win7配置单机版hadoop
2015-03-18 09:46
260 查看
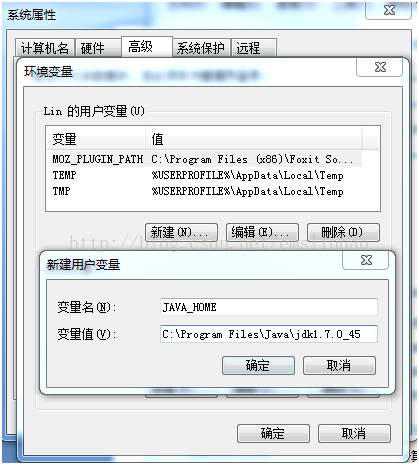
1. 安装JDK,配置环境变量
(我的安装目录:C:\Program Files\Java\jdk1.7.0_45)
用户变量添加JAVA_HOME,系统变量PATH后面添加JDK的bin目录
C:\Program Files\Java\jdk1.7.0_45\bin
2. 安装Cygwin
安装过程中记得选择所需的包,这里需要的是:
Net Category下的:openssh,openssl
BaseCategory下的:sed (若需要Eclipse,必须sed)
安装完成后,把CygWin的bin目录以及usr/sbin 追加到系统环境变量PATH中。
3. 打开Cygwin,把下载的hadoop-0.20.2.tar.gz解压到指定目录。
我把解压后的Hadoop程序放到了/home/hadoop

4. 配置Hadoop。需要配置的文件:(hadoop/conf目录下)
1) hadoop-env.sh
把里面的JAVA_HOME改掉,注意export前面的#号要去掉。
而且必须要使用linux的路径表达方式。我的jdk路径是 C:\Program Files\Java\jdk1.7.0_45,在CygWin中对应的路径为:/cygdrive/c/Program Files/jdk1.7.0_45

2) core-site.xml
首先删除它,然后把hadoop/src/core目录下的core-default.xml文件复制到conf目录下,并命名为core-site.xml。然后修改其中的fs.default.name变量,如下所示。
(确保端口号(我的是9100)未被占用)

3) hdfs-site.xml
首先把它删除,然后复制src/hdfs目录下的hdfs-default.xml到conf目录下,并改名为hdfs-site.xml
然后修改dfs.replication变量,如下图示:
该变量意思是文件系统中文件的复本数量。在单独的一个数据节点上运行时,HDFS无法将块复制到三个数据节点上。

4) mapred-site.xml
首先删除它,然后复制src/mapred目录下的mapred-default.xml到conf目录下,并改名为mapred-site.xml,然后修改其mapred.job.tracker变量:
(同样确保端口号未被占用)

5. 配置SSH服务
以管理员权限打开Cygwin
1)配置步骤如图
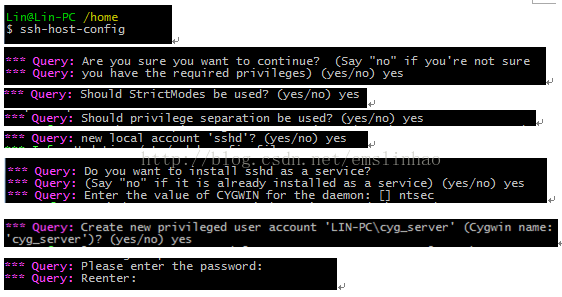
2)ssh-host-config重新配置
如果初始配置错误,大部分网上都建议全部删除再重新安装,但cygwin一旦安装很难完全卸载,只需要把ssh服务停止再重新执行这个命令,再把之前的覆盖掉就可以。
步骤: 1.scdelete sshd
2.系统重启,就再配置就ok了
3) 下一步,进入Window系统的服务菜单,打开Cygwin的SSHD服务(右键计算机->管理->服务和应用程序)
如下图所示:

4) 下面继续回到CygWin环境:执行如下命令:
1.ssh-keygen然后一直回车
2.cd ~/.ssh
3. cp id_rsa.pub authorized_keys
4.exit 退出cygwin,若不退出,可能出错
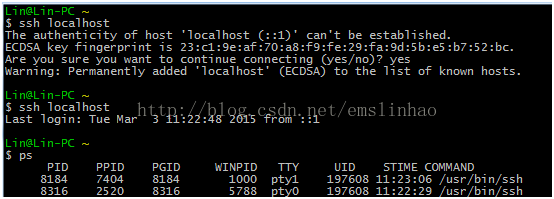
5运行 ssh localhost 若有提示,则回车。
6执行 ps 若看到 有/usr/bin/ssh 进程,说明成功
6. 启动hadoop
为了避免jobtracker,info could only bereplicated to 0 node,instead of 1错误,最好把 hadoop/conf目录下面的 masters和slaves文件全部改为127.0.0.1(原内容为:localhost)
第一步,在hadoop目录下创建目录logs,用于保存日志
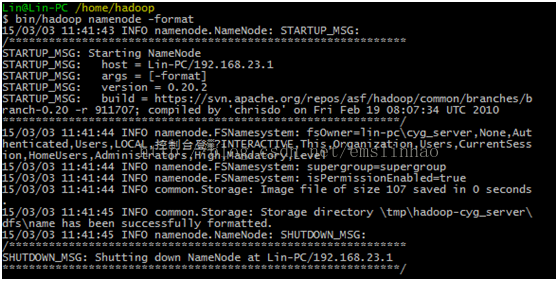
第二步,格式化管理者,即namenode,创建HDFS
执行命令: bin/hadoop namenode -format,下面示代表成功
第三步,启动Hadoop,执行命令: bin/start-all.sh
7. Eclipse安装Hadoop插件
1) 将hadoop-0.20.2-eclipse-plugin.jar 复制到eclipse/plugins目录下,重启eclipse。
2) Window -> Open Perspective -> Other 选择Map/Reduce
3) 在eclipse下端,控制台旁边会多一个Tab,叫“Map/Reduce Locations”,在下面空白的地方点右键,选择“New Hadoop location...”
在弹出的对话框中填写如下内容:
Location name(取个名字)
Map/Reduce Master(Job Tracker的IP和端口,根据mapred-site.xml中配置的mapred.job.tracker来填写)
DFS Master(Name Node的IP和端口,根据core-site.xml中配置的fs.default.name来填写)
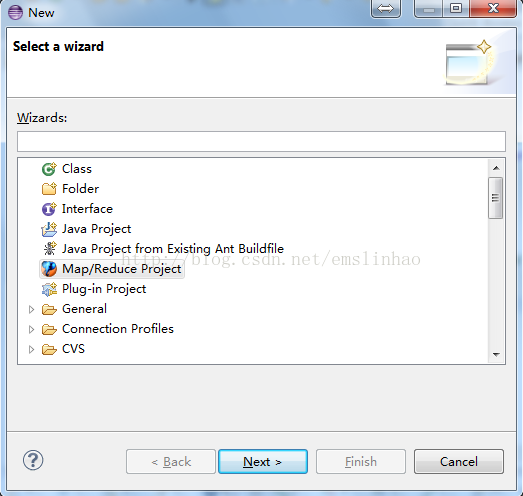
8. Eclipse创建Hadoop工程
(我的安装目录:C:\Program Files\Java\jdk1.7.0_45)
用户变量添加JAVA_HOME,系统变量PATH后面添加JDK的bin目录
C:\Program Files\Java\jdk1.7.0_45\bin
2. 安装Cygwin
安装过程中记得选择所需的包,这里需要的是:
Net Category下的:openssh,openssl
BaseCategory下的:sed (若需要Eclipse,必须sed)
安装完成后,把CygWin的bin目录以及usr/sbin 追加到系统环境变量PATH中。
3. 打开Cygwin,把下载的hadoop-0.20.2.tar.gz解压到指定目录。
我把解压后的Hadoop程序放到了/home/hadoop
4. 配置Hadoop。需要配置的文件:(hadoop/conf目录下)
1) hadoop-env.sh
把里面的JAVA_HOME改掉,注意export前面的#号要去掉。
而且必须要使用linux的路径表达方式。我的jdk路径是 C:\Program Files\Java\jdk1.7.0_45,在CygWin中对应的路径为:/cygdrive/c/Program Files/jdk1.7.0_45
2) core-site.xml
首先删除它,然后把hadoop/src/core目录下的core-default.xml文件复制到conf目录下,并命名为core-site.xml。然后修改其中的fs.default.name变量,如下所示。
(确保端口号(我的是9100)未被占用)
3) hdfs-site.xml
首先把它删除,然后复制src/hdfs目录下的hdfs-default.xml到conf目录下,并改名为hdfs-site.xml
然后修改dfs.replication变量,如下图示:
该变量意思是文件系统中文件的复本数量。在单独的一个数据节点上运行时,HDFS无法将块复制到三个数据节点上。
4) mapred-site.xml
首先删除它,然后复制src/mapred目录下的mapred-default.xml到conf目录下,并改名为mapred-site.xml,然后修改其mapred.job.tracker变量:
(同样确保端口号未被占用)
5. 配置SSH服务
以管理员权限打开Cygwin
1)配置步骤如图
2)ssh-host-config重新配置
如果初始配置错误,大部分网上都建议全部删除再重新安装,但cygwin一旦安装很难完全卸载,只需要把ssh服务停止再重新执行这个命令,再把之前的覆盖掉就可以。
步骤: 1.scdelete sshd
2.系统重启,就再配置就ok了
3) 下一步,进入Window系统的服务菜单,打开Cygwin的SSHD服务(右键计算机->管理->服务和应用程序)
如下图所示:
4) 下面继续回到CygWin环境:执行如下命令:
1.ssh-keygen然后一直回车
2.cd ~/.ssh
3. cp id_rsa.pub authorized_keys
4.exit 退出cygwin,若不退出,可能出错
5运行 ssh localhost 若有提示,则回车。
6执行 ps 若看到 有/usr/bin/ssh 进程,说明成功
6. 启动hadoop
为了避免jobtracker,info could only bereplicated to 0 node,instead of 1错误,最好把 hadoop/conf目录下面的 masters和slaves文件全部改为127.0.0.1(原内容为:localhost)
第一步,在hadoop目录下创建目录logs,用于保存日志
第二步,格式化管理者,即namenode,创建HDFS
执行命令: bin/hadoop namenode -format,下面示代表成功
第三步,启动Hadoop,执行命令: bin/start-all.sh
7. Eclipse安装Hadoop插件
1) 将hadoop-0.20.2-eclipse-plugin.jar 复制到eclipse/plugins目录下,重启eclipse。
2) Window -> Open Perspective -> Other 选择Map/Reduce
3) 在eclipse下端,控制台旁边会多一个Tab,叫“Map/Reduce Locations”,在下面空白的地方点右键,选择“New Hadoop location...”
在弹出的对话框中填写如下内容:
Location name(取个名字)
Map/Reduce Master(Job Tracker的IP和端口,根据mapred-site.xml中配置的mapred.job.tracker来填写)
DFS Master(Name Node的IP和端口,根据core-site.xml中配置的fs.default.name来填写)
8. Eclipse创建Hadoop工程

