DB2数据库嵌入式SQL开发
2015-03-14 22:30
381 查看
如有转载,请注明出处:http://blog.csdn.net/embedded_sky
BY:super_bert@csdn
1.声明和初始化变量
2.连接到数据库
3.执行一个或者多个事务
4.与数据库断开连接
5.结束程序
一个事务是一组数据库操作,在提交给数据库之前,必须确认完全成功执行。在嵌入式SQL应用程序中,当应用程序成功地连接到一个数据库时,一个事务就自动开始了,结束于执行一条COMMIT语句或者ROLLBACK语句。同时,下一条SQL语句开始一个新的事务。
每一个应用程序的开始必须包括:
l 数据库管理器用来与宿主程序交互的所有变量和数据结构的声明
l 设置SQL通信区(SQLCA),提供错误处理的SQL语句
注意:用JAVA写的DB2应用程序在SQL语句出错时抛出一个SQLException异常,需要在catch块里处理,而不是使用SQLCA。
每个应用程序的主体包括访问和管理数据的SQL语句。这些语句组成事务,事务必须包括下列语句:
l CONNECT语句,其建立一个与数据库服务器的连接
l 一条或多条:
▲数据操纵语句(例如,SELECT语句)
▲数据定义语句(例如,CREATE语句)
▲数据控制语句(例如,GRANT语句)
l COMMIT或者ROLLBACK语句结束事务
应用程序的结束通常包括释放程序与数据库服务器的连接和释放其他资源的SQL语句。
l 将静态和动态 SQL 语句嵌入应用程序。
l 在应用程序中编写“DB2 调用层接口”(DB2 CLI) 的函数调用,以调用动态 SQL 语句。
l 开发调用“Java 数据库链接”应用程序设计接口 (JDBC API) 的 Java 应用程序和小程序。
l 开发符合“数据存取对象 (DAO) ”和“远程数据对象 (RDO) ” 规范的 Microsoft Visual Basic 和 Visual C++ 应用程序,以及使用“对象链接和嵌入数据库 (OLE DB) 桥接”的“ActiveX 数据对象”(ADO) 应用程序。
l 使用 IBM 或第三方工具如 Net.Data、Excel、Perl、“开放式数据库链接”(ODBC)最终用户工具如 LotusApproach 及其程序设计语言LotusScript 来开发应用程序。
l 要执行备份和复原数据库等管理功能,应用程序可以使用 DB2 API。
应用程序存取 DB2 数据库的方式将取决于想要开发的应用程序类型。例如,如果想开发数据输入应用程序,可以选择将静态 SQL 语句嵌入应用程序。如果想开发在万维网 (WWW) 上执行查询的应用程序,可能要选择 Net.Data、Perl 或 Java。
“结构化查询语言”(SQL) 是一种数据库接口语言,它用来存取并处理 DB2 数据库中的数据。可以将SQL 语句嵌入应用程序,使应用程序能执行 SQL 支持的任何任务,如检索或存储数据。通过使用 DB2,可以用 C/C++、COBOL、FORTRAN、Java (SQLJ) 以及 REXX 程序设计语言来编写嵌入式SQL 应用程序。
嵌入了 SQL 语句的应用程序称为主程序。用于创建主程序的程序设计语言称为宿主语言。用这种方式定义程序和语言,是因为它们包含了 SQL 语句。
对于静态 SQL 语句,您在编译前就知道SQL 语句类型以及表名和列名。唯一未知的是语句正搜索或更新的特定数据值。可以用宿主语言变量表示那些值。在运行应用程序之前,要预编译、编译和捆绑静态 SQL 语句。静态 SQL 最好在变动不大的数据库上运行。否则,这些语句很快会过时。
相反,动态 SQL 语句是应用程序在运行期构建并执行的那些语句。一个提示最终用户输入 SQL 语句的关键部分(如要搜索的表和列的名称)的交互式应用程序是动态 SQL 一个很好的示例。 应用程序在运行时构建 SQL 语句,然后提交这些语句进行处理。
可以编写只有静态 SQL 语句或只有动态 SQL 语句,或者兼有两者的应用程序。
一般来说,静态 SQL 语句最适合用于带有预定义事务的高性能应用程序。预订系统是这种应用程序一个很好的示例。
一般来说,动态 SQL 语句最适合于必须在运行期指定事务的、要快速更改数据库的应用程序。交互式查询界面是这种应用程序一个很好的示例。
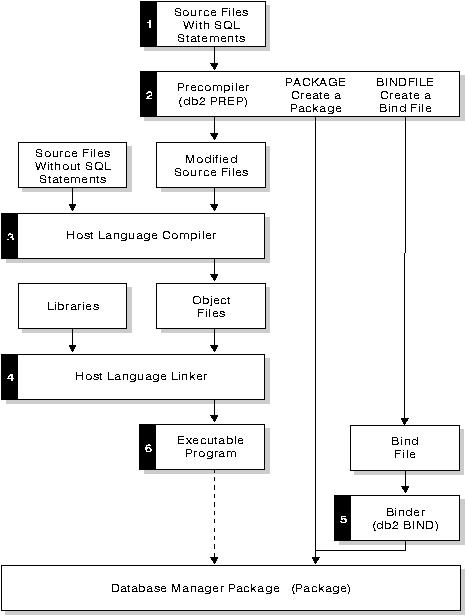
将 SQL 语句嵌入应用程序时,必须按以下步骤预编译应用程序并将其与数据库捆绑:
1. 创建源文件,以包含带嵌入式 SQL 语句的程序。
2. 连接数据库,然后预编译每个源文件。
预编译程序将每个源文件中的 SQL 语句转换成对数据库管理程序的DB2 运行期 API 调用。预编译程序还在数据库中生成一个存取程序包,并可选择生成一个捆绑文件(如果您指定要创建一个的话)。
存取程序包包含由 DB2 优化器为应用程序中的静态SQL 语句选择的存取方案。这些存取方案包含数据库管理程序执行静态 SQL 语句所需的信息,以便该管理程序可以用优化器确定的最有效的方式来执行这些语句。对于动态 SQL 语句,优化器在您运行应用程序时创建存取方案。
捆绑文件包含创建存取程序包所需要的 SQL 语句和其他数据。可以使用捆绑文件在以后重新捆绑应用程序,而不必首先预编译应用程序。重新捆绑创建针对当前数据库状态的优化存取方案。如果应用程序将存取与预编译时所用数据库不同的数据库,则必须重新捆绑应用程序。如果数据库统计信息自上次捆绑后已经更改,建议您重新捆绑应用程序。
3. 使用主语言编译程序编译修改的源文件(以及其他无 SQL 语句的文件)。
4. 将目标文件与 DB2 和主语言库连接,以生成一个可执行程序。
5. 如果在预编译时未对捆绑文件进行捆绑;或者准备存取不同数据库,则应对捆绑文件进行捆绑以创建存取程序包。
6. 运行该应用程序。此应用程序使用程序包中的存取方案存取数据库。
在预编译一个应用之前,必须连接到一个数据库服务器,不论是自动连接还是显性连接。即使你在客户端工作站上预编译应用程序、预编译器在客户端产生的修改后源文件和信息,预编译器也需要使用服务器连接来执行一些确认任务。
预编译器也创建数据库管理器在处理针对某个数据库的SQL语句时需要的信息。这些信息存储在一个程序包或者一个捆绑文件或者两者之中,视预编译器的选项而定。
下面是使用预编译器的一个典型例子。预编译一个名叫filename.sqc的C嵌入式SQL源文件,发出下面的命令创建一个C源文件,默认名字为filename.c,和一个捆绑文件,默认名字为filename.bnd:
DB2 PREP filename.sqc BINDFILE
预编译器最多产生四种类型的输出:
l 修改后的源文件
l 程序包
l 捆绑文件
l 信息文件
1、修改后的源文件
这个文件是预编译器将SQL语句转化为DB2运行时API调用后,原始源文件的新版本。它被赋予了相应宿主语言的扩展名。
2、程序包
如果使用了PACKAGE选项(默认的),或者没有指定任何BINDFILE、SYNTAX、SQLFLAG选项,程序包存储在所连接到的数据库中。程序包仅仅包含执行访问本数据的SQL语句时需要的所有信息。除非你用PACKAGE USING选项指定一个不同的名字,否则预编译器将使用源文件名字的前8个字符作为程序包名。
使用PACKAGE选项时,在预编译处理过程中使用的数据库必须拥有源文件中静态SQL语句参考到的所有数据库对象。例如不能够预编译一条SELECT语句,如果参考的表在数据库中不存在。
3、捆绑文件
如果使用了BINDFILE选项,预编译器将创建一个捆绑文件(扩展名为.bnd),它包含创建程序包的一些数据。这个文件可以在后面用BIND命令将应用捆绑到一个或多个数据库。如果指定了BINDFILE选项,没有指定PACKAGE选项,捆绑被延缓直到执行BIND命令。注意,对于命令行处理器(CLP),PREP默认不指定BINDFILE选项。因此,如果你使用CLP,又想延缓捆绑,那么你必须指定BINDFILE选项。
如果在预编译时请求一个捆绑文件但是没有指定PACKAGE选项,不会在数据库中创建程序包;对象不存在和没有权限的SQLCODE被看作警告而不会被看作错误。这使得你能够预编译程序和创建一个捆绑文件,不需要参考到的对象必须存在,也不需要你拥有执行正被预编译的SQL语句的权限。
4、信息文件(MessageFile)
如果使用了MESSAGES选项,预编译器将信息重定向到指定的文件中。这些信息包括警告和错误信息,它们描述了在预编译过程中产生的问题。如果源文件没有预编译成功,使用警告和错误信息来断定问题,改正源文件,然后再预编译。如果没有使用MESSAGE选项,预编译信息被写到标准输出上。
所有SQL语句经过编译优化后就产生可以直接对数据库进行访问的访问策略,存储于相应的数据库中。这些访问策略可以在应用程序调用相对应的SQL语句时得到访问。程序包对应于特定的应用程序,但是并不是与应用程序一起存放,而是同相对应的数据库一起存放。
下面是使用BIND命令的一个典型例子。将名为filename.bnd的捆绑文件捆绑到数据库,使用下面的命令:
DB2 BIND filename.bnd
每一个独立预编译的源代码模块都需要创建一个程序包。如果一个应用有5个源文件,其中3个需要预编译,那么要创建3个程序包或者3个捆绑文件。默认上,每一个程序包的名字与产生.bnd文件的源文件名字相同,但是只要前8个字符。如果新建的程序包名字与已存在于数据库中的程序包名相同,新的程序包将替换原先存在的程序包。要显性地指定一个不同的程序包名,必须在PREP命令使用PACKAGEUSING选项。
(1)连接类型1
应用程序在每个工作单元中只能连接单个数据库,此时,这个工作单元称为远程工作单元(RUOW, Remote Unit of Work)
(2)连接类型2
允许应用程序在每个工作单元中连接多个数据库,此时,这个工作单元称为分布式工作单元(DUOW, Distributed Unit of Work)
我们来看下面的例子:
(1)Remote Unit of Work – Type 1 Connect
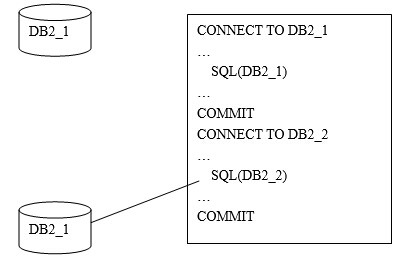
在这个例子中,连接类型为1,工作单元为远程工作单元(RUOW),应用程序在连接到数据库DB2_2之前,必须结束当前的工作单元(即事务,通过执行COMMIT语句)。
(2)Distributed Unit of Work – Type 2 Connect
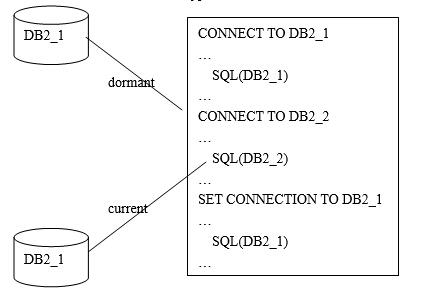
在这个例子中,连接类型为2,工作单元为分布式工作单元(DUOW)。应用程序在连接到数据库DB2_2之前,不需要结束当前的事务。在一个工作单元中,可以有多个数据库连接,但是只有一个处于激活状态,其它都处于睡眠状态。用SET CONNECTION TO db_name语句切换数据库连接。
数据库应用程序使用程序包的原因:提高性能和紧凑性。通过预编译SQL语句,使得SQL语句在创建应用程序时被编译进程序包,而不是在运行时。每一条语句都被分析,高效率的操作数串存储在程序包中。在运行时,预编译器产生的代码调用数据库管理器运行时服务APIs,根据输入输出数据的变量信息,执行程序包。
预编译的优点仅仅对静态SQL语句有效。动态执行的SQL语句不用预编译,但是它们在需要在运行时完成处理的整个步骤。注意:不要认为一条SQL语句的静态版本的执行效率一定比其动态版本的高。在某个方面,静态SQL语句快是因为不需要动态语句的准备开销。在另一方面,同样的语句,动态执行会快些,是因为优化器能利用当前数据库的统计信息,而不是以前的统计信息。有关静态SQL与动态SQL的比较,参照下表:
定界符的作用是使预编译器能够识别出需被翻译的SQL语句,并且必须标识出每一条嵌入的SQL语句。不同的宿主语言使用不同的定界符,下表列出了四种常用语言的定界符:
例子:
l SQL语句
UPDATE TEMPL
SET WORKDEPT= ‘C02’
WHERE WORKDEPT =‘C01’
l 在C程序中的SQL语句
EXEC SQL
UPDATE TEMPL
SET WORKDEPT = ‘C02’
WHERE WORKDEPT = ‘C01’ ;
l 在COBOL程序中的SQL语句
EXEC SQL
UPDATE TEMPL
SET WORKDEPT = ‘C02’
WHERE WORKDEPT = ‘C01’
END-EXEC.
