when I can actually find them…) are the tables that appear on the newly designed FIA website that describe a range of timing results for F1 qualifying and races [quali
example,
race example].
Inspecting an example target web page, whilst a menu allows you to select several different results tables, a quick look at the underlying HTML source code reveals that all the tables relevant to the session (that is, a particular race, or complete qualifying
session) are described within a single page.
So how can we grab those tables down from a target page? The following recipe seems to do the trick:
Depending on the table grabbed, we may then need to tidy it up. I hacked together a few sketch functions that tidy up (and remap) column names, convert “natural times” in minutes and seconds to seconds equivalent, and in the case of the race pits data, separate
out two tables that get merged into one.
I’m still not convinced that R is the most natural, efficient, elegant or expressive language for scraping with, though…
PS In passing, I note the
release of the readxl Excel reading library (no external-to-R dependencies, compatible with various flavours of Excel spreadsheet).
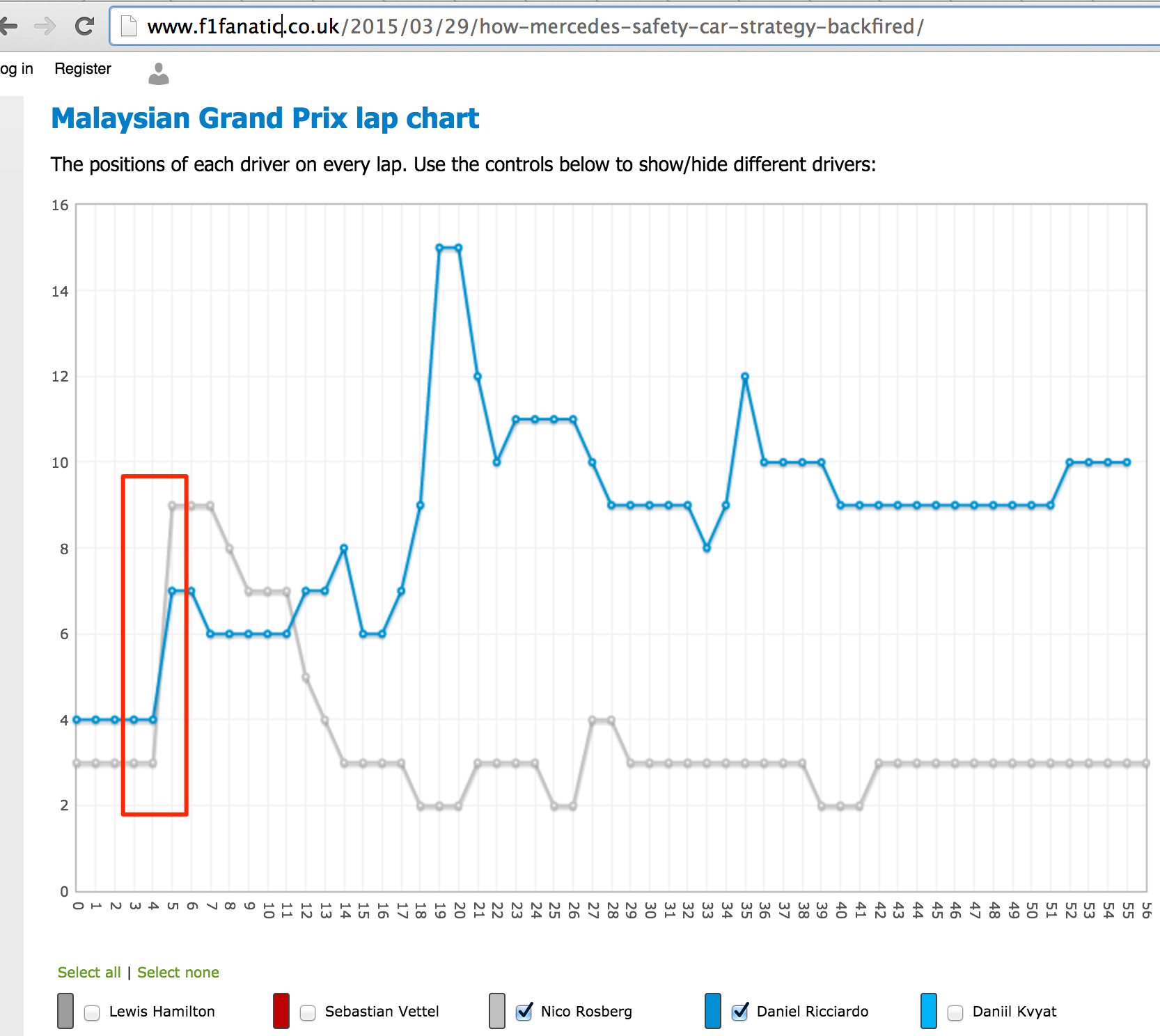
PPS Looking at the above screenshot, it strikes me that if we look at the time of day of and the duration, we can tell if there is a track position (at least) change in the pits… So for example, ROS goes in at 15:11:11 with a 33.689 stop and RIC goes in
at 15:11:13 with a 26.714. So ROS enters the pits ahead of RIC and leaves after him? The following
lap chart from f1fanatic perhaps reinforces this view?

相关文章推荐
- Scraping JavaScript webpages with webkit | WebScraping.com
- 使用R语言和XML包抓取网页数据-Scraping data from web pages in R with XML package
- Scraping JavaScript webpages with webkit | WebScraping.com
- [翻译]<Web Scraping with Python>Chapter 2.高级HTML解析
- Web Scraping with Python:使用 Selenium 给当前网页截屏
- 网络爬虫 HTML的高级解析 <web scraping with python>第二章
- LoadRunner levels of integration with web pages
- VS2005web应用程序项目教程(3)Building Pages with VS 2005 Web Application Projects
- view web pages problem with the client jianshe
- Web Scraping with Python 学习笔记9
- [转] Scraping Yahoo! Search with Web::Scraper
- Alter the structure of web pages with JavaScript
- Displaying Data in a Chart with ASP.NET Web Pages (Razor)
- Web Scraping with Python 读书笔记
- [Node.js] Web Scraping with Pagination and Advanced Selectors
- 《Web Scraping with Python》读书笔记
- LoadRunner levels of integration with web pages
- Web Scraping with Python: 使用 Python 爬 CSDN 博客
- Web Scraping with Python 学习笔记6
- Web Scraping with Python: 使用 Python 下载 CSDN 博客图片