黑马程序员------集合
2015-03-27 23:19
148 查看
——Java培训、Android培训、iOS培训、.Net培训、期待与您交流! ——-
集合上回整理的笔记没保存就误关了浏览器,我辛辛苦苦做的笔记啊,辛辛苦苦敲的demo啊都没了坑爹啊55555555…TAT
———-吐槽完毕———-
集合框架

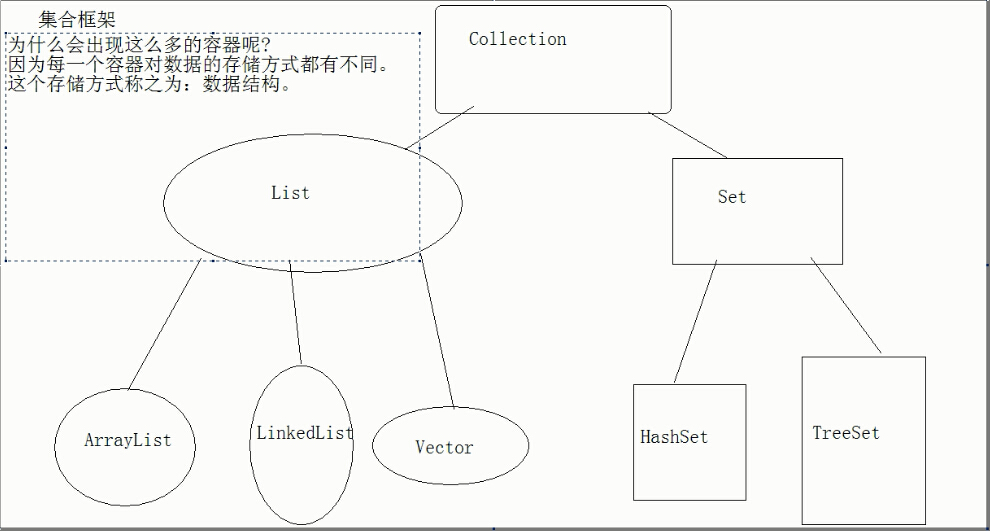
|–List 元素可重复,有序
|——ArrayList 增删慢,查找快
|——LinkedList 增删快,查找慢
|–Set元素不可重复
|——HashSet 无序
|——TreeSet有序–实现comparable接口,实现自然排序,或者传入一个comparetor比较器
**ArrayList**List只有增,查方法
ArrayList特有方法【跟脚标相关】:add,addAll,get,indexOf
set(int index,E element)
迭代器Iterator
迭代器就是集合的取出元素的方式。
把取出方式定义在集合的内部,这样取出方式就可以直接访问结合内容的元素。那么取出方式就定义成了内部类。
而每一个容器的数据结构不同,所以取出的动作细节也不一样,但是都有共性内容:取出。那么可以写共性取出。
那么这些内部类都符合一个规则。该规则是Iterator。
迭代时注意:在迭代时候,不可以通过集合对象的方法操作集合中的元素,因为会发生 ConcurrenModificationException异常。所以在迭代器时,只能用迭代器的方法操作元素,可是Iterator方法是有限的,只能对元素进行判断,取出,删除的操作
如果想要其他的操作,如添加、修改等,就需要使用其子接口,ListIterator。
ListIterator特有方法
hasPrevious(),nextIndex(),previous(),previousIndex(),remove()
set(E e)
自定义对象用集合存demo
Set
HashSet
HashSet存对象的时候,先判断哈希值是否一样,如果一样就比较后存的对象是否equals原有对象
存自定义对象的时候,例如Person对象,
两个add的对象由于他们的哈希值不一样,(通过哈希散列函数hashCode()方法生成哈希值),所以会equals对象
这就要复写对象的hashCode方法和equals方法了
HashSet是如何保证元素唯一性的呢?