一、嵌入SQL
嵌入SQL有其优势,它可以包含静态SQL或者动态SQL,或者两种类型混合使用。如果在开发应用程序时,SQL语句的格式和内容已经确定,应该考虑在程序中采用嵌入的静态SQL。利用静态SQL,执行应用程序的人暂时继承将应用程序捆绑到数据库中的用户的权限,而不需要对此人赋予其它权限(除了应用程序的执行权)。动态SQL的执行需要执行应用程序的人的权限,但也有例外情况,就是在捆绑应用程序的时候使用DYNAMICRULES BIND选项。一般来讲,如果直到执行时才能确定SQL语句,那么应该采用嵌入的动态SQL。这比较安全,而且可以处理更多形式的SQL。
注意:JAVA语言的嵌入SQL(SQLJ)应用程序只能嵌入静态SQL语句。然而,在SQLJ应用程序中,可以通过使用JDBC调用动态SQL语句。
在使用编程语言编译器前,必须对源文件进行预编译,将嵌入的SQL语句转换为宿主语言的数据库服务APIs。在应用程序运行之前,必须将程序中的SQL捆绑到数据库里。
我们在第三章“静态SQL应用编程”中有详细介绍。
二、DB2 CLI和ODBC
DB2调用级接口(DB2 CLI)是IBM公司数据库服务器的DB2系列可调用SQL接口,它是一个关系数据库数据访问的C和C++语言编程接口,它用函数调用的方式,将动态SQL语句作为参数传递给数据库管理器。也就是说,一个可调用的SQL接口就是一个调用动态SQL语句的应用程序编程接口(API)。CLI可以替代嵌入动态SQL,但是与嵌入SQL不同,它不需要预编译或者捆绑。
DB2 CLI是基于微软开放数据库连接(ODBC)规范和X/Open规范开发的。IBM选择这些规范是为了遵循业界标准,使熟悉这些数据库接口的应用程序开发人员能在短期内掌握CLI的开发方法。
JDBC:
DB2在Java语言方面的支持包括JDBC,JDBC是一个与厂商无关的动态SQL接口,利用它使得应用程序可以通过标准Java方法调用实现数据的访问。
JDBC与DB2 CLI一样不需要作预编译或者捆绑,作为一个与厂商无关的标准,JDBC应用程序具有良好的移植性。用JDBC开发的应用程序只采用动态SQL。
三、微软规范
开发符合“数据存取对象 (DAO) ”和“远程数据对象 (RDO) ” 规范的 Microsoft Visual Basic 和 Visual C++ 应用程序,以及使用“对象链接和嵌入数据库 (OLE DB) 桥接”的“ActiveX 数据对象 (ADO) ”应用程序。
四、Perl数据库接口
DB2支持Perl数据库接口(DBI)数据访问规范,使用DBD::DB2驱动程序。DBD::DB2驱动程序支持下列平台:
AIX
Operating Systems
Version 4.1.4 andlater
C Compilers
IBM C for AIX Version 3.1 andlater
HP-UX
Operating Systems
HP-UX Version 10.10 with PatchLevels: PHCO_6134, PHKL_5837,
PHKL_6133, PHKL_6189, PHKL_6273, PHSS_5956
HP-UX Version 10.20
HP-UX Version 11
C Compilers
HP C/HP-UX Version A.10.32
HP C Compiler Version A.11.00.00(for HP-UX Version 11)
Linux
Operating Systems
Linux Redhat Version 5.1with kernel 2.0.35 and glibc version 2.0.7
C Compilers
gcc version 2.7.2.3or later
Solaris
Operating Systems
Solaris Version 2.5.1
Solaris Version 2.6
C Compilers
SPARCompiler C Version 4.2
Windows NT
Operating Systems
Microsoft Windows NT version 4or later
C Compilers
Microsoft Visual C++ Version 5.0or later
从DB2通用数据Perl DBI网页(http://www.software.ibm.com/data/db2/perl/)上可以下载最新的DBD::DB2驱动程序的最新版本以及更多信息。
五、查询工具产品
查询工具产品包括IBM查询管理工具(QMF)和Lotus Notes,它们支持查询开发和报表。
一、数据类型
数据库将每一个数据元素存储在某个表的列中,并且每一列都用一个数据类型来定义,数据类型增加了此列放置数据的限制。例如,整数类型必须是在某个固定范围内的数字。在SQL语句中使用列也必须符合一定的行为,例如,数据库不能将一个整数与一个字符串比较。DB2有一组内置的数据类型,定义了特性和行为。DB2支持用户定义数据类型,叫做UDT,它们是基于内置的数据类型定义的。
二、唯一性约束
唯一性约束防止在一个表中,在一列或多列上出现重复的值。唯一主关键字也是唯一性约束。例如,在表DEPARTMENT的DEPTNO列上定义一个唯一性约束,防止将相同的部门号分配给两个部门。
如果对所有使用同一个表里的数据的应用程序都要执行一个唯一性规则,应当采用唯一性约束。
三、表检查约束
表检查约束(Table Check Constraint)限制在表中某列出现的值的范围。
四、参考完整性约束
通过定义唯一约束和外部关键字,可以定义表与表之间的关系,从而实施某些商业规则。唯一关键和外部关键字约束的组合通常称为参考完整性约束。 外部关键字所引用的唯一约束称为父关键字。 外部关键字表示特定的父关键字,或与特定的父关键字相关。例如,某规则可能规定每个雇员(EMPLOYEE 表)必须属于某现存的部门 (DEPARTMENT 表)。因此,将 EMPLOYEE 表中的“部门号”定义为外部关键字,而将 DEPARTMENT 表中的“部门号”定义为主关键字。下列图表提供参考完整性约束的直观说明。
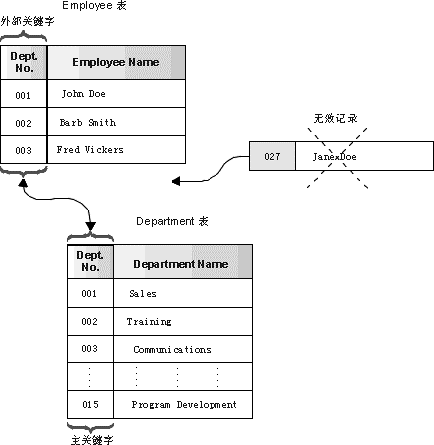
图 外部约束和主约束定义关系并保护数据
一、参考完整性约束
我们在前面已经介绍过。
二、触发器
一个触发器定义一组操作,这组操作通过修改指定基表中数据的操作来激活。
可使用触发器来执行对输入数据的验证;自动生成新插入行的值;为了交叉引用而读取其他表;为了审查跟踪而写入其他表; 或通过电子邮件信息支持警报。使用触发器将导致应用程序开发及商业规则的全面实施更快速并且应用程序 和数据的维护更容易。
DB2 通用数据库支持几种类型的触发器。可定义触发器在 DELETE、INSERT 或 UPDATE 操作之前或之后激活。 每个触发器包括一组称为触发操作的 SQL 语句, 这组语句可包括一个可选的搜索条件。
可进一步定义后触发器以对每一行都执行触发操作,或对语句执行一次触发操作,而前触发器总是 对每一行都执行触发操作。
在 INSERT、UPDATE 或 DELETE 语句之前使用触发器,以便在执行触发操作之前检查某些条件,或在将输入值存储在表中之前更改输入值。 使用后触发器,以便在必要时传播值或执行其他任务,如发送信息等,这些任务可能是触发器操作所要求的。
1.在预编译一个完整的程序之前,用命令行处理器(CLP)测试其中的SQL(可能不是全部)。
2.用解释设施估算程序中的DELETE, INSERT, UPDATE, 和 SELECT语句的开销和获取访问策略。根据解释设施的输出,改写SQL语句或者增加数据库对象(如索引)或者调节数据库服务器的参数。
1. 一个测试数据库. 如果应用程序要更新,插入或者删除来自表和视图的数据,那么使用测试数据检查执行情况;如果仅仅从表和视图中提取数据,可以考虑使用生产数据.
2. 测试的输入数据. 用来测试应用程序的测试数据应该是有效的,能体现所有可能输入情况. 也要用无效的数据去测试,看应用程序能否辨别出.
l INSERT...VALUES (an SQL statement) 每次可以插入一行或多行数据
l INSERT...SELECT 从一个已存在的表提取数据 (基于一个SELECT条款),并放入INSERT语句标识的表中.
l 用IMPORT和LOAD工具从定义的数据源插入大量的数据
l 用RESTORE工具从某个数据库的备份,将数据还原到特定的测试数据库
静态SQL语句,是指嵌入在宿主语言中的SQL语句在预编译时完全知道。这是相对于动态SQL而言的,动态SQL语句的语法在运行时才知道。注意:解释语言中不支持静态SQL语句,例如REXX只支持动态SQL语句。
一条SQL语句的结构在预编译时完全清楚,才被认为是静态的。例如,语句中涉及到的表(TABLES)和列的名字,在预编译时,必须完全知道,只能在运行时指定的是语句中引用的宿主变量的值。然而,宿主变量的信息,如数据类型,也必须在预编译时确定。
当静态SQL语句被准备时,SQL语句的可执行形式被创建,存储在数据库中的程序包里。SQL语句的可执行形式可以在预编译时创建或者在捆绑时创建。不论哪种情况,SQL语句的准备过程都发生在运行之前。捆绑应用程序的人需要有一定的权限,数据库管理器中的优化器还会根据数据库的统计信息和配置参数对SQL语句进行优化。对静态SQL语句来说,应用程序运行时,不会被优化。
/******************************************************************************
**
** Source File Name = static.sqc 1.4
**
** Licensed Materials - Property of IBM
**
*******************************************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "util.h"
#ifdef DB268K
/* Need to include ASLM for 68K applications */
#include <LibraryManager.h>
#endif
EXEC SQL INCLUDE SQLCA; /* :rk.1:erk. */
#define CHECKERR(CE_STR) if (check_error (CE_STR, &sqlca) != 0) return 1;
int main(int argc, char *argv[]) {
EXEC SQL BEGIN DECLARE SECTION; /* :rk.2:erk. */
char firstname[13];
char userid[9];
char passwd[19];
EXEC SQL END DECLARE SECTION;
#ifdef DB268K
/* Before making any API calls for 68K environment,
need to initial the Library Manager */
InitLibraryManager(0,kCurrentZone,kNormalMemory);
atexit(CleanupLibraryManager);
#endif
printf( "Sample C program: STATIC\n" );
if (argc == 1) {
EXEC SQL CONNECT TO sample;
CHECKERR ("CONNECT TO SAMPLE");
}
else if (argc == 3) {
strcpy (userid, argv[1]);
strcpy (passwd, argv[2]);
EXEC SQL CONNECT TO sample USER :userid USING :passwd; /* :rk.3:erk. */
CHECKERR ("CONNECT TO SAMPLE");
}
else {
printf ("\nUSAGE: static [userid passwd]\n\n");
return 1;
} /* endif */
EXEC SQL SELECT FIRSTNME INTO :firstname /* :rk.4:erk. */
FROM employee
WHERE LASTNAME = 'JOHNSON';
CHECKERR ("SELECT statement"); /* :rk.5:erk. */
printf( "First name = %s\n", firstname );
EXEC SQL CONNECT RESET; /* :rk.6:erk. */
CHECKERR ("CONNECT RESET");
return 0;
}
/* end of program : static.sqc */
这个例程中实现了一个选择至多一行(即单行)的查询,这样的查询可以通过一条SELECT INTO语句来执行。SELECT INTO 语句从数据库中的表选择一行数据,然后将这行数据的值赋予语句中指定的宿主变量(下节将要讨论宿主变量)。例如,下面的语句将姓为‘HAAS’的雇员的工资赋予宿主变量empsal:
SELECT SALARY
INTO :empsal
FROM EMPLOYEE
WHERE LASTNAME='HAAS'
一条SELECT INTO语句必须只能返回一行或者零行。如果结果集有多于一行,就会产生一个错误(SQLCODE –811,SQLSTATE 21000)。如果查询的结果集中有多行,就需要游标(CURSOR)来处理这些行。在节3.2.3中介绍如何使用游标。
静态程序是如何工作的呢?
