spark编译及运行常见错误
2015-03-27 15:49
357 查看
### spark 下载
http://spark.apache.org/downloads.html
### 前提准备
# 安装 JDK,mvn 和 scala,并设置对应的JAVA_HOME,MVN_HOME 和 SCALA_HOME
### Spark 编译 (参考 http://spark.apache.org/docs/latest/building-with-maven.html)
#1 设置maven的环境变量
exportMAVEN_OPTS="-Xmx2g
-XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
#2 为了加快依赖包下载速度,可以在工程的pom.xml文件中,加入自己的maven私服
#3 为了mllib库,使用netlib-java,需要在mllib/pom.xml中增加如下依赖
<dependency>
<groupId>com.github.fommil.netlib</groupId>
<artifactId>all</artifactId>
<version>1.1.2</version>
<type>pom</type>
</dependency>
#4 编译
#指定hadoop版本compile
mvn -Pyarn -Phadoop-2.4 -Dhadoop.version=2.5.0 -DskipTests clean package
# 不携带hadoop信息的编译方式
mvn -Pyarn -Phadoop-provided -Phadoop-2.4 -Dhadoop.version=2.5.0 -DskipTests clean package
# 生成发布式包的方式
## 如果是1.0.2 之前的版本(包括1.0.2),使用如下方式打包
sh
make-distribution.sh --tgz --hadoop 2.5.0 --with-yarn --skip-java-test
## 如果是1.1.0 之后的版本(包括1.1.0),使用如下方式打包
sh make-distribution.sh --tgz -Phive -Pyarn -Phadoop-2.4 -Phadoop-provided -Pnetlib-lgpl -Phive-0.13.1 -Pscala-2.10 -Dhadoop.version=2.5.0 [--name 如果需要指定自己的tar 名称]
#注意这里有个问题,如果我们用了1.7的java,那么不能使用--skip-java-test选项,否则将无法打包,因为执行的过程中就失败了,而且无任何错误
**************************************************************************************************
1、下载并编译spark源码
下载spark http://spark.apache.org/downloads.html 我下载的是1.2.0版本
解压并编译,在编译前,可以根据自己机器的环境修改相应的pom.xml配置,我的环境是hadoop2.4.1修改个小版本号即可,编译包括了对hive、yarn、ganglia等的支持
注:spark每个版本发布后,可能都会对pom.xml配置做出相应的调整,请根据pom.xml文件中的配置,对应调整编译时的参数。
2、spark相关配置
将编译后的.tgz文件解压,配置环境变量及spark配置文件,如下:
环境变量:(仅列出spark相关的配置)
spark-env.sh
slaves
spark-default.conf
复制spark到各个节点
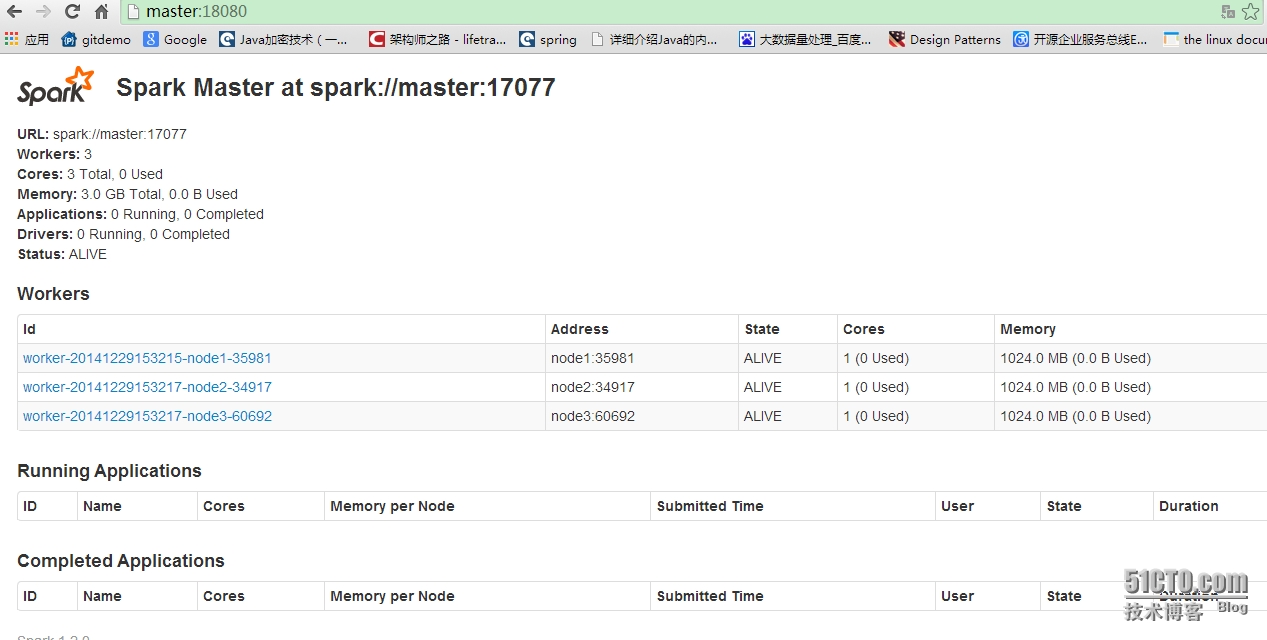
3、启动spark(master单点)
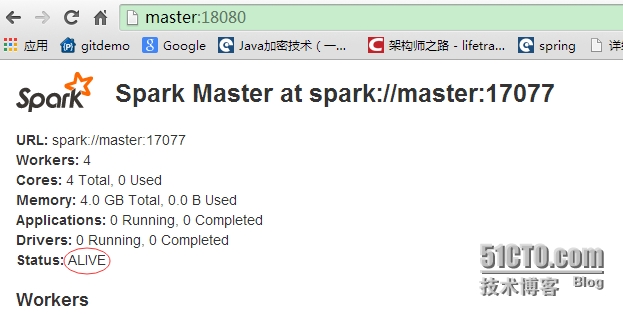
4、spark (基于zookeeper的master节点HA)
配置zookeeper集群,使用master、node1、node2三个节点,有关zookeeper集群的配置此处略过。三个节点启动zookeeper