是通过两个方法,hashCode和equals来完成。
如果元素hashCode值相同,才会判断equals是否为true。
如果元素的hashCode不同,不会调用equals方法。
怎么重写hashCode()和equals()方法呢?
hashCode():把对象的所有成员变量值相加即可。
如果是基本数据类型,就加值。如果是引用类型,就加哈希值。
return name.hashCode()+ age * 27;—27是任意数,注意hashCode()方法返回值int类型的边界问题,不能定太大
equals(obj):先判断是否是同一类型的对象,再把传递进来的对象进行向下转型。再判断对象的内容是否相同。
所有成员变量的值比较。基本类型用==,引用类型用equals()。
注意:对于判断元素是否存在,以及删除等操作,依赖的方法是元素的hashCode和equals方法。
TreeSet :底层的数据结构是二叉树。
TreeSet集合两种实现排序方式:
自然排序(元素具备比较性)
TreeSet的无参构造,要求对象所属的类实现Comparable接口。
复写 int compareTo(T o)方法
比较器排序(集合具备比较性)
TreeSet的带参构造,要求构造方法接收一个实现了Comparator接口的对象。
复写int compare(T o1, T o2) 方法
当两种方式都存在,优先使用比较器
泛型
好处:
1、将运行时期出现的问题(classCastException),转移到了编译时期。
方便于程序员解决问题。让运行时期问题减少,安全。
2、避免了强制转换的麻烦。
泛型格式:通过 <> 来定义要操作的引用数据类型。
只要见到<>就要定义泛型
其实<>就是用来接收类型的。
当使用集合时,将集合中要存储的数据类型作为参数传递到尖括号中即可,和函数传参数一样。
泛型类
静态方法泛型
泛型接口
泛型通配符
泛型限定
? extends E:可以接收 E 类型或者 E 的子类型。上限。
? super E:可以接收E类型或者E的父类型,下限
Map
主要方法:
增加
put();
putAll();
删除
clear();
remove();
判断
containsKey()
containsValue()
isEmpty();
获取
get()
|–Hashtable:底层是哈希表数据结构,不可以存入null键null值。该集合是线程同步的。JDK1.0.效率低。
此类实现一个哈希表,该哈希表将键映射到相应的值。任何非null 对象都可以用作键或值。
为了成功地在哈希表中存储和获取对象,用作键的对象必须实现 hashCode 方法和 equals 方法。
|–HashMap:基于哈希表的Map接口的实现。此实现提供所有可选的映射操作,并允许使用null 值和null键。
(除了非同步和允许使用null 之外,HashMap 类与Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。 将 Hashtable替代,JDK1.2.效率高。
|–TreeMap:基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator(比较器) 进行排序,具体取决于使用的构造方法。
和Set很像。
Set底层就是使用了Map集合。线程不同步。可以用于给Map集合中的键进行排序。
Map取出方式:
通过keySet方法得到一个key的Set视图,然后用Set的迭代器遍历里面的元素key,通过map的get(key)得到value
通过entrySet() 方法得到此映射中包含的映射关系的 Set 视图,再通过Map.Entry()里面的getKey,getValue方法得到键和值
Set
集合框架中的工具类
Collections
sort升序牌序
二分查找
binarySearch(List
sort(List list,Comparator
如果数组中的元素,都是对象,变成集合时,数组中的元素就直接转换成集合中的元素
String str [] = {“hehe”,”haha”,”xixi”}; 变为List[hehe,haha,xixi]
如果数组中的元素都是基本数据类型,那么会将该数组作为集合中的元素存在。
int arr[] = {1,2,3,4};
List list =Arrays.asList(arr);
变为List [arr]
集合变成数组
当我们不希望调用者对我们的集合进行操作时,这时候就要把集合变成数组,让操作者不能对其进行基本的操作,但是数组的功能还是可以使用的,比如获取。
toArray()
Object[] arr = list.toArray();
指定类型的数组到底要定义多长呢?