1.包括结构SQLCA。 INCLUDESQLCA语句定义和声明了SQLCA结构,SQLCA结构中定义了SQLCODE和SQLSTATE域。数据库管理器在执行完每一条SQL语句或者每一个数据库管理器API调用,都要更新SQLCA结构中的SQLCODE域的诊断信息。
2.声明宿主变量。SQL BEGIN DECLARE SECTION和END DECLARE SECTION 语句界定宿主变量的声明。
有些变量在SQL语句中被引用。宿主变量用来将数据传递给数据库管理或者接收数据库管理器返回的数据。在SQL语句中引用宿主变量时,必须在宿主变量前加前缀冒号(:)。详细信息看下节。
3.连接到数据库。应用程序必须先连接到数据库,才能对数据库进行操作。这个程序连接到SAMPLE数据库,请求以共享方式访问。其他应用程序也可以同时以共享访问方式连接数据库
4.提取数据。SELECT INTO语句基于一个查询提取了一行值。这个例子从EMPLOYEE表中,将LASTNAME列的值为JOHNSON的相应行的FISRTNME列的值提取出来,置于宿主变量firstname中。
5.处理错误。CHECKERR 宏/函数是一个执行错误检查的外部函数。
因为在捆绑应用程序时,做捆绑的人需要有一定的授权,因此最终用户不需要执行程序包里的语句的直接权限。例如,一个应用程序可以只允许某个用户更新一个表的部分数据,而不用将更新整个表的权利给予这个用户。这个功能通过限制嵌入的静态SQL语句只能更新表中的某些列或者一定范围内的值,只将程序包的执行权限给予这个用户。
静态SQL语句是持久稳固的,动态SQL语句只是被缓存,直到变为无效、因为空间管理原因被清理或者数据库被关闭。如果需要,当被缓存的语句变为无效时,DB2 SQL编译器隐性地重新编译动态SQL语句。
静态SQL语句的主要优点是静态SQL在数据库关闭后仍然存在,而动态SQL语句在数据库关闭后就被清除了。另外,静态SQL在运行时不需要DB2 SQL编译器来编译,相反,动态SQL语句需要在运行时编译(例如,使用PREPARE语句)。因为DB2缓存动态SQL语句,这些语句也不总是需要DB2编译。但是,每一次运行程序至少需要编译一次。
静态SQL有性能上的优势。对简单、运行时间短的SQL程序,静态SQL语句 比相同目的的动态SQL语句执行得快。因为静态SQL语句准备执行形式的开销在预编译时间,而不是在运行时。
注意:静态SQL语句的性能决定于应用程序最后一次被捆绑时数据库的统计信息。 然而,如果这些统计信息改变了,那么比较起来,等效的动态SQL语句的性能可能好些。在某个使用静态SQL的应用程序捆绑之后,数据库增加了一个索引,如果这个应用程序不重新捆绑,就不能利用这个索引。还有,如果在静态SQL语句中使用宿主变量,优化器也不能使用表的分布信息来优化SQL语句。
下图显示在不同编程语言中声明宿主变量的例子。
下面是引用宿主变量的例子
在SQL语句中引用宿主变量时,必须加前缀—冒号(:)。冒号的作用是将宿主变量与SQL语法中的元素区分开。如果没有冒号,宿主变量会误解释为SQL语句的一部分。例如:
WORKDEPT = dept
将被解释为WORKDEPT列的值等于dept列的值。在宿主语言语句中,则不需要加前缀,正常引用即可。从下图中可看出如何使用宿主变量:
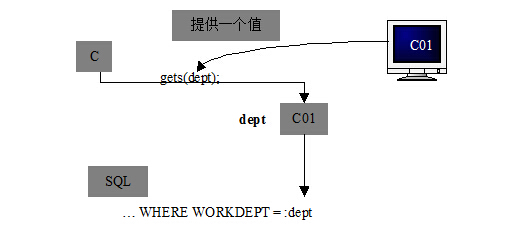
DB2名字空间(如表名、列名等等)不能用宿主变量指定。例如不能写如下SQL语句:
SELECT :col1 FROM:tabname
但是,这种类型的功能可以通过采用动态SQL实现。
总的来说,宿主变量有以下特点:
l 可选的,在语句运行之前用来赋值
l 宿主语言标号在SQL语句中,前面加冒号
l 宿主变量与列的数据类型必须匹配
l 对于宿主变量有以下要求:
a. 所有被嵌入SQL引用的宿主变量必须在BEGIN和END DECLARE语句界定的代码区里声明;
b. 宿主变量的数据类型必须与列的数据类型匹配,而且尽量避免数据转换和截取;
c. 宿主变量名不能以EXEC、SQL、sql开头;
d. 宿主变量应该被看作是模块程序的全局变量,而不是定义所在函数的局部变量;
e. 在界定区外定义的变量不能与界定区内定义的变量同名;
f. 在一个源文件中,可以有多个界定区;
g. BEGIN DECLARE SECTION语句可以在程序中宿主语言规则允许变量声明的任何位置出现,宿主变量定义区以ENDDECLARE SECTION语句结束;
h. BEGIN DECLARE SECTION和END DECLARE SECTION语句必须成对出现,并且不能嵌套;
i. 宿主变量声明可以使用SQL INCLUDE语句指定。另外,一个宿主变量声明区不能含有除宿主变量声明以外的语句。
1.在INSERT语句中的使用
l SQL语句
INSERT INTO TEMPL (EMPNO,LASTNAME)
VALUES (‘000190’, ‘JONES’)
l 嵌入程序的SQL语句
EXEC SQL INSERT INTO TEMPL (EMPNO, LASTNAME)
VALUES (:empno,:name);
第一条SQL语句可以在CLP中发出,它也可以嵌入程序中,但是它每一次只能插入一行值,如果要插入不同的值就要重新输入,程序也要修改。
第二条SQL语句只能嵌入程序中,每一次执行需要用户通过其它代码指定新值给宿主变量empno和name,宿主变量的作用是将用户指定的值传递给VALUES子句。可以实现输入多行值(循环或多次运行程序)。
2.在SET和WHERE子句中的使用
l SQL语句
UPDATE TEMPL
SET SALARY = SALARY *1.05
WHERE JOBCODE = 54
l 嵌入程序的SQL语句
EXEC SQL
UPDATE TEMPL
SET SALARY = SALARY *:percent
WHERE JOBCODE = :code;
3. 用宿主变量提取值。在程序中执行一个SELECT语句时,必须提供一个存储区域来接收返回的数据,而且对于被选择(selected)的每一列,都要定义一个宿主变量。语法为:SELECT … INTO :hostvaribale …。例子:
EXEC SQL
SELECT LASTNAME, WORKDEPT
INTO :name, :deptno
FROM TEMPL
WHERE EMPNO = :empid;
例子中定义了三个宿主变量,从表TEMPL中选择符合条件—EMPNO=:empid—的两列:LASTNAME和WORKDEPT,结果存放到宿主变量name和deptno中。此形式的用法要保证只能返回单行数据,如果返回多行数据库,则不能使用这种方法。后面会介绍如果使用游标(cursor)处理多行的返回结果集。
从上面的例子可将宿主变量分为两类:
l 输入宿主变量
输入宿主变量规定需要在语句执行期间从应用程序传递给数据库管理器的值。例如,在下面的SQL语句中将使用一个输入宿主变量:
SELECT name FROM candidate
WHERE name = < input host variable >
l 输出宿主变量
输出宿主变量规定需要在语句执行期间从数据库管理器传递给应用程序的值。例如,在下面的SQL语句中将使用一个输出宿主变量:
SELECT INTO <output host variable > FROM candidate
WHERE name = ‘HUTCHISON ’
指示符(indicator)变量是一种特殊的宿主变量类型,它用来表示列的空值或非空值。当这些宿主变量作为输入进入数据库中时,应当在执行SQL语句之前由应用程序对它们设置值。当这些宿主变量作为数据库的输出使用时,这些指示符由应用程序定义,但由DB2更新和将它们返回。然后,在结果被返回时,应用程序应当检查这些指示符变量的值。
看下面一条SQL语句:
SELECT COLA INTO:a:aind
其中a是宿主变量,aind是指示符变量。如果COLA列的值不为空,DB2将aind的值设置为非负(通常为0);如果COLA列的值为空,DB2将aind的值设置为负数(通常为-1);如果DB2试图提示一个空值的存在,但是程序没有提供指示符,将会产生错误,SQLCODE等于-305。
指示符变量的定义:
指示符变量的定义与宿主变量的定义方法相同,都需要在BEGIN DECLARE SECTION和END DECLARE SECTION之间定义,并且数据类型与SQL数据类型SMALLINT对应,在C语言中为SHORT类型。
例子:
如何设置指示符变量:
注解:
DB2在执行SELECT和FETCH语句的过程中设置指示符变量的值,应用程序应该在执行SELECT和FETCH语句后检查它们的值。
应用程序在执行UPDATE和INSERT语句之前设置指示符变量的值来指示DB2是否在数据库中放置一个空值(NULL)。
上表的第一行:在一条SELECT或者FETCH语句中,如果列(JOBCODE)中的值不为空,值被设置到宿主变量(:cd)中,指示符变量(:cdi)的值为零;如果列中的值为空,指示符变量的值将为负数,宿主变量的值不改变。
上表的第一行:在一条UPDATE或者INSERT语句中,如果指示符变量(:cdi)中的值不为负数,宿主变量(:cd)中的值被放到相应的列中;如果指示符变量中的值为负数,宿主变量中的值被忽略,相应的列被设置为空(NULL)。
指示符变量在数值转换方面的应用:
当宿主变量的数据类型与相应列的数据类型不兼容或者不能转换时,DB2也通过指示符变量通知应用程序。
数值转换由数据库管理器处理,能转换时自动完成,对程序透明;
如果列中的值不能存储到宿主变量中时(例如,列的数据类型为DECIMAL(15),值的长度为12个数字,不能存储到INTEGER类型的宿主变量中),指示符变量的值为-2。
指示符变量在截取方面的应用:
在SQL语句执行后,如果指示符变量的值为正数,说明发生了数据截取:
—如果是时间数据类型的秒部分被截取,那么指示符变量中的值为截取的秒数
—对于其他数据类型,指示符变量表示数据库中列的数据原始长度,通常为字节数(数据库尽可能返回更多的数据)。
例子:
定义宿主变量和指示符变量:
EXEC SQL BEGIN DECLARE SECTION;
char too_little[5];
short iv1;
EXEC SQL END DECLARE SECTION;
表BANK_ITEMS:
执行的SQL语句:
SELECT DESCRIPTION INTO :too_little:iv
FROM BANK_ITEMS WHERE ITEM# = 200
结果:
:too_little中的值为’CHECK’,:iv1中的值为10
为了理解游标的概念,我们假设数据库管理器创建了一个结果表(result table),里面包含有执行一条SELECT语句所提取的所有行。通过标识或指向这个表的“当前行”,游标使得结果表中的行对应用程序可用。当一个是拥游标时,应用程序可以顺序从结果表中提取每一行,直到产生一个数据结束条件,这个条件就是NOT FOUND条件,SQLCA中的SQLCODE为+100(SQLSTATE为02000)。执行SELECT语句的结果集,可能有零行、一行或者更多行,决定于有多少行符合搜索的条件。
处理一个游标涉及到以下几个步骤:
1.使用DECLARE CURSOR语句声明一个游标
2.使用OPEN语句执行查询和创建结果表
3.使用FETCH语句每次提取一行结果
4.使用DELETE或UPDATE语句处理行(如果需要)
5.使用CLOSE语句终止(关闭)游标
一个应用程序中,可以使用多个游标,但是每一个游标要有自己的DECLARE CURSOR,OPEN,CLOSE和FETCH语句集。
应用程序给游标分配一个名字。这个名字在随后的OPEN、FETCH和CLOSE语句中都要被参考到。查询可以是任何有效的SELECT语句。
下面例子展示了一条DECLARE语句如何与一条静态SELECT语句关联起来:
注解:DECLARE语句的在程序中位置是任意的,但是它必须在第一次使用游标的位置之前。
1.只读游标(Read Only Cursors)
如果一个游标被确定为只读的,并且使用可重复读隔离级(isolationlevel),那么系统表仍会收集和维护工作单元需要的可重复读锁。因此,即使只读游标,应用程序周期性地发出COMMIT语句还是很重要的。
2.有WITH HOLD选项
如果应用程序通过发出一条COMMIT语句来完成一个工作单元,除了声明时有WITH HOLD选项的游标,所有游标将自动地被数据库管理器关闭。
用WITH HOLD声明的游标维护它访问的跨多个工作单元的资源。用WITH HOLD声明的游标受到的影响依赖于工作单元如何结束。
如果工作单元使用一条COMMIT语句结束,已打开的定义为WITHHOLD的游标将保持打开状态。游标的位置在结果集的下一个逻辑行之前。另外,参考用WITH HOLD定义的已准备好的语句也会被保留。紧跟COMMIT语句后面, 只有与一个某个特定游标相关联的FETCH和CLOSE请求才有效。UPDATE WHERE CURRENT OF和DELETE WHERE CURRENT OF 语句仅仅对在同一个工作单元中提取的行有效。如果程序包在工作单元期间被重新绑定,那么所有保持的游标都会被关闭。
如果工作单元使用一条ROLLBACK语句结束,所有打开的游标被关闭,所有在工作单元中获得的锁被释放,以及所有依赖于这个工作单元的已准备好的语句被删除。
举个例子,假设TEMPL表中有1000条记录。要更新所有雇员的工资,应该每更新100行就要发出一条COMMIT语句。
A. 使用WITH HOLD选项声明游标:
EXEC SQL DECLARE EMPLUPDT CURSOR WITH HOLD FOR
SELECT EMPNO, LASTNAME,PHONENO, JOBCODE, SALARY
FROM TEMPL FOR UPDATE OF SALARY
B. 打开游标,每一次从结果表中提取一行数据:
EXEC SQL OPEN EMPLUPDT
.
.
.