spark-env.sh配置文件增加zookeeper相关配置(注:因为HA后,master可以为多个,所以在配置文件中不可指定SPARK_MASTER_IP,否则无法正常启动)
master节点启动spark
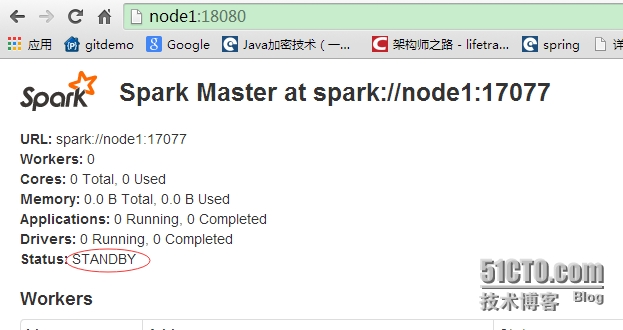
node1节点启动HA
5、启动spark-shell
1)单个master进程启动
2)HA模式启动
6、启动history-server
在node1节点启动history-server,相关配置已经在spark-defaults.conf中配置
http://spark.apache.org/downloads.html
### 前提准备
# 安装 JDK,mvn 和 scala,并设置对应的JAVA_HOME,MVN_HOME 和 SCALA_HOME
### Spark 编译 (参考 http://spark.apache.org/docs/latest/building-with-maven.html)
#1 设置maven的环境变量
exportMAVEN_OPTS="-Xmx2g
-XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
#2 为了加快依赖包下载速度,可以在工程的pom.xml文件中,加入自己的maven私服
<repository> <id>sohu.nexus</id> <url>http://index.tv.sohuno.com/nexus/content/groups/public/</url> </repository>
#3 为了mllib库,使用netlib-java,需要在mllib/pom.xml中增加如下依赖
<dependency>
<groupId>com.github.fommil.netlib</groupId>
<artifactId>all</artifactId>
<version>1.1.2</version>
<type>pom</type>
</dependency>
#4 编译
#指定hadoop版本compile
mvn -Pyarn -Phadoop-2.4 -Dhadoop.version=2.5.0 -DskipTests clean package
# 不携带hadoop信息的编译方式
mvn -Pyarn -Phadoop-provided -Phadoop-2.4 -Dhadoop.version=2.5.0 -DskipTests clean package
# 生成发布式包的方式
## 如果是1.0.2 之前的版本(包括1.0.2),使用如下方式打包
sh
make-distribution.sh --tgz --hadoop 2.5.0 --with-yarn --skip-java-test
## 如果是1.1.0 之后的版本(包括1.1.0),使用如下方式打包
sh make-distribution.sh --tgz -Phive -Pyarn -Phadoop-2.4 -Phadoop-provided -Pnetlib-lgpl -Phive-0.13.1 -Pscala-2.10 -Dhadoop.version=2.5.0 [--name 如果需要指定自己的tar 名称]
#注意这里有个问题,如果我们用了1.7的java,那么不能使用--skip-java-test选项,否则将无法打包,因为执行的过程中就失败了,而且无任何错误
**************************************************************************************************
1、下载并编译spark源码
下载spark http://spark.apache.org/downloads.html 我下载的是1.2.0版本
解压并编译,在编译前,可以根据自己机器的环境修改相应的pom.xml配置,我的环境是hadoop2.4.1修改个小版本号即可,编译包括了对hive、yarn、ganglia等的支持