当指定类型的数组长度小于了集合的size,那么该方法内部都会创建一个新的数组,长度为集合的size
当指定类型的数组长度大于了集合的size,就不会新创建数组,而是使用传递进来的数组,
所以应该创建一个刚刚好的。
String[] arr = list.toArray(new String[al.size()]);
增强for循环
for(数据类型 变量名 : 被变量的集合(Collection)或者数组){
}
对集合进行遍历,只能获取集合元素,但是不能对集合进行操作。
迭代器出了遍历,还可以进行remove集合中元素的动作。
如若果使用ListIterator,还可以在遍历过程中对集合进行增删改查动作。
——Java培训、Android培训、iOS培训、.Net培训、期待与您交流! ——-
集合上回整理的笔记没保存就误关了浏览器,我辛辛苦苦做的笔记啊,辛辛苦苦敲的demo啊都没了坑爹啊55555555…TAT
———-吐槽完毕———-
集合框架
|–List 元素可重复,有序
|——ArrayList 增删慢,查找快
|——LinkedList 增删快,查找慢
|–Set元素不可重复
|——HashSet 无序
|——TreeSet有序–实现comparable接口,实现自然排序,或者传入一个comparetor比较器
**ArrayList**List只有增,查方法
ArrayList特有方法【跟脚标相关】:add,addAll,get,indexOf
set(int index,E element)
package com.itheima.answer;
import java.util.ArrayList;
import java.util.List;
public class Test1 {
public static void main(String[] args) {
ArrayList al = new ArrayList();
al.add("zs01");// 添加了一个元素
al.add("zs02");
al.add("zs03");
al.add("zs04");
sop(al.get(1));
al.remove("zs04");// 删除一个元素
sop(al.size());// 打印下集合的长度 结果为3.因为删了一个
al.clear();// 清空集合
sop(al.contains("zs03"));
sop(al.isEmpty());
method();
}
public static void method() {
List list1 = new ArrayList();
list1.add("zs01");
list1.add("zs02");
list1.add("zs03");
list1.add("zs04");
List list2 = new ArrayList();
list2.add("zs01");
list2.add("zs02");
list2.add("zs05");
list2.add("zs06");
// list1.retainAll(list2);//取交集。拿list1元素跟list2的元素比,如果相同就保留。调用父类的方法
// sop(list1);
list1.removeAll(list2);// 删除交集。拿list1的元素跟list2的元素比,如果相同就删除。调用父类的方法
sop(list1);
}
public static void sop(Object obj) {
System.out.println(obj);
}
}迭代器Iterator
迭代器就是集合的取出元素的方式。
把取出方式定义在集合的内部,这样取出方式就可以直接访问结合内容的元素。那么取出方式就定义成了内部类。
而每一个容器的数据结构不同,所以取出的动作细节也不一样,但是都有共性内容:取出。那么可以写共性取出。
那么这些内部类都符合一个规则。该规则是Iterator。
迭代时注意:在迭代时候,不可以通过集合对象的方法操作集合中的元素,因为会发生 ConcurrenModificationException异常。所以在迭代器时,只能用迭代器的方法操作元素,可是Iterator方法是有限的,只能对元素进行判断,取出,删除的操作
如果想要其他的操作,如添加、修改等,就需要使用其子接口,ListIterator。
ListIterator特有方法
hasPrevious(),nextIndex(),previous(),previousIndex(),remove()
set(E e)
自定义对象用集合存demo
package com.itheima.answer;
/*
将自定义对象作为元素存到ArrayList集合中,并去除重复元素
比如,存人对象,视为同一个人,为重复元素。
思路:
1、对人描述,将数据封装进人对象
2、定义容器,将人进行存入
3、取出
List集合判断是否包含其实是根据这个对象判断是否和内部的对象, equals,可以复写这个equals,写自己的判断
当List remove 删除时候,也是先equals判断有没有,如果所以要注意
*/
import java.util.ArrayList;
import java.util.Iterator;
class Person {
private String name;
private int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
public boolean equals(Object obj){
if(!(obj instanceof Person))
return false;
Person p = (Person)obj;
return name.equals(p.name) && this.age==p.age;
} public String getName() {
return name;
}
public int getAge() {
return age;
}
}
public class Test1 {
public static void main(String args[]) {
ArrayList al = new ArrayList();
al.add(new Person("list01", 31));
al.add(new Person("list02", 32));
al.add(new Person("list02", 32));
al.add(new Person("list03", 33));
al.add(new Person("list04", 34));
al.add(new Person("list04", 34));
al.add(new Person("list05", 35));
al = singleElement(al);
for (Iterator it = al.iterator(); it.hasNext();) {
Person p = (Person) it.next();
sop(p.getName() + ":" + p.getAge());
}
}
public static void sop(Object obj) {
System.out.println(obj.toString());
}
public static ArrayList singleElement(ArrayList al) {
ArrayList newAl = new ArrayList();
for (Iterator it = al.iterator(); it.hasNext();) {
Object obj = it.next();
if (!newAl.contains(obj)) {
newAl.add(obj);
}
}
return newAl;
}
}Set
HashSet
HashSet存对象的时候,先判断哈希值是否一样,如果一样就比较后存的对象是否equals原有对象
存自定义对象的时候,例如Person对象,
HashSet hs = new HashSet ();
hs.add(new Person("zhangsan",11));
hs.add(new Person("zhangsan",11));两个add的对象由于他们的哈希值不一样,(通过哈希散列函数hashCode()方法生成哈希值),所以会equals对象
这就要复写对象的hashCode方法和equals方法了
HashSet是如何保证元素唯一性的呢?