EXEC SQL FETCH EMPLUPDT
INTO :upd_emp, :upd_lname, :upd_tele, :upd_jobcd, :upd_wage,
C. 当想要更新或者删除一行时,使用带WHERE CURRENT OF选项的UPDATE或者DELETE语句。例如,要更新当前行,程序可以发出下面的语句:
EXEC SQL UPDATE TEMPL SET SALARY =:newsalary
WHERE CURRENT OF EMPLUPDT
在一条COMMIT语句发出之后,在更新其它行之前必须发出FETCH语句。
如果应用程序使用了用WITH HOLD声明的游标或者执行了多个工作单元并且有一个用WITH HOLD声明的游标跨工作单元处于打开状态,那么在程序中应该加入代码检测和处理SQLCODE为-501(SQLSTATE为24501)的错误,这个错误由FETCH或者CLOSE语句返回。
如果应用程序的程序包由于其依赖的表被删除而变得无效,程序包会自动被重新绑定。这种情况下,FETCH或CLOSE语句返回SQLCODE –501(SQLSTATE 24501),因为 数据库管理器关闭游标。在此情形下,处理SQLCODE –501(SQLSTATE 24501)的方法决定于是否要从游标提取行数据。
l 如果要从游标提取行,打开游标,然后运行FETCH语句。注意,OPEN语句使得游标重定位到开始处。原来的位置信息丢失。
l 如果不准备从游标提取行,那么不要对游标发出任何SQL请求。
WITH RELEASE 选项:当应用程序用WITH RELEASE选项关闭一个游标时,DB2试图去释放游标持有的所有读锁(READ locks)。游标只继续持有写锁(WRITE locks)。如果应用程序没有用RELEASE选项关闭游标,那么在工作单元完成时,所有的读锁和写锁都被释放。
C Example: CURSOR.SQC
Java Example: Cursor.sqlj
游标程序如果工作:
1.声明游标。DECLARE CURSOR语句将游标c1与一个查询关联起来。查询确定应用程序使用FETCH语句提取的行。表staff的job字段被定义为可更新的,即使它在结果表中。
2.打开游标。游标c1被打开,数据库管理器执行查询并创建结果表。游标的指向位于第一行的前面。
3.提取一行。FETCH语句使游标指向下一行,将那行的内容移动到宿主变量中。那行成为当前行。
4.关闭游标。发出CLOSE语句,释放与游标相关联的资源。游标仍然可以再次打开。
更新提取的数据
为了利用游标来更新数据,在UPDATE语句中使用WHERECURRENT OF子句。使用FORUPDATE子句告诉系统结果表中的哪些列要更新。也可以在FOR UPDATE中指出不在选择范围之内的列,从另一个角度讲,可以更新不被游标提取的列。如果FOR UPDATE子句中没有指定任何列名,那么在第一个FROM子句中标识的表或者视图的所有列都被看作是可更新的。性能上要求只在FOR UPDATE子句里指定要更新的列,如果指定不需要更新的列,DB2将浪费没有必要的开销去访问数据。
删除提取的数据
为了利用游标来删除数据,在DELETE语句中使用WHERECURRENT OF条款。通常上,为了删除游标的当前行,定义游标时,不需要FOR UPDATE条款。一个例外情况是,在应用程序中使用动态的SELECT语句或者DELETE语句,预编译时LANGLEVEL选项设为SAA1,捆绑时使用BLOCKING ALL选项。这种情况下,SELECT语句需要FOR UPDATE条款。(详细信息请看3.3节开发动态SQL应用程序)
DELETE语句使得游标指示的那行被删除。游标的位置指向下一行的前面。要进行下一个WHERE CURRENT OF操作之前,必须对游标发出一条FETCH语句。
游标的类型
游标可以分为三类:
1.只读类型
游标指向的行只能够读,不能够更新。应用程序只是读取数据不修改时,使用只读游标。如果游标是基于只读SELECT语句,那么它便是只读的。只读游标在性能方面较好。
2.可更新类型
游标指向的行可以更新。应用程序需要修改提取的数据时,使用可更新游标。指定的查询只能涉及到一个表或视图。查询必须包含FOT UPDATE子句,并写出每一个要更新的列(除非预编译时使用LANGLEVEL MIA选项)。
3.不明确类型
从游标的定义或者上下文来确定游标是可更新的还是只读的。
当预编译或绑定时使用BLOCKING ALL选项,不明确的游标被看作是只读的。否则,被看作是可更新的。
注意:动态处理的游标通常是不明确类型的。
例子 OPENFTCH程序
这个例子使用一个游标从一个表中选择行,打开游标,从表中提取行。对提取的每一行,判断是否要删除或者更新(根据一个简单的条件)。这个例子有以下语言的版本:
C语言:openftch.sqc
Java语言:Openftch.sqlj and OpF_Curs.sqlj
COBOL语言:openftch.sqb
FORTRAN 语言:openftch.sqf
C Example: OPENFTCH.SQC
Java Example: Openftch.sqlj
OpF_Curs.sqlj
Openftch.sqlj
OPENFTCH程序是如何工作的:
1.声明游标。DECLARE CURSOR语句将游标c1与一个查询关联起来。查询确定应用程序使用FETCH语句提取的行。表staff的job字段被定义为可更新的,即使它不在结果表中。
2.打开游标。游标c1被打开,导致数据库管理器执行查询并创建一个结果表。游标的位置位于第一行的前面。
3.提取一行。FETCH语句将游标指向下一行,并将行的内容移到宿主变量中。那行成为当前行。
4.更新或删除当前行。当前行被更新或者被删除,决定于FETCH语句返回dept的值。
如果一个UPDATE语句被执行,游标的位置保持不变,因为UPDATE语句不改变当前行的位置。
如果一个DELETE语句被执行,游标的位置位于下一行的前面,因为当前行已被删除。在进行另外的WHERE CURRENT OF操作之前,必须执行一条FETCH语句。
5.关闭游标。CLOSE语句被发出,释放与游标关联的资源。游标可以被再次打开。
下面是SQLCA的C语言定义:
SQL_STRUCTURE sqlca
{
_SQLOLDCHAR sqlcaid[8]; /*Eyecatcher = 'SQLCA ' */
sqlint32 sqlcabc; /* SQLCA size in bytes = 136 */
sqlint32 sqlcode; /* SQLreturn code */
short sqlerrml; /* Lengthfor SQLERRMC */
_SQLOLDCHAR sqlerrmc[70]; /* Errormessage tokens */
_SQLOLDCHAR sqlerrp[8]; /*Diagnostic information */
sqlint32 sqlerrd[6]; /*Diagnostic information */
_SQLOLDCHAR sqlwarn[11]; /* Warningflags */
_SQLOLDCHAR sqlstate[5]; /* Statecorresponding to SQLCODE */
};
下表是SQLCA数据结构的详细描述:
对于大多数应用程序开发环境,为了创建和维护一个质量合格的软件,适当的错误处理是极其重要的。从应用程序中发出的每条SQL语句可能产生一个成功条件或一个错误条件。应用程序开发人员判定SQL语句结果的主要手段是检查SQL通信区(SQLCA)的内容。SQLCA是由DB2定义的宿主语言的数据结构。它包含着在处理SQL语句期间由DB2装填的许多数据元素。
[注解]:在DB2 REXX环境中自动地提供SQLCA
开发者的应用程序必须在发出任何SQL语句之前声明SQLCA(SQL 通信区)。有以下两种在程序中定义SQLCA的方法:
l 使用EXEC SQL INCLUDE SQLCA。
l 在DB2的头文件中声明一个叫做sqlca的结构。
在表中给出的SQLCA数据结构可以作为在应用程序与DB2之间处理错误的主要手段。关键的是开发者的应用程序要在执行每条SQL语句之后核查SQLCA的内容。不能核查SQLCA的内容可能会引起无法预料的错误发生。对于可能发生的许多错误,通常系统会向用户建议相应的措施(它们可以被编码到用户的应用程序中)。例如,假设开发者试图与数据库服务器相连接并且收到一个错误信息,说尚未启动数据库管理器。应用程序可以发出DB2START命令去启动数据库管理器,然后再次试图与数据库服务器相连接。
WHENEVER这一控制结构使预编译器产生的执行代码,使应用程序在遇到错误、警告或"没有行发现"时转到指定的代码段,继续执行相应的处理程序. WHENEVER对同一源程序中所有另一同类WHENEVER前的SQL执行语句均有效.
WHENEVER有三种基本形式:
1. EXEC SQL WHENEVER SQLERROR action
2. EXEC SQL WHENEVER SQLWARNING action
3. EXEC SQL WHENEVER NOT FOUND action
在这些形式中,SQLERROR指的是SQLCODE<0的情况;SQLWARNING指的是SQLWARN0 = ‘w’或者SQLCODE>0;NOT FOUND指的则是SQLCODE=+100的情况.
action可以是以下两种情况之一:
CONTINUE: 表示忽略这个异常,继续应用程序的下一步执行;
Go To label: 表示发生异常时,转到label所标识的语句开始.
例子:
SQLSTATE 是 DB2 系列产品的公共错误码。 SQLSTATE 符合 ISO/ANSI SQL92 标准。
例如,如果 CONNECT 语句中用户名或口令不正确,则数据库管理程序将返回信息标识符 SQL1403N 和 SQLSTATE 为 08004。该信息如下:
SQL1403N 提供的用户名和/或口令不正确。 SQLSTATE=08004
可以通过输入一个问号(?),然后输入信息标识符或SQLSTATE 来 获取关于错误信息的更多信息:
? SQL1403N
或
? SQL1403
或
? 08004
注意:错误 SQL1403N 的说明中倒数第二行表明 SQLCODE为-1403。 SQLCODE 为产品特定错误码。 以 N(通知)或 C(严重)结尾的信息标识符表示一个错误,并且具有负 SQLCODE。 以 W(警告)结尾的信息标识符表示一个警告,并且具有正 SQLCODE。
复合 SQL 允许您将几条 SQL 语句分组为单个的可执行块。包含于块中的 SQL 语句(子语句)可以单独执行;但是,通过创建和执行一个语句块,您可以减少数据库管理程序的额外开销。对于远程客户机,复合 SQL 也减少必须通过网络传送的请求的数目。
有两种类型的复合 SQL:
l 基本 (ATOMIC)
当所有子语句都成功完成时,或当一个子语句因出错而结束时,应用程序将从数据库管理程序收到一个响应。如果一个子语句因出错而结束,则将整个块视为因出错而结束,并且将回滚在此块中对数据库所做的任何更改。
l 非基本(NOT ATOMIC)
当所有子语句都完成时,应用程序将从数据库管理程序接收到一个响应。不管其前面的子语句是否成功执行,一个块中的所有子语句都要执行。仅当回滚包含非基本复合 SQL 的工作单元时,才可以回滚此语句组。
1. 这个例子演示了复合SQL语句的一个简单使用:将钱从银行存款帐号转到支票帐号,并将转帐记录在审计表中;
2. 关键字ATOMIC 指明:在其中的所有SQL语句都成功执行,复合SQL语句才算成功,也就是可以提交(COMMIT);如果其中有一条SQL语句失败,那么复合SQL语句中所有SQL语句对数据库所作的改变都被回滚(Roll Back);
3. 可以用关键字NOT ATOMIC替换ATOMIC。这样会忽略任何子语句的失败,数据库管理器不会回滚复合SQL语句中其他语句所作的改变。SQLCA中的信息指出有多少条语句处理成功和检测到的错误信息;
4. 关键字STATIC表示在复合SQL语句中引用的宿主变量在复合SQL语句被调用时获得的值,不会被复合SQL语句中的任何SQL语句改变。例如:
在每一条UPDATE和INSERT语句中使用:atmcard在复合SQL运行之前获得的值,而不是对应于‘Cartwright‘的值。
5. 语句:STOP AFTER FIRST host_var STATEMENTS可以加在BEGIN COMPOUND语句中,允许程序指定复合SQL语句执行时,只执行其中的多少条。例如:
将宿主变量:nbr的值设置为希望一次插入的行数。
6. 如果复合SQL语句中包含COMMIT语句,必须放在最后一条语句的位置,即在END COMPOUND之前。即使使用STOP AFTER FIRST host_varSTATEMENTS选项,并且host_var的值小于复合SQL语句中的SQL语句条数,COMMIT语句也会被执行。注意:当连接类型(CONNECT TYPE)为2时,不允许有COMMIT语句。
7. SQLSTATE和SQLCODE的值是复合SQL语句中的最后执行的语句的信息。
1. DB2 Connect只支持NOT ATOMIC类型的复合SQL语句
2. 复合SQL语句只能包含静态SQL语句
3. 复合SQL语句只能在嵌入SQL语句程序中使用
4. 下列语句不能包含在复合SQL语句中:
BY:super_bert@csdn
1.1 DB2应用程序开发概述
1.1.1 程序结构
DB2应用程序包括以下几个部分:1.声明和初始化变量
2.连接到数据库
3.执行一个或者多个事务
4.与数据库断开连接
5.结束程序
一个事务是一组数据库操作,在提交给数据库之前,必须确认完全成功执行。在嵌入式SQL应用程序中,当应用程序成功地连接到一个数据库时,一个事务就自动开始了,结束于执行一条COMMIT语句或者ROLLBACK语句。同时,下一条SQL语句开始一个新的事务。
每一个应用程序的开始必须包括:
l 数据库管理器用来与宿主程序交互的所有变量和数据结构的声明
l 设置SQL通信区(SQLCA),提供错误处理的SQL语句
注意:用JAVA写的DB2应用程序在SQL语句出错时抛出一个SQLException异常,需要在catch块里处理,而不是使用SQLCA。
