JStorm之Nimbus简介
2015-04-16 16:02
302 查看
一、简介
JStorm集群包含两类节点:主控节点(Nimbus)和工作节点(Supervisor)。其分别对应的角色如下:1. 主控节点(Nimbus)上运行Nimbus Daemon。Nimbus负责接收Client提交的Topology,分发代码,分配任务给工作节点,监控集群中运行任务的状态等工作。Nimbus作用类似于Hadoop中JobTracker。
2. 工作节点(Supervisor)上运行Supervisor Daemon。Supervisor通过subscribe Zookeeper相关数据监听Nimbus分配过来任务,据此启动或停止Worker工作进程。每个Worker工作进程执行一个Topology任务的子集;单个Topology的任务由分布在多个工作节点上的Worker工作进程协同处理。
Nimbus和Supervisor节点之间的协调工作通过Zookeeper实现。此外,Nimbus和Supervisor本身均为无状态进程,支持Fail Fast;JStorm集群节点的状态信息或存储在Zookeeper,或持久化到本地,这意味着即使Nimbus/Supervisor宕机,重启后即可继续工作。这个设计使得JStorm集群具有非常好的稳定性。
前面介绍了JStorm中节点状态信息保存在Zookeeper里面,Nimbus通过向Zookeeper写状态信息分配任务,Supervisor通过从Zookeeper订阅相关数据领取任务,同时Supervisor也定期发送心跳信息到Zookeeper,使得Nimbus可以掌握整个JStorm集群的状态,从而可以进行任务调度或负载均衡。ZooKeeper使得整个JStorm集群十分健壮,任何节点宕机都不影响集群任务,只要重启节点即可。
Zookeeper上存储的状态数据及Nimbus/Supervisor本地持久化数据涉及到的地方较多,详细介绍Nimbus之前就上述数据的存储结构简要说明如下(注:引用自[5]http://xumingming.sinaapp.com/)。

图1 JStorm存储在Zookeeper中数据说明
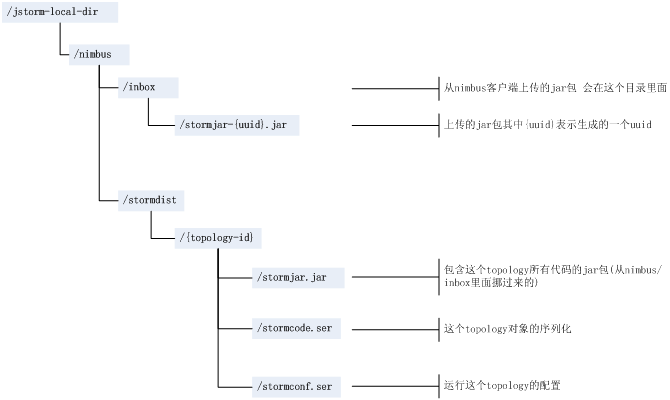
图2 Nimbus本地数据说明
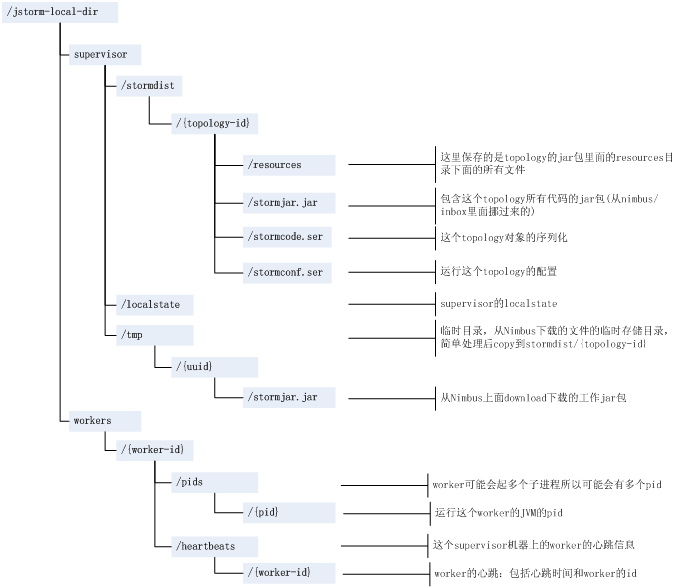
图3 Supervisor本地数据说明
二、系统架构与原理
Nimbus做三件事情:1、接收Client提交Topology任务;
2、任务调度;
3、监控集群任务运行状况。
前面已经提到,Nimbus通过向Zookeeper写数据完成任务分配,通过读Zookeeper上相关状态信息监控集群中任务的运行状态,所以与Nimbus直接发生交互仅Client和Zookeeper。如下图示。
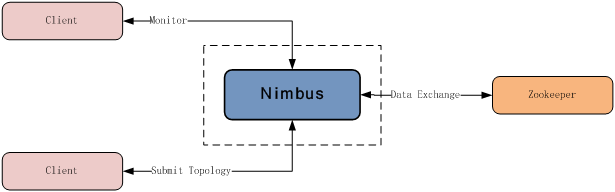
三、实现逻辑与代码剖析
以jstorm-0.7.1为例,Nimbus相关实现在jstorm-server/src/main/java目录的com.alipay.dw.jstorm.daemon.nimbus包里。Nimbus Daemon的启动入口在NimbusServer.java。
1.Nimbus启动
Nimbus Daemon进程启动流程如下:1、根据配置文件初始化Context数据;
2、与Zookeeper数据同步;
3、初始化RPC服务处理类ServiceHandler;
4、启动任务分配策略线程;
5、启动Task的Heartbeat监控线程;
6、启动RPC服务;
7、其他初始化工作。
Nimbus的详细启动逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | @SuppressWarnings("rawtypes")
private void launchServer(Map conf) throws Exception {
LOG.info("Begin to start nimbus with conf " + conf);
//1.检查配置文件中是否配置为分布式模式
StormConfig.validate_distributed_mode(conf);
//2.注册主线程退出Hook现场清理(关闭线程+清理数据)
initShutdownHook();
//3.新建NimbusData数据,记录30s超时上传下载通道Channel/BufferFileInputStream
data = createNimbusData(conf);
//4.nimbus本地不存在的stormids数据如果在ZK上存在则删除,其中删除操作包括/zk/{assignments,tasks,storms}相关数据
NimbusUtils.cleanupCorruptTopologies(data);
//5.启动Topology分配策略
initTopologyAssign();
//6.初始化所有topology的状态为startup
initTopologyStatus();
//7.监控所有task的heartbeat,一旦发现taskid失去心跳将其置为needreassign 1次/10s
initMonitor(conf);
//8.启动cleaner线程,默认600s扫描一次,默认删除3600s没有读写过的jar文件
initCleaner(conf);
//9.初始化ServiceHandler
serviceHandler = new ServiceHandler(data);
//10.启动rpc server
initThrift(conf);
} |
2.Topology提交
JStorm集群启动完成后,Client可向其提交Topology。jstorm-0.7.1源码目录jstorm-client/src/main/java下包backtype.storm为用户提供向集群提交Topology的StormSubmitter.submitTopology方法。提交Topology在Client/Nimbus两端都会做相关的处理。Client端提交Topology分两步完成:
1)打包Topology计算逻辑代码jar提交给Nimbus,上传到Nimbus目录$jstorm_local_dir/nimbus/inbox/stormjar-{$randomid}.jar;其中randomid是Nimbus生成的随机UUID;
2)Client通过RPC向Nimbus提交Topology DAG及配置信息;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 2425 | public static void submitTopology( String name, Map stormConf, StormTopology topology) throws AlreadyAliveException, InvalidTopologyException { if(!Utils.isValidConf(stormConf)) { throw new IllegalArgumentException("Storm conf is not valid."); } stormConf = new HashMap(stormConf); stormConf.putAll(Utils.readCommandLineOpts()); Map conf = Utils.readStormConfig(); conf.putAll(stormConf); try { String serConf = JSONValue.toJSONString(stormConf); if(localNimbus!=null) { LOG.info("Submitting topology " + name + " in local mode"); localNimbus.submitTopology(name, null, serConf, topology); } else { //1.向Nimbus提交jar包 submitJar(conf); NimbusClient client = NimbusClient.getConfiguredClient(conf); try { LOG.info("Submitting topology " + name + " in distributed mode with conf " + serConf); //2.提交topology DAG及序列化后的配置信息serconf(json) client.getClient().submitTopology(name, submittedJar, serConf, topology); } finally { client.close(); } } LOG.info("Finished submitting topology: " + name); } catch(TException e) { throw new RuntimeException(e); } } |
Nimbus端接收到Client提交上来的Topology计算逻辑代码jar包后如前面所述将jar包暂存在目录$jstorm_local_dir/nimbus/inbox/stormjar-{$randomid}.jar;
Nimbus端接收到Client提交上来的Topology DAG和配置信息后:
1)简单合法性检查;主要检查是否存在相同TopologyName的Topology,如果存在,拒绝Topology提交。
2)生成topologyid;生成规则:TopologyName-counter-currenttime;
3)序列化配置文件和Topology代码;
4)Nimbus本地准备运行时所需数据;
5)向Zookeeper注册Topology和Task;
6)将Tasks压入分配队列等待TopologyAssign分配;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 2425 | @SuppressWarnings("unchecked")
@Override
public void submitTopology(String topologyname, String uploadedJarLocation, String jsonConf, StormTopology topology)
throws AlreadyAliveException, InvalidTopologyException, TException {
……
try {
//1.检测topologyName是否已经存在,如果存在相同名称的topology则拒绝提交
checkTopologyActive(data, topologyname, false);
}
……
//2.根据topologyname构造topologyid(=topologyname-$counter-$ctime)
int counter = data.getSubmittedCount().incrementAndGet();
String topologyId = topologyname + "-" + counter + "-"
+ TimeUtils.current_time_secs();
//3.根据输入参数jsonConf重组配置数据
Map serializedConf = (Map) JStormUtils.from_json(jsonConf);
if (serializedConf == null) {
throw new InvalidTopologyException("");
}
serializedConf.put(Config.STORM_ID, topologyId);
Map stormConf;
try {
stormConf = NimbusUtils.normalizeConf(conf, serializedConf, topology);
} catch (Exception e1) {
throw new TException(errMsg);
}