是通过两个方法,hashCode和equals来完成。
如果元素hashCode值相同,才会判断equals是否为true。
如果元素的hashCode不同,不会调用equals方法。
怎么重写hashCode()和equals()方法呢?
hashCode():把对象的所有成员变量值相加即可。
如果是基本数据类型,就加值。如果是引用类型,就加哈希值。
return name.hashCode()+ age * 27;—27是任意数,注意hashCode()方法返回值int类型的边界问题,不能定太大
equals(obj):先判断是否是同一类型的对象,再把传递进来的对象进行向下转型。再判断对象的内容是否相同。
if(!(obj instanceof Student)) ; Student stu = (Student)obj; return this.name.equals(stu.name) && this.age == stu.age;
所有成员变量的值比较。基本类型用==,引用类型用equals()。
注意:对于判断元素是否存在,以及删除等操作,依赖的方法是元素的hashCode和equals方法。
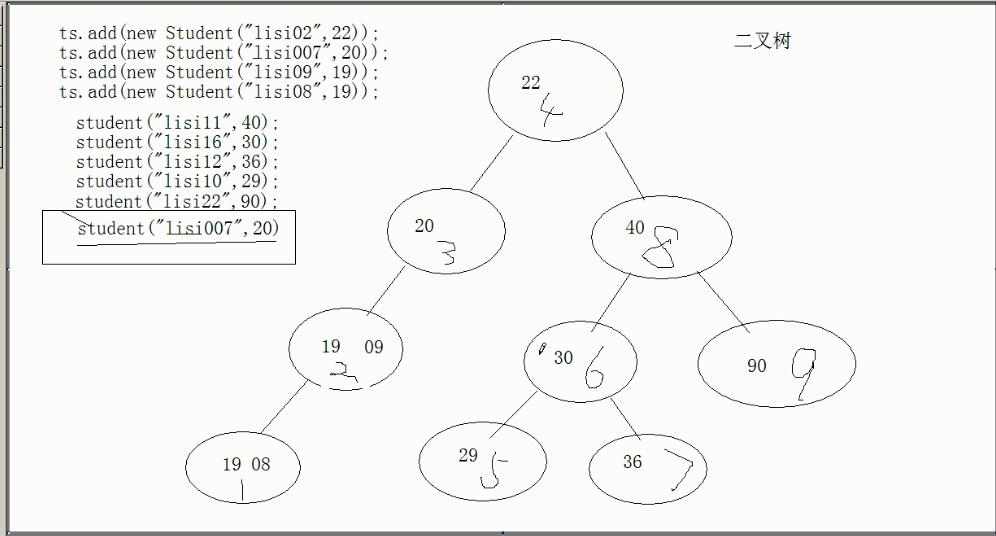
TreeSet :底层的数据结构是二叉树。
TreeSet集合两种实现排序方式:
自然排序(元素具备比较性)
TreeSet的无参构造,要求对象所属的类实现Comparable接口。
复写 int compareTo(T o)方法
比较器排序(集合具备比较性)
TreeSet的带参构造,要求构造方法接收一个实现了Comparator接口的对象。
复写int compare(T o1, T o2) 方法
当两种方式都存在,优先使用比较器
package com.itheima.answer;
/*
需求:往 TreeSet 集合中存储自定义对象学生。
想按照学生的年龄进行排序。
*/
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
class MyCompare implements Comparator {//比较器
public int compare(Object obj1, Object obj2) {
Student s1 = (Student) obj1;
Student s2 = (Student) obj2;
int num = new Integer(s1.getAge()).compareTo(new Integer(s2.getAge()));
if (num == 0)
return s1.getName().compareTo(s2.getName());
return num;
}
}
class Student implements Comparable {//实现Comparable 接口
private String name;
private int age;
Student(String name, int age) {
this.name = name;
this.age = age;
}
public int compareTo(Object obj) {
if (!(obj instanceof Student)) {
throw new RuntimeException("不是学生对象");
}
Student s = (Student) obj;
int num = this.age - s.age;
if (num == 0)
return this.name.compareTo(s.name);
else
return num;
}
public String toString() {
return name + "..." + age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public class Test1 {
public static void main(String[] args) {
TreeSet ts = new TreeSet();
ts.add(new Student("zhangsan", 21));
ts.add(new Student("wangwu", 23));
ts.add(new Student("zhouqi", 19));
ts.add(new Student("zhaoliu", 18));
for (Iterator iter = ts.iterator(); iter.hasNext();) {
sop(iter.next());
}
}
public static void sop(Object obj) {
System.out.println(obj);
}
}泛型
好处:
1、将运行时期出现的问题(classCastException),转移到了编译时期。
方便于程序员解决问题。让运行时期问题减少,安全。
2、避免了强制转换的麻烦。
泛型格式:通过 <> 来定义要操作的引用数据类型。
只要见到<>就要定义泛型
其实<>就是用来接收类型的。
当使用集合时,将集合中要存储的数据类型作为参数传递到尖括号中即可,和函数传参数一样。
泛型类
public <T> void show(T t){
}静态方法泛型
public static <T> void setName(T t){
}泛型接口
interface Inter<T>{
void show(T t);
}
class InterImpl implements Inter<String>{
void show(String t)//这里只能是 String{
}
}
class InterImpl2<T> implements Inter<T>{
void show(T t);//这里类型不固定{
