EM算法结合k-means
2015-03-27 17:32
267 查看
在前一篇文章中,重点讲解了EM的推导过程,但是这里EM只是一个算法思想
比如里***体的参数θ还需要根据需要参数迭代的具体的模型进行确定。在EM中很重要的一个概念是隐含变量,也就是类别Z,那么在机器学习的算法中很重要的两个模型都是和Z不确定情况下求参数。聚类问题和GMM,其实GMM也是可以看成是类似聚类模型的一个算法。
一 Kmean: http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
在聚类问题中,给我们的训练样本是
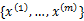
,每个
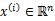
,没有了y。
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
畸变函数(distortion function)如下:

由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的

和c输出。
在这里Kmean算法不知道每个样本点对应的类别,如果我们使用样本的最大似然概率来进行度量,就是联合分布P(x,y,θ)(y是类别,θ表示别的参数)目标就是找到合适的y使联合概率最大。这里就可以提出一个初步的EM模型:先给x指定y,这时候调整其他参数θ是联合概率最大,然后再根据参数调整类型y.最后得到收敛,顺便聚类也就完成了。
对应于K-means来说就是我们一开始不知道每个样例
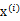
对应隐含变量也就是最佳类别

。最开始可以随便指定一个

给它(这里就是一个硬指定的过程),然后为了让P(x,y)最大(这里是要让J最小),我们求出在给定c情况下,J最小时的
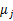
(前面提到的其他未知参数),然而此时发现,可以有更好的
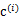
(质心与样例

距离最小的类别)指定给样例
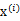
,那么
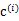
得到重新调整,上述过程就开始重复了,直到没有更好的

指定。这样从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量

,M步更新其他参数
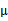
来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
E : 给每个样本指定一个类别
M : 根据指定的类别调整参数(我的理解这里就是调整各个类别的质心)
等调整完质心之后,每个样本的类别由可以开始进行修改了
比如里***体的参数θ还需要根据需要参数迭代的具体的模型进行确定。在EM中很重要的一个概念是隐含变量,也就是类别Z,那么在机器学习的算法中很重要的两个模型都是和Z不确定情况下求参数。聚类问题和GMM,其实GMM也是可以看成是类似聚类模型的一个算法。
一 Kmean: http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
在聚类问题中,给我们的训练样本是

,每个

,没有了y。
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
1、 随机选取k个聚类质心点(cluster centroids)为 。 2、 重复下面过程直到收敛 { 对于每一个样例i,计算其应该属于的类  对于每一个类j,重新计算该类的质心  } |

由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的
和c输出。
在这里Kmean算法不知道每个样本点对应的类别,如果我们使用样本的最大似然概率来进行度量,就是联合分布P(x,y,θ)(y是类别,θ表示别的参数)目标就是找到合适的y使联合概率最大。这里就可以提出一个初步的EM模型:先给x指定y,这时候调整其他参数θ是联合概率最大,然后再根据参数调整类型y.最后得到收敛,顺便聚类也就完成了。
对应于K-means来说就是我们一开始不知道每个样例

对应隐含变量也就是最佳类别

。最开始可以随便指定一个

给它(这里就是一个硬指定的过程),然后为了让P(x,y)最大(这里是要让J最小),我们求出在给定c情况下,J最小时的

(前面提到的其他未知参数),然而此时发现,可以有更好的

(质心与样例

距离最小的类别)指定给样例

,那么

得到重新调整,上述过程就开始重复了,直到没有更好的

指定。这样从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量

,M步更新其他参数

来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
E : 给每个样本指定一个类别
M : 根据指定的类别调整参数(我的理解这里就是调整各个类别的质心)
等调整完质心之后,每个样本的类别由可以开始进行修改了

相关文章推荐
- K-Means聚类和EM算法复习总结
- EM算法与k-means及极大似然估计
- K-Means聚类和EM算法复习总结
- 斯坦福ML公开课笔记12——K-Means、混合高斯分布、EM算法
- K-Means聚类和EM算法复习总结
- 聚类1-K-means-EM算法
- 斯坦福ML公开课笔记12——K-Means、混合高斯分布、EM算法
- EM算法在K-Means中的运用
- 13.k-means聚类,混合高斯,EM算法
- EM算法结合GMM混合高斯模型
- k-means和EM算法的Matlab实现
- k-means与EM算法小结
- EM算法(期望最大化)——从EM算法角度理解K-Means与GMM的区别
- Jquery与JS结合学习笔记
- Android开发之Buidler模式初探结合AlertDialog.Builder讲解
- jQuery UI结合Ajax创建可定制的Web界面
- tomcat结合nginx使用小结
- svn结合apache后用户修改密码的解决方案
- ViewPager一:结合Fragment使用
- Android4.4沉浸状态栏结合CoordinatorLayout,AppBarLayout,CollapsingToolbarLayout等使用详解