tar xzf ~/source/spark-1.2.0.tgz cd spark-1.2.0 vi pom.xml ./make-distribution.sh --name 2.4.1 --with-tachyon --tgz -Pspark-ganglia-lgpl -Pyarn -Pkinesis-asl -Phive-0.13.1 -Phive-thriftserver -Phadoop-2.4 -Djava.version=1.6 -Dhadoop.version=2.4.1 -DskipTests
注:spark每个版本发布后,可能都会对pom.xml配置做出相应的调整,请根据pom.xml文件中的配置,对应调整编译时的参数。
2、spark相关配置
将编译后的.tgz文件解压,配置环境变量及spark配置文件,如下:
环境变量:(仅列出spark相关的配置)
export SCALA_HOME=/home/ocdc/bin/scala-2.10.4 export PATH=$SCALA_HOME/bin:$PATH export SPARK_HOME=/home/ocdc/bin/spark-1.2.0-bin-2.4.1 export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin:
spark-env.sh
export SPARK_MASTER_IP=master export SPARK_MASTER_PORT=17077 export SPARK_MASTER_WEBUI_PORT=18080 export SPARK_WORKER_CORES=1 export SPARK_WORKER_MEMORY=1g export SPARK_WORKER_WEBUI_PORT=18081 export SPARK_WORKER_INSTANCES=1 #配置master的HA时,需要配置此项,ZK需要提前启动 #export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,node1:2181,node2:2181"
slaves
node1 node2 node3
spark-default.conf
spark.master spark://master:17077 spark.eventLog.enabled true spark.eventLog.dir hdfs://cluster1:8021/eventLogDir spark.executor.memory 512m spark.driver.memory 512m
复制spark到各个节点
scp -r ~/bin/spark-1.2.0-bin-2.4.1/ ocdc@node1:~/bin/ scp -r ~/bin/spark-1.2.0-bin-2.4.1/ ocdc@node2:~/bin/ scp -r ~/bin/spark-1.2.0-bin-2.4.1/ ocdc@node3:~/bin/
3、启动spark(master单点)
cd $SPARK_HOME sbin/start-all.sh
4、spark (基于zookeeper的master节点HA)
配置zookeeper集群,使用master、node1、node2三个节点,有关zookeeper集群的配置此处略过。三个节点启动zookeeper
zkServer.sh start
spark-env.sh配置文件增加zookeeper相关配置(注:因为HA后,master可以为多个,所以在配置文件中不可指定SPARK_MASTER_IP,否则无法正常启动)
#export SPARK_MASTER_IP=master export SPARK_MASTER_PORT=17077 export SPARK_MASTER_WEBUI_PORT=18080 export SPARK_WORKER_CORES=1 export SPARK_WORKER_MEMORY=1g export SPARK_WORKER_WEBUI_PORT=18081 export SPARK_WORKER_INSTANCES=1 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,node1:2181,node2:2181"
master节点启动spark
sbin/start-all.sh