相关文章推荐
- Hadoop学习系列教程——单机版hadoop的配置安装
- 小功告成,在WIN7上配置上了HADOOP,终于可以一窥真容啦
- 系统的对单机版hadoop进行配置和安装,调试!!!
- Win7 自定义路径配置路径 cygwin部署hadoop
- win7下Eclipse4.4.0+JDK1.8配置hadoop2.5.1插件遇到的各种错误
- windows下配置Hadoop(单机版)
- hadoop入门级配置笔记(v1.2.1,win7 64位系统)
- 工作记录:win7下配置阅读hadoop源码环境
- Eclipse配置hadoop开发环境(win7)
- 在win7中配置eclipse连接Ubuntu内的hadoop
- 在win7下配置 hadoop开发环境
- win7中的eclipse连接虚拟机中Linux(Ubuntu)的Hadoop (附上配置时遇到的错误和解决的方法)
- Hadoop单机版安装,配置,运行
- Ubuntu下安装单机版Hadoop的配置
- win7中配置eclipse连接Ubuntu内的hadoop
- hadoop单机版安装的配置文件们
- Hadoop单机版安装,配置,运行
- win7下hadoop编程eclipse的配置
- win7(64位)平台下Cygwin+Eclipse搭建Hadoop单机开发环境 (三) 在Eclipse中配置Hadoop
- Win7(64位)上编译、安装、配置、运行hadoop-Ver2.5.2---单机版配置运行