每个应用程序的主体包括访问和管理数据的SQL语句。这些语句组成事务,事务必须包括下列语句:
l CONNECT语句,其建立一个与数据库服务器的连接
l 一条或多条:
▲数据操纵语句(例如,SELECT语句)
▲数据定义语句(例如,CREATE语句)
▲数据控制语句(例如,GRANT语句)
l COMMIT或者ROLLBACK语句结束事务
应用程序的结束通常包括释放程序与数据库服务器的连接和释放其他资源的SQL语句。
1.1.2 开发方法选择
可使用几种不同的程序设计接口来存取 DB2 数据库。您可以:l 将静态和动态 SQL 语句嵌入应用程序。
l 在应用程序中编写“DB2 调用层接口”(DB2 CLI) 的函数调用,以调用动态 SQL 语句。
l 开发调用“Java 数据库链接”应用程序设计接口 (JDBC API) 的 Java 应用程序和小程序。
l 开发符合“数据存取对象 (DAO) ”和“远程数据对象 (RDO) ” 规范的 Microsoft Visual Basic 和 Visual C++ 应用程序,以及使用“对象链接和嵌入数据库 (OLE DB) 桥接”的“ActiveX 数据对象”(ADO) 应用程序。
l 使用 IBM 或第三方工具如 Net.Data、Excel、Perl、“开放式数据库链接”(ODBC)最终用户工具如 LotusApproach 及其程序设计语言LotusScript 来开发应用程序。
l 要执行备份和复原数据库等管理功能,应用程序可以使用 DB2 API。
应用程序存取 DB2 数据库的方式将取决于想要开发的应用程序类型。例如,如果想开发数据输入应用程序,可以选择将静态 SQL 语句嵌入应用程序。如果想开发在万维网 (WWW) 上执行查询的应用程序,可能要选择 Net.Data、Perl 或 Java。
1.2相关概念
1.2.1 嵌入式SQL编程
嵌入式SQL应用程序就是将SQL语句嵌入某个宿主语言中,SQL语句提供数据库接口,宿主语言提供应用程序的其他执行功能。“结构化查询语言”(SQL) 是一种数据库接口语言,它用来存取并处理 DB2 数据库中的数据。可以将SQL 语句嵌入应用程序,使应用程序能执行 SQL 支持的任何任务,如检索或存储数据。通过使用 DB2,可以用 C/C++、COBOL、FORTRAN、Java (SQLJ) 以及 REXX 程序设计语言来编写嵌入式SQL 应用程序。
嵌入了 SQL 语句的应用程序称为主程序。用于创建主程序的程序设计语言称为宿主语言。用这种方式定义程序和语言,是因为它们包含了 SQL 语句。
对于静态 SQL 语句,您在编译前就知道SQL 语句类型以及表名和列名。唯一未知的是语句正搜索或更新的特定数据值。可以用宿主语言变量表示那些值。在运行应用程序之前,要预编译、编译和捆绑静态 SQL 语句。静态 SQL 最好在变动不大的数据库上运行。否则,这些语句很快会过时。
相反,动态 SQL 语句是应用程序在运行期构建并执行的那些语句。一个提示最终用户输入 SQL 语句的关键部分(如要搜索的表和列的名称)的交互式应用程序是动态 SQL 一个很好的示例。 应用程序在运行时构建 SQL 语句,然后提交这些语句进行处理。
可以编写只有静态 SQL 语句或只有动态 SQL 语句,或者兼有两者的应用程序。
一般来说,静态 SQL 语句最适合用于带有预定义事务的高性能应用程序。预订系统是这种应用程序一个很好的示例。
一般来说,动态 SQL 语句最适合于必须在运行期指定事务的、要快速更改数据库的应用程序。交互式查询界面是这种应用程序一个很好的示例。
将 SQL 语句嵌入应用程序时,必须按以下步骤预编译应用程序并将其与数据库捆绑:
1. 创建源文件,以包含带嵌入式 SQL 语句的程序。
2. 连接数据库,然后预编译每个源文件。
预编译程序将每个源文件中的 SQL 语句转换成对数据库管理程序的DB2 运行期 API 调用。预编译程序还在数据库中生成一个存取程序包,并可选择生成一个捆绑文件(如果您指定要创建一个的话)。
存取程序包包含由 DB2 优化器为应用程序中的静态SQL 语句选择的存取方案。这些存取方案包含数据库管理程序执行静态 SQL 语句所需的信息,以便该管理程序可以用优化器确定的最有效的方式来执行这些语句。对于动态 SQL 语句,优化器在您运行应用程序时创建存取方案。
捆绑文件包含创建存取程序包所需要的 SQL 语句和其他数据。可以使用捆绑文件在以后重新捆绑应用程序,而不必首先预编译应用程序。重新捆绑创建针对当前数据库状态的优化存取方案。如果应用程序将存取与预编译时所用数据库不同的数据库,则必须重新捆绑应用程序。如果数据库统计信息自上次捆绑后已经更改,建议您重新捆绑应用程序。
3. 使用主语言编译程序编译修改的源文件(以及其他无 SQL 语句的文件)。
4. 将目标文件与 DB2 和主语言库连接,以生成一个可执行程序。
5. 如果在预编译时未对捆绑文件进行捆绑;或者准备存取不同数据库,则应对捆绑文件进行捆绑以创建存取程序包。
6. 运行该应用程序。此应用程序使用程序包中的存取方案存取数据库。
1.2.2 预编译
创建源文件之后,必须对每一个含有SQL语句的宿主语言文件用PREP命令进行预编译。预编译器将源文件中的SQL语句注释掉,对那些语句生成DB2运行时API调用。在预编译一个应用之前,必须连接到一个数据库服务器,不论是自动连接还是显性连接。即使你在客户端工作站上预编译应用程序、预编译器在客户端产生的修改后源文件和信息,预编译器也需要使用服务器连接来执行一些确认任务。
预编译器也创建数据库管理器在处理针对某个数据库的SQL语句时需要的信息。这些信息存储在一个程序包或者一个捆绑文件或者两者之中,视预编译器的选项而定。
下面是使用预编译器的一个典型例子。预编译一个名叫filename.sqc的C嵌入式SQL源文件,发出下面的命令创建一个C源文件,默认名字为filename.c,和一个捆绑文件,默认名字为filename.bnd:
DB2 PREP filename.sqc BINDFILE
预编译器最多产生四种类型的输出:
l 修改后的源文件
l 程序包
l 捆绑文件
l 信息文件
1、修改后的源文件
这个文件是预编译器将SQL语句转化为DB2运行时API调用后,原始源文件的新版本。它被赋予了相应宿主语言的扩展名。
2、程序包
如果使用了PACKAGE选项(默认的),或者没有指定任何BINDFILE、SYNTAX、SQLFLAG选项,程序包存储在所连接到的数据库中。程序包仅仅包含执行访问本数据的SQL语句时需要的所有信息。除非你用PACKAGE USING选项指定一个不同的名字,否则预编译器将使用源文件名字的前8个字符作为程序包名。
使用PACKAGE选项时,在预编译处理过程中使用的数据库必须拥有源文件中静态SQL语句参考到的所有数据库对象。例如不能够预编译一条SELECT语句,如果参考的表在数据库中不存在。
3、捆绑文件
如果使用了BINDFILE选项,预编译器将创建一个捆绑文件(扩展名为.bnd),它包含创建程序包的一些数据。这个文件可以在后面用BIND命令将应用捆绑到一个或多个数据库。如果指定了BINDFILE选项,没有指定PACKAGE选项,捆绑被延缓直到执行BIND命令。注意,对于命令行处理器(CLP),PREP默认不指定BINDFILE选项。因此,如果你使用CLP,又想延缓捆绑,那么你必须指定BINDFILE选项。
如果在预编译时请求一个捆绑文件但是没有指定PACKAGE选项,不会在数据库中创建程序包;对象不存在和没有权限的SQLCODE被看作警告而不会被看作错误。这使得你能够预编译程序和创建一个捆绑文件,不需要参考到的对象必须存在,也不需要你拥有执行正被预编译的SQL语句的权限。
4、信息文件(MessageFile)
如果使用了MESSAGES选项,预编译器将信息重定向到指定的文件中。这些信息包括警告和错误信息,它们描述了在预编译过程中产生的问题。如果源文件没有预编译成功,使用警告和错误信息来断定问题,改正源文件,然后再预编译。如果没有使用MESSAGE选项,预编译信息被写到标准输出上。
1.2.3 程序包
程序包就是存储在相对应数据库中的包含数据库系统在捆绑时对特定SQL语句所产生的访问策略。所有SQL语句经过编译优化后就产生可以直接对数据库进行访问的访问策略,存储于相应的数据库中。这些访问策略可以在应用程序调用相对应的SQL语句时得到访问。程序包对应于特定的应用程序,但是并不是与应用程序一起存放,而是同相对应的数据库一起存放。
1.2.4 捆绑
捆绑(bind)是创建数据库管理器在应用执行时为了访问数据库而需要的程序包的过程。捆绑可以在预编译时指定PACKAGE选项隐含地完成,或者使用BIND命令依据预编译过程中产生的捆绑文件显性地完成。下面是使用BIND命令的一个典型例子。将名为filename.bnd的捆绑文件捆绑到数据库,使用下面的命令:
DB2 BIND filename.bnd
每一个独立预编译的源代码模块都需要创建一个程序包。如果一个应用有5个源文件,其中3个需要预编译,那么要创建3个程序包或者3个捆绑文件。默认上,每一个程序包的名字与产生.bnd文件的源文件名字相同,但是只要前8个字符。如果新建的程序包名字与已存在于数据库中的程序包名相同,新的程序包将替换原先存在的程序包。要显性地指定一个不同的程序包名,必须在PREP命令使用PACKAGEUSING选项。
1.2.5 工作单元
一个工作单元是一个单一的逻辑事务。它包含一个SQL语句序列,在这个序列中的所有操作,被看作一个整体,要么都成功,要么都失败。DB2支持两种类型的连接(connection)。连接类型决定一个应用程序如何与远程数据库工作,并且决定该应用程序同时能与多少个数据库工作。(1)连接类型1
应用程序在每个工作单元中只能连接单个数据库,此时,这个工作单元称为远程工作单元(RUOW, Remote Unit of Work)
(2)连接类型2
允许应用程序在每个工作单元中连接多个数据库,此时,这个工作单元称为分布式工作单元(DUOW, Distributed Unit of Work)
我们来看下面的例子:
(1)Remote Unit of Work – Type 1 Connect
在这个例子中,连接类型为1,工作单元为远程工作单元(RUOW),应用程序在连接到数据库DB2_2之前,必须结束当前的工作单元(即事务,通过执行COMMIT语句)。
(2)Distributed Unit of Work – Type 2 Connect
在这个例子中,连接类型为2,工作单元为分布式工作单元(DUOW)。应用程序在连接到数据库DB2_2之前,不需要结束当前的事务。在一个工作单元中,可以有多个数据库连接,但是只有一个处于激活状态,其它都处于睡眠状态。用SET CONNECTION TO db_name语句切换数据库连接。
1.2.6 应用程序、捆绑文件与程序包之间的关系
一个程序包是一个存储在数据库中的对象,它包含在执行某个源文件中特定SQL语句时所需的信息。数据库应用程序对用来创建应用程序的每一个预编译源文件使用一个程序包。每一个程序包是一个独立的实体,同一个或不同应用程序所使用的程序包之间没有任何关系。程序包在对源文件执行附带绑定的预编译时创建,或者通过绑定绑定文件创建。数据库应用程序使用程序包的原因:提高性能和紧凑性。通过预编译SQL语句,使得SQL语句在创建应用程序时被编译进程序包,而不是在运行时。每一条语句都被分析,高效率的操作数串存储在程序包中。在运行时,预编译器产生的代码调用数据库管理器运行时服务APIs,根据输入输出数据的变量信息,执行程序包。
预编译的优点仅仅对静态SQL语句有效。动态执行的SQL语句不用预编译,但是它们在需要在运行时完成处理的整个步骤。注意:不要认为一条SQL语句的静态版本的执行效率一定比其动态版本的高。在某个方面,静态SQL语句快是因为不需要动态语句的准备开销。在另一方面,同样的语句,动态执行会快些,是因为优化器能利用当前数据库的统计信息,而不是以前的统计信息。有关静态SQL与动态SQL的比较,参照下表:
| 表-静态SQL与动态SQL的比较 考虑因素 最好的选择 执行SQL语句的时间: 少于两秒 静态 2 到10 秒 两者均可 多于10秒 动态 数据一致性 统一的数据分布 静态 轻微不统一分布 两者均可 高度不统一分布 动态 范围谓词(<,>,BETWEEN,LIKE)使用 很少使用 静态 偶然使用 两者均可 经常使用 动态 执行的重复性 很多次(10或者更多) 两者均可 几次(少于10次) 两者均可 一次 静态 查询的种类 随机 动态 固定 两者均可 运行时环境(DML/DDL) 事务处理(DML Only) 两者均可 混合(DML和DDL – DDL affects packages) 动态 混合(DML和DDL – DDL does not affect packages) 两者均可 运行runstats的频度 很低 静态 正常 两者均可 频繁 动态 |
1.2.7 定界符
如果源程序中有SQL语句,源程序不能立即被源语言编译器处理。它首先要经过一个翻译过程,将SQL语句翻译成源语言编译器能够理解的东西。做翻译工作的程序就叫做预编译器。预编译器识别SQL语句的方法是通过定界符将SQL语句标识出来。定界符的作用是使预编译器能够识别出需被翻译的SQL语句,并且必须标识出每一条嵌入的SQL语句。不同的宿主语言使用不同的定界符,下表列出了四种常用语言的定界符:
| 语言 | 定界符 |
| C;C++ | EXEC SQL sql statement ; |
| COBOL | EXEC SQL sql statement END-EXEC. |
| FORTRAN | EXEC SQL sql statement |
| JAVA | #sqlj {sql statement} ; |
例子:
l SQL语句
UPDATE TEMPL
SET WORKDEPT= ‘C02’
WHERE WORKDEPT =‘C01’
l 在C程序中的SQL语句
EXEC SQL
UPDATE TEMPL
SET WORKDEPT = ‘C02’
WHERE WORKDEPT = ‘C01’ ;
l 在COBOL程序中的SQL语句
EXEC SQL
UPDATE TEMPL
SET WORKDEPT = ‘C02’
WHERE WORKDEPT = ‘C01’
END-EXEC.