Map totalStormConf = new HashMap(conf);
totalStormConf.putAll(stormConf);
StormTopology newtopology = new StormTopology(topology);
//4.检查topology的合法性,包括componentid检查和spout/bolt不能为空检查
// this validates the structure of the topology
Common.validate_basic(newtopology, totalStormConf, topologyId);
try {
StormClusterState stormClusterState = data.getStormClusterState();
//5.在nimbus的本地准备所有topology相关数据
//包括$storm-local-dir/nimbus/stormdist/topologyid/{tormjar.jar,stormcode.ser,stormconf.ser}
// create $storm-local-dir/nimbus/topologyId/xxxx files
setupStormCode(conf, topologyId, uploadedJarLocation, stormConf,
newtopology);
//6.向zk写入task信息
//6.1新建目录$zkroot/taskbeats/topologyid
//6.2写文件$zkroot/tasks/topologyid/taskid 内容为对应task的taskinfo[内容:componentid]
// generate TaskInfo for every bolt or spout in ZK
// $zkroot /tasks/topoologyId/xxx
setupZkTaskInfo(conf, topologyId, stormClusterState);
//7.任务分配事件压入待分配队列
// make assignments for a topology
TopologyAssignEvent assignEvent = new TopologyAssignEvent();
assignEvent.setTopologyId(topologyId);
assignEvent.setScratch(false);
assignEvent.setTopologyName(topologyname);
TopologyAssign.push(assignEvent);
}
……
} |
3.任务调度
Topology被成功提交后会压入Nimbus中TopologyAssign的FIFO队列,后台任务调度线程对队列中的Topology逐个进行任务调度。从0.9.0开始,JStorm提供非常强大的调度功能,基本上可以满足大部分的需求,同时支持自定义任务调度策略。JStorm的资源不再仅是Worker的端口,而从CPU/Memory/Disk/Net等四个维度综合考虑。
jstorm-0.7.1的任务调度策略仍主要以Worker端口/Net单一维度调度。
任务调度需要解决的问题是:如何将Topology DAG中各个计算节点和集群资源匹配,才能发挥高效的逻辑处理。0.7.1的策略是:
1、将集群中的资源排序:按照空闲worker数从小到大的顺序重排节点,节点内部按照端口大小顺序排列;
2、Topology中需要分配的任务(重新分配的Topology时大多任务不再需要分配)逐个映射到上述排好序的资源里。
任务调度核心逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 2425 | public static List sortSlots( Set allSlots, int needSlotNum) { Map> nodeMap = new HashMap>(); // group by first // 按照节点进行组织Map> : nodeid -> ports for (NodePort np : allSlots) { String node = np.getNode(); List list = nodeMap.get(node); if (list == null) { list = new ArrayList(); nodeMap.put(node, list); } list.add(np); } //每一个nodeid按照端口的大小进行排序 for (Entry> entry : nodeMap.entrySet()) { List ports = entry.getValue(); Collections.sort(ports); } //收集所有的workers List> splitup = new ArrayList>(nodeMap.values()); //按照节点可用worker数从小到大排序 //1.assignTasks-Map supInfos //2.availSlots : splitup/List> Collections.sort(splitup, new Comparator> () { public int compare(List o1, List o2) { return o1.size() - o2.size(); } }); /* * splitup目前的状态(A-F表示节点,1-h表示端口) * |A| |B| |C| |D| |E| |F| *--|---|---|---|---|---|-- * |1| |2| |3| |4| |5| |6| * |7| |8| |9| |0| |a| * |b| |c| |d| |e| * |f| |g| * |h| * 经过interleave_all收集到的sortedFreeSlots为: * 1-2-3-4-5-6-7-8-9-0-a-b-c-d-e-f-g-h */ List sortedFreeSlots = JStormUtils.interleave_all(splitup); //比较sortedFreeSlots.size和needSlotNum的大小分配workers if (sortedFreeSlots.size() needSlotNum return sortedFreeSlots.subList(0, needSlotNum); } |