node1节点启动HA
sbin/start-master.sh
5、启动spark-shell
1)单个master进程启动
bin/spark-shell --master spark://master:17077
2)HA模式启动
bin/spark-shell --master spark://master:17077,node1:17077
6、启动history-server
在node1节点启动history-server,相关配置已经在spark-defaults.conf中配置
sbin/start-history-server.sh hdfs://cluster1:8020/eventLogDir
7、运行spark遇到错误及解决版本
1)Caused by: java.lang.ClassNotFoundException: com.hadoop.compression.lzo.LzoCodec
解决办法:在spark-env.sh 中加export SPARK_CLASSPATH=$SPARK_CLASSPATH:${SPARK_HOME}/lib/hadoop-lzo-0.4.19.jar2)当hadoop2支持lzo后,运行Standalone模式集群会报
15/07/21 13:46:26 ERROR GPLNativeCodeLoader: Could not load native gpl library
java.lang.UnsatisfiedLinkError: no gplcompression in java.library.path
解决办法:这个问题主要是jre目录下缺少了libhadoop.so。具体是,spark-shell依赖的是scala,scala依赖的是JAVA_HOME下的jdk,libhadoop.so应该放到JAVA_HOME/jre/lib/amd64下面。要注意的是要知道真正依赖到的JAVA_HOME是哪一个,把.so放对地方。这两个so:libhadoop.so和libsnappy.so。前一个so可以在HADOOP_HOME下找到,比如hadoop\lib\native\Linux-amd64-64。第二个libsnappy.so需要下载一个snappy-1.1.0.tar.gz,然后./configure,make编译出来。snappy是google的一个压缩算法,在hadoop jira下https://issues.apache.org/jira/browse/HADOOP-7206记录了这次集成。
cp /usr/lib/hadoop/lib/native/libgplcompression.so $JAVA_HOME/jre/lib/amd64/ cp /usr/lib/hadoop/lib/native/libhadoop.so $JAVA_HOME/jre/lib/amd64/ cp /usr/lib/hadoop/lib/native/libsnappy.so $JAVA_HOME/jre/lib/amd64/

相关文章推荐
- C# asp.net常见编译|运行错误
- VS* 之VC 常见编译运行错误 积累
- 在java文件编写,编译,运行各个步骤中出现的常见的错误(1)
- Spark程序运行常见错误解决方法以及优化
- C# asp.net常见编译|运行错误
- AndroidStudio十佳常见编译或运行错误集锦
- PHP中间件ICE,ICE的安装配置,ICE常见编译和运行(异常)错误(自测Php版本安装部分,因为php版本跟ice版本不一样失败)
- 34、编译、链接和运行时的常见错误
- C# asp.net常见编译|运行错误
- Xcode常见的编译、运行等错误的解决
- VS* 之VC 常见编译运行错误 积累
- VS2013编译运行常见错误及解决方法
- C# asp.net常见编译|运行错误
- C# asp.net常见编译|运行错误
- UNIX 环境下C++编译运行常见错误
- ICE常见编译和运行(异常)错误
- Spark程序运行常见错误解决方法以及优化
- SpringMVC框架项目在编译运行是常见错误
- AndroidStudio十佳常见编译或运行错误集锦
- Java菜鸟学习笔记(4)--常见编译&运行错误汇集(不断更新)