2.1编程方法
2.1.1 访问数据
在关系数据库中,必须使用SQL访问请求的数据,但是可以选择如何将SQL结合到应用程序中去。可以从下表列出的接口和它们支持的语言中选择:| 接口 | 支持的语言 |
| 嵌入SQL | C/C++, COBOL, FORTRAN, Java (SQLJ), REXX |
| DB2 CLI 和ODBC | C/C++, Java (JDBC) |
| Microsoft Specifications, including ADO, RDO, and OLE DB | Visual Basic, Visual C++ |
| Perl DBI | Perl |
| Query Products | Lotus Approach, IBM Query Management Facility |
嵌入SQL有其优势,它可以包含静态SQL或者动态SQL,或者两种类型混合使用。如果在开发应用程序时,SQL语句的格式和内容已经确定,应该考虑在程序中采用嵌入的静态SQL。利用静态SQL,执行应用程序的人暂时继承将应用程序捆绑到数据库中的用户的权限,而不需要对此人赋予其它权限(除了应用程序的执行权)。动态SQL的执行需要执行应用程序的人的权限,但也有例外情况,就是在捆绑应用程序的时候使用DYNAMICRULES BIND选项。一般来讲,如果直到执行时才能确定SQL语句,那么应该采用嵌入的动态SQL。这比较安全,而且可以处理更多形式的SQL。
注意:JAVA语言的嵌入SQL(SQLJ)应用程序只能嵌入静态SQL语句。然而,在SQLJ应用程序中,可以通过使用JDBC调用动态SQL语句。
在使用编程语言编译器前,必须对源文件进行预编译,将嵌入的SQL语句转换为宿主语言的数据库服务APIs。在应用程序运行之前,必须将程序中的SQL捆绑到数据库里。
我们在第三章“静态SQL应用编程”中有详细介绍。
二、DB2 CLI和ODBC
DB2调用级接口(DB2 CLI)是IBM公司数据库服务器的DB2系列可调用SQL接口,它是一个关系数据库数据访问的C和C++语言编程接口,它用函数调用的方式,将动态SQL语句作为参数传递给数据库管理器。也就是说,一个可调用的SQL接口就是一个调用动态SQL语句的应用程序编程接口(API)。CLI可以替代嵌入动态SQL,但是与嵌入SQL不同,它不需要预编译或者捆绑。
DB2 CLI是基于微软开放数据库连接(ODBC)规范和X/Open规范开发的。IBM选择这些规范是为了遵循业界标准,使熟悉这些数据库接口的应用程序开发人员能在短期内掌握CLI的开发方法。
JDBC:
DB2在Java语言方面的支持包括JDBC,JDBC是一个与厂商无关的动态SQL接口,利用它使得应用程序可以通过标准Java方法调用实现数据的访问。
JDBC与DB2 CLI一样不需要作预编译或者捆绑,作为一个与厂商无关的标准,JDBC应用程序具有良好的移植性。用JDBC开发的应用程序只采用动态SQL。
三、微软规范
开发符合“数据存取对象 (DAO) ”和“远程数据对象 (RDO) ” 规范的 Microsoft Visual Basic 和 Visual C++ 应用程序,以及使用“对象链接和嵌入数据库 (OLE DB) 桥接”的“ActiveX 数据对象 (ADO) ”应用程序。
四、Perl数据库接口
DB2支持Perl数据库接口(DBI)数据访问规范,使用DBD::DB2驱动程序。DBD::DB2驱动程序支持下列平台:
AIX
Operating Systems
Version 4.1.4 andlater
C Compilers
IBM C for AIX Version 3.1 andlater
HP-UX
Operating Systems
HP-UX Version 10.10 with PatchLevels: PHCO_6134, PHKL_5837,
PHKL_6133, PHKL_6189, PHKL_6273, PHSS_5956
HP-UX Version 10.20
HP-UX Version 11
C Compilers
HP C/HP-UX Version A.10.32
HP C Compiler Version A.11.00.00(for HP-UX Version 11)
Linux
Operating Systems
Linux Redhat Version 5.1with kernel 2.0.35 and glibc version 2.0.7
C Compilers
gcc version 2.7.2.3or later
Solaris
Operating Systems
Solaris Version 2.5.1
Solaris Version 2.6
C Compilers
SPARCompiler C Version 4.2
Windows NT
Operating Systems
Microsoft Windows NT version 4or later
C Compilers
Microsoft Visual C++ Version 5.0or later
从DB2通用数据Perl DBI网页(http://www.software.ibm.com/data/db2/perl/)上可以下载最新的DBD::DB2驱动程序的最新版本以及更多信息。
五、查询工具产品
查询工具产品包括IBM查询管理工具(QMF)和Lotus Notes,它们支持查询开发和报表。
2.1.2 数据值控制
应用程序的部分逻辑是通过控制数据库中允许的值得到实施和保护数据完整的。DB2提供了几个不同的方法。一、数据类型
数据库将每一个数据元素存储在某个表的列中,并且每一列都用一个数据类型来定义,数据类型增加了此列放置数据的限制。例如,整数类型必须是在某个固定范围内的数字。在SQL语句中使用列也必须符合一定的行为,例如,数据库不能将一个整数与一个字符串比较。DB2有一组内置的数据类型,定义了特性和行为。DB2支持用户定义数据类型,叫做UDT,它们是基于内置的数据类型定义的。
二、唯一性约束
唯一性约束防止在一个表中,在一列或多列上出现重复的值。唯一主关键字也是唯一性约束。例如,在表DEPARTMENT的DEPTNO列上定义一个唯一性约束,防止将相同的部门号分配给两个部门。
如果对所有使用同一个表里的数据的应用程序都要执行一个唯一性规则,应当采用唯一性约束。
三、表检查约束
表检查约束(Table Check Constraint)限制在表中某列出现的值的范围。
四、参考完整性约束
通过定义唯一约束和外部关键字,可以定义表与表之间的关系,从而实施某些商业规则。唯一关键和外部关键字约束的组合通常称为参考完整性约束。 外部关键字所引用的唯一约束称为父关键字。 外部关键字表示特定的父关键字,或与特定的父关键字相关。例如,某规则可能规定每个雇员(EMPLOYEE 表)必须属于某现存的部门 (DEPARTMENT 表)。因此,将 EMPLOYEE 表中的“部门号”定义为外部关键字,而将 DEPARTMENT 表中的“部门号”定义为主关键字。下列图表提供参考完整性约束的直观说明。
图 外部约束和主约束定义关系并保护数据
2.1.3 数据关系控制
应用程序逻辑的另外一个主要任务是管理系统中不同实体之间的关系。例如,如果增加一个新的部门,就要创建一个新的帐号。DB2提供了管理数据库中不同实体之间的管理的两种方法:参考完整性约束和触发器。一、参考完整性约束
我们在前面已经介绍过。
二、触发器
一个触发器定义一组操作,这组操作通过修改指定基表中数据的操作来激活。
可使用触发器来执行对输入数据的验证;自动生成新插入行的值;为了交叉引用而读取其他表;为了审查跟踪而写入其他表; 或通过电子邮件信息支持警报。使用触发器将导致应用程序开发及商业规则的全面实施更快速并且应用程序 和数据的维护更容易。
DB2 通用数据库支持几种类型的触发器。可定义触发器在 DELETE、INSERT 或 UPDATE 操作之前或之后激活。 每个触发器包括一组称为触发操作的 SQL 语句, 这组语句可包括一个可选的搜索条件。
可进一步定义后触发器以对每一行都执行触发操作,或对语句执行一次触发操作,而前触发器总是 对每一行都执行触发操作。
在 INSERT、UPDATE 或 DELETE 语句之前使用触发器,以便在执行触发操作之前检查某些条件,或在将输入值存储在表中之前更改输入值。 使用后触发器,以便在必要时传播值或执行其他任务,如发送信息等,这些任务可能是触发器操作所要求的。
2.1.4 服务器上的应用逻辑
DB2提供了将应用程序程序的部分在数据库服务器上运行的功能,通常是为了提高性能和支持公共功能。主要方法有:存储过程,UDF,触发器。2.1.5 构造SQL语句的原型
当设计和编写应用程序时,利用数据库管理器的特性和一些工具来构造SQL语句的原型,提高执行性能。可以按照下面的方法优化SQL语句:1.在预编译一个完整的程序之前,用命令行处理器(CLP)测试其中的SQL(可能不是全部)。
2.用解释设施估算程序中的DELETE, INSERT, UPDATE, 和 SELECT语句的开销和获取访问策略。根据解释设施的输出,改写SQL语句或者增加数据库对象(如索引)或者调节数据库服务器的参数。
2.2 设置测试环境
在进行DB2应用开发时,需要建立测试环境。一个测试环境,应该包括:1. 一个测试数据库. 如果应用程序要更新,插入或者删除来自表和视图的数据,那么使用测试数据检查执行情况;如果仅仅从表和视图中提取数据,可以考虑使用生产数据.
2. 测试的输入数据. 用来测试应用程序的测试数据应该是有效的,能体现所有可能输入情况. 也要用无效的数据去测试,看应用程序能否辨别出.
2.2.1 创建测试数据库
可以使用CLP发出CreateDatabase dbname语句创建测试数据库,也可以使用数据库管理器API编写一个程序来创建测试数据库.2.2.2 创建测试表
先分析应用程序的数据需求,然后使用CREATE TABLE语句创建测试表.2.2.3 生成测试数据
使用下面任何一种方法将数据插入表中:l INSERT...VALUES (an SQL statement) 每次可以插入一行或多行数据
l INSERT...SELECT 从一个已存在的表提取数据 (基于一个SELECT条款),并放入INSERT语句标识的表中.
l 用IMPORT和LOAD工具从定义的数据源插入大量的数据
l 用RESTORE工具从某个数据库的备份,将数据还原到特定的测试数据库
静态SQL语句,是指嵌入在宿主语言中的SQL语句在预编译时完全知道。这是相对于动态SQL而言的,动态SQL语句的语法在运行时才知道。注意:解释语言中不支持静态SQL语句,例如REXX只支持动态SQL语句。
一条SQL语句的结构在预编译时完全清楚,才被认为是静态的。例如,语句中涉及到的表(TABLES)和列的名字,在预编译时,必须完全知道,只能在运行时指定的是语句中引用的宿主变量的值。然而,宿主变量的信息,如数据类型,也必须在预编译时确定。
当静态SQL语句被准备时,SQL语句的可执行形式被创建,存储在数据库中的程序包里。SQL语句的可执行形式可以在预编译时创建或者在捆绑时创建。不论哪种情况,SQL语句的准备过程都发生在运行之前。捆绑应用程序的人需要有一定的权限,数据库管理器中的优化器还会根据数据库的统计信息和配置参数对SQL语句进行优化。对静态SQL语句来说,应用程序运行时,不会被优化。
3.1 静态SQL程序的结构和特点
3.1.1 例程
下面先来看一个静态SQL程序的C语言例子。这个例程演示了静态SQL语句的使用,它将表中LASTNAME列等于‘JOHNSON’的记录的FIRSTNME列的值输出,否则打印错误信息。/******************************************************************************
**
** Source File Name = static.sqc 1.4
**
** Licensed Materials - Property of IBM
**
*******************************************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "util.h"
#ifdef DB268K
/* Need to include ASLM for 68K applications */
#include <LibraryManager.h>
#endif
EXEC SQL INCLUDE SQLCA; /* :rk.1:erk. */
#define CHECKERR(CE_STR) if (check_error (CE_STR, &sqlca) != 0) return 1;
int main(int argc, char *argv[]) {
EXEC SQL BEGIN DECLARE SECTION; /* :rk.2:erk. */
char firstname[13];
char userid[9];
char passwd[19];
EXEC SQL END DECLARE SECTION;
#ifdef DB268K
/* Before making any API calls for 68K environment,
need to initial the Library Manager */
InitLibraryManager(0,kCurrentZone,kNormalMemory);
atexit(CleanupLibraryManager);
#endif
printf( "Sample C program: STATIC\n" );
if (argc == 1) {
EXEC SQL CONNECT TO sample;
CHECKERR ("CONNECT TO SAMPLE");
}
else if (argc == 3) {
strcpy (userid, argv[1]);
strcpy (passwd, argv[2]);
EXEC SQL CONNECT TO sample USER :userid USING :passwd; /* :rk.3:erk. */
CHECKERR ("CONNECT TO SAMPLE");
}
else {
printf ("\nUSAGE: static [userid passwd]\n\n");
return 1;
} /* endif */
EXEC SQL SELECT FIRSTNME INTO :firstname /* :rk.4:erk. */
FROM employee
WHERE LASTNAME = 'JOHNSON';
CHECKERR ("SELECT statement"); /* :rk.5:erk. */
printf( "First name = %s\n", firstname );
EXEC SQL CONNECT RESET; /* :rk.6:erk. */
CHECKERR ("CONNECT RESET");
return 0;
}
/* end of program : static.sqc */
这个例程中实现了一个选择至多一行(即单行)的查询,这样的查询可以通过一条SELECT INTO语句来执行。SELECT INTO 语句从数据库中的表选择一行数据,然后将这行数据的值赋予语句中指定的宿主变量(下节将要讨论宿主变量)。例如,下面的语句将姓为‘HAAS’的雇员的工资赋予宿主变量empsal:
SELECT SALARY
INTO :empsal
FROM EMPLOYEE
WHERE LASTNAME='HAAS'
一条SELECT INTO语句必须只能返回一行或者零行。如果结果集有多于一行,就会产生一个错误(SQLCODE –811,SQLSTATE 21000)。如果查询的结果集中有多行,就需要游标(CURSOR)来处理这些行。在节3.2.3中介绍如何使用游标。
静态程序是如何工作的呢?