}
}泛型通配符
package com.itheima.answer;
import java.util.ArrayList;
import java.util.List;
import java.util.Iterator;
public class Test1 {
public static void main(String args[]) {
List<String> al = new ArrayList<String>();
al.add("heihei");
al.add("hehe");
al.add("haha");
List<Integer> al1 = new ArrayList<Integer>();
al1.add(1);
al1.add(2);
al1.add(3);
printCollection(al);
printCollection(al1);
}
public static void printCollection(List<?> al) {
for (Iterator<?> it = al.iterator(); it.hasNext();) {
System.out.println(it.next());
}
}
}泛型限定
? extends E:可以接收 E 类型或者 E 的子类型。上限。
? super E:可以接收E类型或者E的父类型,下限
Map
主要方法:
增加
put();
putAll();
删除
clear();
remove();
判断
containsKey()
containsValue()
isEmpty();
获取
get()
|–Hashtable:底层是哈希表数据结构,不可以存入null键null值。该集合是线程同步的。JDK1.0.效率低。
此类实现一个哈希表,该哈希表将键映射到相应的值。任何非null 对象都可以用作键或值。
为了成功地在哈希表中存储和获取对象,用作键的对象必须实现 hashCode 方法和 equals 方法。
|–HashMap:基于哈希表的Map接口的实现。此实现提供所有可选的映射操作,并允许使用null 值和null键。
(除了非同步和允许使用null 之外,HashMap 类与Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。 将 Hashtable替代,JDK1.2.效率高。
|–TreeMap:基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator(比较器) 进行排序,具体取决于使用的构造方法。
和Set很像。
Set底层就是使用了Map集合。线程不同步。可以用于给Map集合中的键进行排序。
package com.itheima.answer;
import java.util.Map;
import java.util.HashMap;
import java.util.Collection;
public class MapDemo {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
// 添加元素
map.put("01", "zhangsan");
map.put("02", "lisi");
map.put("03", "wangwu");
map.put("null", "zhaoliu");/*
* 可以存入空值,但是不常见,所以可以通过get方法的返回值,null来判断一个键的不存在
*/
sop(map.containsKey("02"));
sop(map.get("null"));
if (map.get("null") != null)
map.remove(map.get("null"));
else
sop("Value to Null");
// 可以通过get方法的返回值来判断一个键是否存在。通过返回null来判断。
sop(map.remove("02"));/* 返回值是删除键的值 */
sop(map.containsKey("02"));
sop("----
c1a5
-------");
// 获取map集合中所有的值。
Collection<String> coll = map.values();
sop(coll);
map.put("01", "zhangsan1"); /* 如果加入的键和值都相同的话,返回null */
map.put("01", "zhangsan2");/*
* 当添加相同的键而值不同,则后添加的值会覆盖原有值,并且返回原有值,
* 这里返回了zhangsan1【很重要!】
*/
}
public static void sop(Object obj) {
System.out.println(obj);
}
}Map取出方式:
通过keySet方法得到一个key的Set视图,然后用Set的迭代器遍历里面的元素key,通过map的get(key)得到value
通过entrySet() 方法得到此映射中包含的映射关系的 Set 视图,再通过Map.Entry()里面的getKey,getValue方法得到键和值
Set
package com.itheima.answer;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class GetMapDemo {
public static void main(String[] args) {
Map<String, String> hs = new HashMap<String, String>();
hs.put("01", "zs1");
hs.put("02", "zs2");
hs.put("03", "zs3");
hs.put("04", "zs4");
// getbySet(hs);