4.任务监控
初始化Nimbus时后台会随之启动一个称为MonitorRunnable的线程,该线程的作用是定期检查所有运行Topology的任务Tasks是否存在Dead的状态。一旦发现Topology中存在Dead的任务Task,MonitorRunnable将该Topology置为StatusType.monitor,等待任务分配线程对该Topology中的Dead任务进行重新分配。MonitorRunnable线程默认10s执行一次检查,主要逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 2425 | @Override
public void run() {
//1.获取jstorm对zk的操作接口
StormClusterState clusterState = data.getStormClusterState();
try {
// Attetion, here don't check /ZK-dir/taskbeats to
// get active topology list
//2.通过$zkroot/assignments/获取所有需要检查active topology
List active_topologys = clusterState.assignments(null);
if (active_topologys == null) {
LOG.info("Failed to get active topologies");
return;
}
for (String topologyid : active_topologys) {
LOG.debug("Check tasks " + topologyid);
// Attention, here don't check /ZK-dir/taskbeats/topologyid to
// get task ids
//3.通过$zkroot/tasks/topologyid获取组成topology的所有tasks
List taskIds = clusterState.task_ids(topologyid);
if (taskIds == null) {
LOG.info("Failed to get task ids of " + topologyid);
continue;
}
boolean needReassign = false;
for (Integer task : taskIds) {
//4.检查task是否为Dead状态,主要是task心跳是否超时
boolean isTaskDead = NimbusUtils.isTaskDead(data, topologyid, task);
if (isTaskDead == true) {
needReassign = true;
break;
}
}
if (needReassign == true) {
//5.如果Topology里有Dead状态的Task则topology状态置为monitor等待任务分配线程重新分配
NimbusUtils.transition(data, topologyid, false, StatusType.monitor);
}
}
} catch (Exception e) {
// TODO Auto-generated catch block
LOG.error(e.getCause(), e);
}
} |
四、结语
本文简单介绍了Nimbus在整个JStorm系统中扮演的角色,及其实现逻辑和关键流程的源码剖析,希望能够对刚接触JStorm的同学有所帮助。文中难免存在不足和错误,欢迎交流指导。
五、参考文献
[1]Storm社区. http://Storm.incubator.apache.org/[2]JStorm源码. https://github.com/alibaba/jStorm/
[3]Storm源码. https://github.com/nathanmarz/Storm/
[4]Jonathan Leibiusky, Gabriel Eisbruch, etc. Getting Started with Storm.http://shop.oreilly.com/product/0636920024835.do. O’Reilly
Media, Inc.
[5]Xumingming Blog. http://xumingming.sinaapp.com/
[6]量子恒道官方博客. http://blog.linezing.com/

相关文章推荐
- JStorm之Nimbus简介
- JStorm之Nimbus简介
- [转]JStorm之Nimbus简介
- jstorm源码阅读(2) —— supervisor简介
- JStorm与Storm源码分析(一)--nimbus-data
- JStorm之Supervisor简介
- jstorm源码分析: nimbus
- JStorm之Supervisor简介
- jstorm简介(转)
- 流式计算-Jstorm简介
- JStorm之NimbusServer启动流程
- Jstorm 简介
- JStorm与Storm源码分析(一)--nimbus-data
- JStorm与Storm源码分析(一)--nimbus-data
- [转]JStorm之Supervisor简介
- jstorm集群配置部署过程全纪录(补充:报错解决):java.lang.RuntimeException: No alive nimbus
- ***检测系统简介
- 安装大型 Linux 集群,第 1 部分: 简介和硬件配置
- Linux 2.6.19.x 内核编译配置选项简介
- Socketpair 简介