1.包括结构SQLCA。 INCLUDESQLCA语句定义和声明了SQLCA结构,SQLCA结构中定义了SQLCODE和SQLSTATE域。数据库管理器在执行完每一条SQL语句或者每一个数据库管理器API调用,都要更新SQLCA结构中的SQLCODE域的诊断信息。
2.声明宿主变量。SQL BEGIN DECLARE SECTION和END DECLARE SECTION 语句界定宿主变量的声明。
有些变量在SQL语句中被引用。宿主变量用来将数据传递给数据库管理或者接收数据库管理器返回的数据。在SQL语句中引用宿主变量时,必须在宿主变量前加前缀冒号(:)。详细信息看下节。
3.连接到数据库。应用程序必须先连接到数据库,才能对数据库进行操作。这个程序连接到SAMPLE数据库,请求以共享方式访问。其他应用程序也可以同时以共享访问方式连接数据库
4.提取数据。SELECT INTO语句基于一个查询提取了一行值。这个例子从EMPLOYEE表中,将LASTNAME列的值为JOHNSON的相应行的FISRTNME列的值提取出来,置于宿主变量firstname中。
5.处理错误。CHECKERR 宏/函数是一个执行错误检查的外部函数。
3.1.2 创建应用程序
创建应用程序的整个过程如图所示:3.1.3 静态SQL的特点
静态SQL编程比动态SQL编程简单些. 静态SQL语句嵌入宿主语言源文件中,预编译器将SQL语句转换为宿主语言编译器能够处理的数据库运行时服务API调用。因为在捆绑应用程序时,做捆绑的人需要有一定的授权,因此最终用户不需要执行程序包里的语句的直接权限。例如,一个应用程序可以只允许某个用户更新一个表的部分数据,而不用将更新整个表的权利给予这个用户。这个功能通过限制嵌入的静态SQL语句只能更新表中的某些列或者一定范围内的值,只将程序包的执行权限给予这个用户。
静态SQL语句是持久稳固的,动态SQL语句只是被缓存,直到变为无效、因为空间管理原因被清理或者数据库被关闭。如果需要,当被缓存的语句变为无效时,DB2 SQL编译器隐性地重新编译动态SQL语句。
静态SQL语句的主要优点是静态SQL在数据库关闭后仍然存在,而动态SQL语句在数据库关闭后就被清除了。另外,静态SQL在运行时不需要DB2 SQL编译器来编译,相反,动态SQL语句需要在运行时编译(例如,使用PREPARE语句)。因为DB2缓存动态SQL语句,这些语句也不总是需要DB2编译。但是,每一次运行程序至少需要编译一次。
静态SQL有性能上的优势。对简单、运行时间短的SQL程序,静态SQL语句 比相同目的的动态SQL语句执行得快。因为静态SQL语句准备执行形式的开销在预编译时间,而不是在运行时。
注意:静态SQL语句的性能决定于应用程序最后一次被捆绑时数据库的统计信息。 然而,如果这些统计信息改变了,那么比较起来,等效的动态SQL语句的性能可能好些。在某个使用静态SQL的应用程序捆绑之后,数据库增加了一个索引,如果这个应用程序不重新捆绑,就不能利用这个索引。还有,如果在静态SQL语句中使用宿主变量,优化器也不能使用表的分布信息来优化SQL语句。
3.2 宿主变量和指示符变量的应用
3.2.1 宿主变量的声明
宿主变量(Host variables) 在主应用程序中由嵌入式SQL语句引用的变量。宿主变量是该应用程序中的程序设计变量,并且是在数据库中的表与应用程序工作区之间传送数据的主要机制。我们称之为“宿主变量”,是为了与通常方法声明的源语言变量区分开来,通常方法声明的变量不能被SQL语句引用。宿主变量在宿主语言程序模块中以一种特殊的方式声明:必须在BEGIN DECLARE SECTION和END DECLARE SECTION程序节内定义。下图显示在不同编程语言中声明宿主变量的例子。
| 语言 | 例子源码 |
| C/C++ | EXEC SQL BEGIN DECLARE SECTION; short dept=38, age=26; double salary; char CH; char name1[9], NAME2[9]; /* C comment */ short nul_ind; EXEC SQL END DECLARE SECTION; |
| Java | // Note that Java host variable declarations follow // normal Java variable declaration rules, and have // no equivalent of a DECLARE SECTION short dept=38, age=26; double salary; char CH; String name1[9], NAME2[9]; /* Java comment */ short nul_ind; |
| COBOL | EXEC SQL BEGIN DECLARE SECTION END-EXEC. 01 age PIC S9(4) COMP-5 VALUE 26. 01 DEPT PIC S9(9) COMP-5 VALUE 38. 01 salary PIC S9(6)V9(3) COMP-3. 01 CH PIC X(1). 01 name1 PIC X(8). 01 NAME2 PIC X(8). * COBOL comment 01 nul-ind PIC S9(4) COMP-5. EXEC SQL END DECLARE SECTION END-EXEC. |
下面是引用宿主变量的例子
| 语言 | 例子源码 |
| C/C++ | EXEC SQL FETCH C1 INTO :cm; printf( "Commission = %f\n", cm ); |
| Java | #SQL { FETCH :c1 INTO :cm }; System.out.println("Commission = " + cm); |
| COBOL | EXEC SQL FETCH C1 INTO :cm END-EXEC DISPLAY 'Commission = ' cm |
在SQL语句中引用宿主变量时,必须加前缀—冒号(:)。冒号的作用是将宿主变量与SQL语法中的元素区分开。如果没有冒号,宿主变量会误解释为SQL语句的一部分。例如:
WORKDEPT = dept
将被解释为WORKDEPT列的值等于dept列的值。在宿主语言语句中,则不需要加前缀,正常引用即可。从下图中可看出如何使用宿主变量:
DB2名字空间(如表名、列名等等)不能用宿主变量指定。例如不能写如下SQL语句:
SELECT :col1 FROM:tabname
但是,这种类型的功能可以通过采用动态SQL实现。
总的来说,宿主变量有以下特点:
l 可选的,在语句运行之前用来赋值
l 宿主语言标号在SQL语句中,前面加冒号
l 宿主变量与列的数据类型必须匹配
l 对于宿主变量有以下要求:
a. 所有被嵌入SQL引用的宿主变量必须在BEGIN和END DECLARE语句界定的代码区里声明;
b. 宿主变量的数据类型必须与列的数据类型匹配,而且尽量避免数据转换和截取;
c. 宿主变量名不能以EXEC、SQL、sql开头;
d. 宿主变量应该被看作是模块程序的全局变量,而不是定义所在函数的局部变量;
e. 在界定区外定义的变量不能与界定区内定义的变量同名;
f. 在一个源文件中,可以有多个界定区;
g. BEGIN DECLARE SECTION语句可以在程序中宿主语言规则允许变量声明的任何位置出现,宿主变量定义区以ENDDECLARE SECTION语句结束;
h. BEGIN DECLARE SECTION和END DECLARE SECTION语句必须成对出现,并且不能嵌套;
i. 宿主变量声明可以使用SQL INCLUDE语句指定。另外,一个宿主变量声明区不能含有除宿主变量声明以外的语句。
3.2.2 宿主变量的使用
下面我们通过几个例子来说明宿主变量的用法:1.在INSERT语句中的使用
l SQL语句
INSERT INTO TEMPL (EMPNO,LASTNAME)
VALUES (‘000190’, ‘JONES’)
l 嵌入程序的SQL语句
EXEC SQL INSERT INTO TEMPL (EMPNO, LASTNAME)
VALUES (:empno,:name);
第一条SQL语句可以在CLP中发出,它也可以嵌入程序中,但是它每一次只能插入一行值,如果要插入不同的值就要重新输入,程序也要修改。
第二条SQL语句只能嵌入程序中,每一次执行需要用户通过其它代码指定新值给宿主变量empno和name,宿主变量的作用是将用户指定的值传递给VALUES子句。可以实现输入多行值(循环或多次运行程序)。
2.在SET和WHERE子句中的使用
l SQL语句
UPDATE TEMPL
SET SALARY = SALARY *1.05
WHERE JOBCODE = 54
l 嵌入程序的SQL语句
EXEC SQL
UPDATE TEMPL
SET SALARY = SALARY *:percent
WHERE JOBCODE = :code;
3. 用宿主变量提取值。在程序中执行一个SELECT语句时,必须提供一个存储区域来接收返回的数据,而且对于被选择(selected)的每一列,都要定义一个宿主变量。语法为:SELECT … INTO :hostvaribale …。例子:
EXEC SQL
SELECT LASTNAME, WORKDEPT
INTO :name, :deptno
FROM TEMPL
WHERE EMPNO = :empid;
例子中定义了三个宿主变量,从表TEMPL中选择符合条件—EMPNO=:empid—的两列:LASTNAME和WORKDEPT,结果存放到宿主变量name和deptno中。此形式的用法要保证只能返回单行数据,如果返回多行数据库,则不能使用这种方法。后面会介绍如果使用游标(cursor)处理多行的返回结果集。
从上面的例子可将宿主变量分为两类:
l 输入宿主变量
输入宿主变量规定需要在语句执行期间从应用程序传递给数据库管理器的值。例如,在下面的SQL语句中将使用一个输入宿主变量:
SELECT name FROM candidate
WHERE name = < input host variable >
l 输出宿主变量
输出宿主变量规定需要在语句执行期间从数据库管理器传递给应用程序的值。例如,在下面的SQL语句中将使用一个输出宿主变量:
SELECT INTO <output host variable > FROM candidate
WHERE name = ‘HUTCHISON ’
3.2.3 指示符变量的声明
在实际中,有些对象的值未知,我们用空值表示。当我们选择数据时,如果是空值,宿主变量的内容将不会被改变,是随机的。DB2数据库管理器提供了一个机制去通知用户返回数据是空值,这个机制就是指示符变量。指示符(indicator)变量是一种特殊的宿主变量类型,它用来表示列的空值或非空值。当这些宿主变量作为输入进入数据库中时,应当在执行SQL语句之前由应用程序对它们设置值。当这些宿主变量作为数据库的输出使用时,这些指示符由应用程序定义,但由DB2更新和将它们返回。然后,在结果被返回时,应用程序应当检查这些指示符变量的值。
看下面一条SQL语句:
SELECT COLA INTO:a:aind
其中a是宿主变量,aind是指示符变量。如果COLA列的值不为空,DB2将aind的值设置为非负(通常为0);如果COLA列的值为空,DB2将aind的值设置为负数(通常为-1);如果DB2试图提示一个空值的存在,但是程序没有提供指示符,将会产生错误,SQLCODE等于-305。
指示符变量的定义:
指示符变量的定义与宿主变量的定义方法相同,都需要在BEGIN DECLARE SECTION和END DECLARE SECTION之间定义,并且数据类型与SQL数据类型SMALLINT对应,在C语言中为SHORT类型。
例子:
| CREATE TABLE TEMPL ( EMPNO CHAR(6) NOT NULL, LASTNAME VARCHAR(2) NOT NULL, JOBCODE CHAR(2), WORKDEPT CHAR(3), NOT NULL, PHONENO CHAR(10)) EXEC SQL SELECT JOBCODE, WORKDEPT, PHONENO INTO :jc:jci, :dpt, :pho:phoi FROM TEMPL WHERE EMPNO = :id; |
| EMPNO(6) | LASTNAME(20) | JOBCODE 0-99 | WORKDEPT(3) | PHONENO(10) |
| 000070 000120 000320 | JOHNSON SCOTT MILLIGAN | 54 ? ? | C01 C01 C01 | 5137853210 8592743091 ? |
3.2.4 指示符变量的使用
| 指示符逻辑例子1: EXEC SQL SELECT PHONENO, SEX INTO :phoneno:phoneind, :sex FROM TEMPL WHERE EMPNO = :eno; if (phoneind < 0) null_phone(); else good_phone(); 在这个例子里,DB2维护指示符变量,应用程序在SQL语句执行后,询问指示符变量的值,调用相应的处理函数 |
| 指示符逻辑例子2: if (some condition) phoneind = -1; else phoneind = 0; EXEC SQL UPDATE TEMPL SET NEWPHONE = :newphoneno :phoneind WHERE EMPNO = :eno; 在这个例子里,应用程序维护指示符变量。应用程序根据条件设置指示符变量phoneind的值。如果DB2发现指示符的值为负数,那么给定行集合中的列被设置为空值,宿主变量的值被忽略;如果指示符的值为正数或者为零,宿主变量中的值被使用。 在嵌入SQL语句中可以使用关键字NULL。下面是不使用指示符变量的一个UPDATE语句例子: if ( some condition) EXEC SQL UPDATE TEMPL SET PHONENO = NULL WHERE EMPNO = :eno ; else EXEC SQL UPDATE TEMPL SEST PHONENO = :newphone WHERE EMPNO = :eno ; 但是,这种写法有缺点:如果UPDATE语句需要修改,就要修改两处代码。 |
如何设置指示符变量:
| 谁维护指示符变量 | SQL语句类型 | 宿主变量 :cd | 指示符变量 :cdi | 列 JOBCODE |
| DB2 | SELECT/ FETCH | 60 不改变 | 0 <0 | 60 NULL |
| 应用程序 | UPDATE/ INSERT | 50 N/A | 0 <0 | 50 NULL |
DB2在执行SELECT和FETCH语句的过程中设置指示符变量的值,应用程序应该在执行SELECT和FETCH语句后检查它们的值。
应用程序在执行UPDATE和INSERT语句之前设置指示符变量的值来指示DB2是否在数据库中放置一个空值(NULL)。
上表的第一行:在一条SELECT或者FETCH语句中,如果列(JOBCODE)中的值不为空,值被设置到宿主变量(:cd)中,指示符变量(:cdi)的值为零;如果列中的值为空,指示符变量的值将为负数,宿主变量的值不改变。
上表的第一行:在一条UPDATE或者INSERT语句中,如果指示符变量(:cdi)中的值不为负数,宿主变量(:cd)中的值被放到相应的列中;如果指示符变量中的值为负数,宿主变量中的值被忽略,相应的列被设置为空(NULL)。
指示符变量在数值转换方面的应用:
当宿主变量的数据类型与相应列的数据类型不兼容或者不能转换时,DB2也通过指示符变量通知应用程序。
数值转换由数据库管理器处理,能转换时自动完成,对程序透明;
如果列中的值不能存储到宿主变量中时(例如,列的数据类型为DECIMAL(15),值的长度为12个数字,不能存储到INTEGER类型的宿主变量中),指示符变量的值为-2。
指示符变量在截取方面的应用:
在SQL语句执行后,如果指示符变量的值为正数,说明发生了数据截取:
—如果是时间数据类型的秒部分被截取,那么指示符变量中的值为截取的秒数
—对于其他数据类型,指示符变量表示数据库中列的数据原始长度,通常为字节数(数据库尽可能返回更多的数据)。
例子:
定义宿主变量和指示符变量:
EXEC SQL BEGIN DECLARE SECTION;
char too_little[5];
short iv1;
EXEC SQL END DECLARE SECTION;
表BANK_ITEMS:
| ITEM# | QTY | DESCRIPTION |
| 101 | 3000 | PASSBOOKS |
| 200 | 100 | CHECKBOOKS |
| … | … | … |
执行的SQL语句:
SELECT DESCRIPTION INTO :too_little:iv
FROM BANK_ITEMS WHERE ITEM# = 200
结果:
:too_little中的值为’CHECK’,:iv1中的值为10
3.3 使用游标处理多行结果集
为了使应用程序能够提取多行结果集,SQL使用了一种机制,叫做游标(cursor)。为了理解游标的概念,我们假设数据库管理器创建了一个结果表(result table),里面包含有执行一条SELECT语句所提取的所有行。通过标识或指向这个表的“当前行”,游标使得结果表中的行对应用程序可用。当一个是拥游标时,应用程序可以顺序从结果表中提取每一行,直到产生一个数据结束条件,这个条件就是NOT FOUND条件,SQLCA中的SQLCODE为+100(SQLSTATE为02000)。执行SELECT语句的结果集,可能有零行、一行或者更多行,决定于有多少行符合搜索的条件。
处理一个游标涉及到以下几个步骤:
1.使用DECLARE CURSOR语句声明一个游标
2.使用OPEN语句执行查询和创建结果表
3.使用FETCH语句每次提取一行结果
4.使用DELETE或UPDATE语句处理行(如果需要)
5.使用CLOSE语句终止(关闭)游标
一个应用程序中,可以使用多个游标,但是每一个游标要有自己的DECLARE CURSOR,OPEN,CLOSE和FETCH语句集。
3.3.1声明和使用游标
DECLARE CURSOR语句定义和命名游标,确定使用SELECT语句要提取的行结果集。应用程序给游标分配一个名字。这个名字在随后的OPEN、FETCH和CLOSE语句中都要被参考到。查询可以是任何有效的SELECT语句。
下面例子展示了一条DECLARE语句如何与一条静态SELECT语句关联起来:
| 语言 | 源码例程 |
| C/C++ | EXEC SQL DECLARE C1 CURSOR FOR SELECT PNAME, DEPT FROM STAFF WHERE JOB=:host_var; |
| Java (SQLJ) | #sql iterator cursor1(host_var data type); #sql cursor1 = { SELECT PNAME, DEPT FROM STAFF WHERE JOB=:host_var }; |
| COBOL | EXEC SQL DECLARE C1 CURSOR FOR SELECT NAME, DEPT FROM STAFF WHERE JOB=:host-var END-EXEC. |
| FORTRAN | EXEC SQL DECLARE C1 CURSOR FOR + SELECT NAME, DEPT FROM STAFF + WHERE JOB=:host_var |
3.3.2游标与工作单元的考虑
COMMIT或者ROLLBACK操作的动作随游标的不同而不同,依赖于游标的定义。1.只读游标(Read Only Cursors)
如果一个游标被确定为只读的,并且使用可重复读隔离级(isolationlevel),那么系统表仍会收集和维护工作单元需要的可重复读锁。因此,即使只读游标,应用程序周期性地发出COMMIT语句还是很重要的。
2.有WITH HOLD选项
如果应用程序通过发出一条COMMIT语句来完成一个工作单元,除了声明时有WITH HOLD选项的游标,所有游标将自动地被数据库管理器关闭。
用WITH HOLD声明的游标维护它访问的跨多个工作单元的资源。用WITH HOLD声明的游标受到的影响依赖于工作单元如何结束。
如果工作单元使用一条COMMIT语句结束,已打开的定义为WITHHOLD的游标将保持打开状态。游标的位置在结果集的下一个逻辑行之前。另外,参考用WITH HOLD定义的已准备好的语句也会被保留。紧跟COMMIT语句后面, 只有与一个某个特定游标相关联的FETCH和CLOSE请求才有效。UPDATE WHERE CURRENT OF和DELETE WHERE CURRENT OF 语句仅仅对在同一个工作单元中提取的行有效。如果程序包在工作单元期间被重新绑定,那么所有保持的游标都会被关闭。
如果工作单元使用一条ROLLBACK语句结束,所有打开的游标被关闭,所有在工作单元中获得的锁被释放,以及所有依赖于这个工作单元的已准备好的语句被删除。
举个例子,假设TEMPL表中有1000条记录。要更新所有雇员的工资,应该每更新100行就要发出一条COMMIT语句。
A. 使用WITH HOLD选项声明游标:
EXEC SQL DECLARE EMPLUPDT CURSOR WITH HOLD FOR
SELECT EMPNO, LASTNAME,PHONENO, JOBCODE, SALARY
FROM TEMPL FOR UPDATE OF SALARY
B. 打开游标,每一次从结果表中提取一行数据:
EXEC SQL OPEN EMPLUPDT
.