getbyMapEntry(hs);
}
/*
* Map取出方式:
*
* 1. 通过keySet方法得到一个key的Set视图,然后用Set的迭代器遍历里面的元素key, 通过map的get(key)得到value
*/
private static void getbySet(Map m) {
Set<String> set = m.keySet();
Iterator<String> it = set.iterator();
while (it.hasNext()) {
String key = it.next();
System.out.println(key + ":" + m.get(key));
}
}
/*
* 2. 通过entrySet() 方法得到此映射中包含的映射关系的 Set
* 视图,再通过Map.Entry()里面的getKey,getValue方法得到键和值
*/
private static void getbyMapEntry(Map m) {
Set<Map.Entry<String, String>> me = m.entrySet();
Iterator<Map.Entry<String, String>> it = me.iterator();
while (it.hasNext()) {
Map.Entry<String, String> mes = it.next();
System.out.println(mes.getKey() + ":" + mes.getValue());
}
}
}集合框架中的工具类
Collections
sort升序牌序
二分查找
binarySearch(List
package com.itheima.answer;
public class BinarySearchDemo {
public static int BinarySearch(int[] arr, int element) {
int min, mid, max;
min = 0;
max = arr.length - 1;
while (min <= max) {
mid = (max + min) >> 1;
if (arr[mid] > element)
max = mid - 1;
else if (arr[mid] < element)
min = mid + 1;
else
return mid;
}
return -1;
}
public static void main(String[] args) {
int[] arr = { 1, 2, 5, 24, 34, 57, 61, 67, 100, 245 };
System.out.println(BinarySearch(arr, 57));
}
}sort(List list,Comparator
String str [] = {"1","2","3"};
List<String>list =Arrays.asList(str);
//list.add("4");会发生异常,因为数组是固定大小的,变为集合不能再增删元素如果数组中的元素,都是对象,变成集合时,数组中的元素就直接转换成集合中的元素
String str [] = {“hehe”,”haha”,”xixi”}; 变为List[hehe,haha,xixi]
如果数组中的元素都是基本数据类型,那么会将该数组作为集合中的元素存在。
int arr[] = {1,2,3,4};
List list =Arrays.asList(arr);
变为List [arr]
集合变成数组
当我们不希望调用者对我们的集合进行操作时,这时候就要把集合变成数组,让操作者不能对其进行基本的操作,但是数组的功能还是可以使用的,比如获取。
toArray()
Object[] arr = list.toArray();
指定类型的数组到底要定义多长呢?
当指定类型的数组长度小于了集合的size,那么该方法内部都会创建一个新的数组,长度为集合的size
当指定类型的数组长度大于了集合的size,就不会新创建数组,而是使用传递进来的数组,
所以应该创建一个刚刚好的。
String[] arr = list.toArray(new String[al.size()]);
增强for循环
for(数据类型 变量名 : 被变量的集合(Collection)或者数组){
}
对集合进行遍历,只能获取集合元素,但是不能对集合进行操作。
迭代器出了遍历,还可以进行remove集合中元素的动作。
如若果使用ListIterator,还可以在遍历过程中对集合进行增删改查动作。
——Java培训、Android培训、iOS培训、.Net培训、期待与您交流! ——-

相关文章推荐
- 黑马程序员 java基础之集合工具类
- 黑马程序员----集合工具类(Arrays和Collections)
- 黑马程序员_关于java中的集合
- 黑马程序员——Map集合的基本概述
- 黑马程序员———— 泛型 Map集合(day18)
- 黑马程序员_Java_集合总结
- 黑马程序员—集合框架小结
- 黑马程序员_集合1-listj集合派系
- 黑马程序员__集合框架总结
- 黑马程序员---Java 容器集合
- 黑马程序员-------集合List
- 黑马程序员——Java基础---集合(Collection和List)
- 黑马程序员_java之集合
- 黑马程序员 集合基础知识
- 黑马程序员_Java基础_集合框架工具类
- 黑马程序员--Java基础学习(集合工具类)第十七天
- 黑马程序员 日记六:集合的学习总结
- 黑马程序员——java集合中的HashSet
- 黑马程序员——Java基础知识(集合框架(下))
- 黑马程序员——java基础——集合框架(一:单列集合(Collection体系))