.
.
EXEC SQL FETCH EMPLUPDT
INTO :upd_emp, :upd_lname, :upd_tele, :upd_jobcd, :upd_wage,
C. 当想要更新或者删除一行时,使用带WHERE CURRENT OF选项的UPDATE或者DELETE语句。例如,要更新当前行,程序可以发出下面的语句:
EXEC SQL UPDATE TEMPL SET SALARY =:newsalary
WHERE CURRENT OF EMPLUPDT
在一条COMMIT语句发出之后,在更新其它行之前必须发出FETCH语句。
如果应用程序使用了用WITH HOLD声明的游标或者执行了多个工作单元并且有一个用WITH HOLD声明的游标跨工作单元处于打开状态,那么在程序中应该加入代码检测和处理SQLCODE为-501(SQLSTATE为24501)的错误,这个错误由FETCH或者CLOSE语句返回。
如果应用程序的程序包由于其依赖的表被删除而变得无效,程序包会自动被重新绑定。这种情况下,FETCH或CLOSE语句返回SQLCODE –501(SQLSTATE 24501),因为 数据库管理器关闭游标。在此情形下,处理SQLCODE –501(SQLSTATE 24501)的方法决定于是否要从游标提取行数据。
l 如果要从游标提取行,打开游标,然后运行FETCH语句。注意,OPEN语句使得游标重定位到开始处。原来的位置信息丢失。
l 如果不准备从游标提取行,那么不要对游标发出任何SQL请求。
WITH RELEASE 选项:当应用程序用WITH RELEASE选项关闭一个游标时,DB2试图去释放游标持有的所有读锁(READ locks)。游标只继续持有写锁(WRITE locks)。如果应用程序没有用RELEASE选项关闭游标,那么在工作单元完成时,所有的读锁和写锁都被释放。
3.3.3例程
游标程序C Example: CURSOR.SQC
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "util.h"
#ifdef DB268K
/* Need to include ASLM for 68K applications */
#include <LibraryManager.h>
#endif
EXEC SQL INCLUDE SQLCA;
#define CHECKERR(CE_STR) if (check_error (CE_STR, &sqlca) != 0) return 1;
int main(int argc, char *argv[]) {
EXEC SQL BEGIN DECLARE SECTION;
char pname[10];
short dept;
char userid[9];
char passwd[19];
EXEC SQL END DECLARE SECTION;
#ifdef DB268K
/* Before making any API calls for 68K environment,
need to initial the Library Manager */
InitLibraryManager(0,kCurrentZone,kNormalMemory);
atexit(CleanupLibraryManager);
#endif
printf( "Sample C program: CURSOR \n" );
if (argc == 1) {
EXEC SQL CONNECT TO sample;
CHECKERR ("CONNECT TO SAMPLE");
}
else if (argc == 3) {
strcpy (userid, argv[1]);
strcpy (passwd, argv[2]);
EXEC SQL CONNECT TO sample USER :userid USING :passwd;
CHECKERR ("CONNECT TO SAMPLE");
}
else {
printf ("\nUSAGE: cursor [userid passwd]\n\n");
return 1;
} /* endif */
EXEC SQL DECLARE c1 CURSOR FOR (1)
SELECT name, dept FROM staff WHERE job='Mgr'
FOR UPDATE OF job;
EXEC SQL OPEN c1; (2)
CHECKERR ("OPEN CURSOR");
do {
EXEC SQL FETCH c1 INTO :pname, :dept; (3)
if (SQLCODE != 0) break;
printf( "%-10.10s in dept. %2d will be demoted to Clerk\n",
pname, dept );
} while ( 1 );
EXEC SQL CLOSE c1; (4)
CHECKERR ("CLOSE CURSOR");
EXEC SQL ROLLBACK;
CHECKERR ("ROLLBACK");
printf( "\nOn second thought -- changes rolled back.\n" );
EXEC SQL CONNECT RESET;
CHECKERR ("CONNECT RESET");
return 0;
}
/* end of program : CURSOR.SQC */Java Example: Cursor.sqlj
import java.sql.*;
import sqlj.runtime.*;
import sqlj.runtime.ref.*;
#sql iterator CursorByName(String name, short dept) ;
#sql iterator CursorByPos(String, short ) ;
class Cursor
{ static
{ try
{ Class.forName ("COM.ibm.db2.jdbc.app.DB2Driver").newInstance ();
}
catch (Exception e)
{ System.out.println ("\n Error loading DB2 Driver...\n");
System.out.println (e);
System.exit(1);
}
}
public static void main(String argv[])
{ try
{ System.out.println (" Java Cursor Sample");
String url = "jdbc:db2:sample";
// URL is jdbc:db2:dbname
Connection con = null;
// Set the connection
if (argv.length == 0)
{ // connect with default id/password
con = DriverManager.getConnection(url);
}
else if (argv.length == 2)
{ String userid = argv[0];
String passwd = argv[1];
// connect with user-provided username and password
con = DriverManager.getConnection(url, userid, passwd);
}
else
{ throw new Exception("Usage: java Cursor [username password]");
}
// Set the default context
DefaultContext ctx = new DefaultContext(con);
DefaultContext.setDefaultContext(ctx);
// Enable transactions
con.setAutoCommit(false);
// Using cursors
try
{ CursorByName cursorByName;
CursorByPos cursorByPos;
String name = null;
short dept=0;
// Using the JDBC ResultSet cursor method
System.out.println("\nUsing the JDBC ResultSet cursor method");
System.out.println(" with a 'bind by name' cursor ...\n");
#sql cursorByName = {
SELECT name, dept FROM staff
WHERE job='Mgr' FOR UPDATE OF job }; (1)
while (cursorByName.next()) (2)
{ name = cursorByName.name(); (3)
dept = cursorByName.dept();
System.out.print (" name= " + name);
System.out.print (" dept= " + dept);
System.out.print ("\n");
}
cursorByName.close(); (4)
// Using the SQLJ iterator cursor method
System.out.println("\nUsing the SQLJ iterator cursor method");
System.out.println(" with a 'bind by position' cursor ...\n");
#sql cursorByPos = {
SELECT name, dept FROM staff
WHERE job='Mgr' FOR UPDATE OF job }; (1) (2)
while (true)
{ #sql { FETCH :cursorByPos INTO :name, :dept }; (3)
if (cursorByPos.endFetch()) break;
System.out.print (" name= " + name);
System.out.print (" dept= " + dept);
System.out.print ("\n");
}
cursorByPos.close(); (4)
}
catch( Exception e )
{ throw e;
}
finally
{ // Rollback the transaction
System.out.println("\nRollback the transaction...");
#sql { ROLLBACK };
System.out.println("Rollback done.");
}
}
catch( Exception e )
{ System.out.println (e);
}
}
}游标程序如果工作:
1.声明游标。DECLARE CURSOR语句将游标c1与一个查询关联起来。查询确定应用程序使用FETCH语句提取的行。表staff的job字段被定义为可更新的,即使它在结果表中。
2.打开游标。游标c1被打开,数据库管理器执行查询并创建结果表。游标的指向位于第一行的前面。
3.提取一行。FETCH语句使游标指向下一行,将那行的内容移动到宿主变量中。那行成为当前行。
4.关闭游标。发出CLOSE语句,释放与游标相关联的资源。游标仍然可以再次打开。
3.3.4更新和删除提取的数据
可以更新和删除一个游标指向的行。要使行能被更新,对应于游标的查询不能是只读的。更新提取的数据
为了利用游标来更新数据,在UPDATE语句中使用WHERECURRENT OF子句。使用FORUPDATE子句告诉系统结果表中的哪些列要更新。也可以在FOR UPDATE中指出不在选择范围之内的列,从另一个角度讲,可以更新不被游标提取的列。如果FOR UPDATE子句中没有指定任何列名,那么在第一个FROM子句中标识的表或者视图的所有列都被看作是可更新的。性能上要求只在FOR UPDATE子句里指定要更新的列,如果指定不需要更新的列,DB2将浪费没有必要的开销去访问数据。
删除提取的数据
为了利用游标来删除数据,在DELETE语句中使用WHERECURRENT OF条款。通常上,为了删除游标的当前行,定义游标时,不需要FOR UPDATE条款。一个例外情况是,在应用程序中使用动态的SELECT语句或者DELETE语句,预编译时LANGLEVEL选项设为SAA1,捆绑时使用BLOCKING ALL选项。这种情况下,SELECT语句需要FOR UPDATE条款。(详细信息请看3.3节开发动态SQL应用程序)
DELETE语句使得游标指示的那行被删除。游标的位置指向下一行的前面。要进行下一个WHERE CURRENT OF操作之前,必须对游标发出一条FETCH语句。
游标的类型
游标可以分为三类:
1.只读类型
游标指向的行只能够读,不能够更新。应用程序只是读取数据不修改时,使用只读游标。如果游标是基于只读SELECT语句,那么它便是只读的。只读游标在性能方面较好。
2.可更新类型
游标指向的行可以更新。应用程序需要修改提取的数据时,使用可更新游标。指定的查询只能涉及到一个表或视图。查询必须包含FOT UPDATE子句,并写出每一个要更新的列(除非预编译时使用LANGLEVEL MIA选项)。
3.不明确类型
从游标的定义或者上下文来确定游标是可更新的还是只读的。
当预编译或绑定时使用BLOCKING ALL选项,不明确的游标被看作是只读的。否则,被看作是可更新的。
注意:动态处理的游标通常是不明确类型的。
例子 OPENFTCH程序
这个例子使用一个游标从一个表中选择行,打开游标,从表中提取行。对提取的每一行,判断是否要删除或者更新(根据一个简单的条件)。这个例子有以下语言的版本:
C语言:openftch.sqc
Java语言:Openftch.sqlj and OpF_Curs.sqlj
COBOL语言:openftch.sqb
FORTRAN 语言:openftch.sqf
C Example: OPENFTCH.SQC
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "util.h"
#ifdef DB268K
/* Need to include ASLM for 68K applications */
#include <LibraryManager.h>
#endif
EXEC SQL INCLUDE SQLCA;
#define CHECKERR(CE_STR) if (check_error (CE_STR, &sqlca) != 0) return 1;
int main(int argc, char *argv[]) {
EXEC SQL BEGIN DECLARE SECTION;
char pname[10];
short dept;
char userid[9];
char passwd[19];
EXEC SQL END DECLARE SECTION;
#ifdef DB268K
/* Before making any API calls for 68K environment,
need to initial the Library Manager */
InitLibraryManager(0,kCurrentZone,kNormalMemory);
atexit(CleanupLibraryManager);
#endif
printf( "Sample C program: OPENFTCH\n" );
if (argc == 1) {
EXEC SQL CONNECT TO sample;
CHECKERR ("CONNECT TO SAMPLE");
}
else if (argc == 3) {
strcpy (userid, argv[1]);
strcpy (passwd, argv[2]);
EXEC SQL CONNECT TO sample USER :userid USING :passwd;
CHECKERR ("CONNECT TO SAMPLE");
}
else {
printf ("\nUSAGE: openftch [userid passwd]\n\n");
return 1;
} /* endif */
EXEC SQL DECLARE c1 CURSOR FOR (1)
SELECT name, dept FROM staff WHERE job='Mgr'
FOR UPDATE OF job;
EXEC SQL OPEN c1; (2)
CHECKERR ("OPEN CURSOR");
do {
EXEC SQL FETCH c1 INTO :pname, :dept; (3)
if (SQLCODE != 0) break;
if (dept > 40) {
printf( "%-10.10s in dept. %2d will be demoted to Clerk\n",
pname, dept );
EXEC SQL UPDATE staff SET job = 'Clerk' (4)
WHERE CURRENT OF c1;
CHECKERR ("UPDATE STAFF");
} else {
printf ("%-10.10s in dept. %2d will be DELETED!\n",
pname, dept);
EXEC SQL DELETE FROM staff WHERE CURRENT OF c1;
CHECKERR ("DELETE");
} /* endif */
} while ( 1 );
EXEC SQL CLOSE c1; (5)
CHECKERR ("CLOSE CURSOR");
EXEC SQL ROLLBACK;
CHECKERR ("ROLLBACK");
printf( "\nOn second thought -- changes rolled back.\n" );
EXEC SQL CONNECT RESET;
CHECKERR ("CONNECT RESET");
return 0;
}
/* end of program : OPENFTCH.SQC */Java Example: Openftch.sqlj
OpF_Curs.sqlj
// PURPOSE : This file, named OpF_Curs.sqlj, contains the definition // of the class OpF_Curs used in the sample program Openftch. import sqlj.runtime.ForUpdate; #sql public iterator OpF_Curs implements ForUpdate (String, short);
Openftch.sqlj
import java.sql.*;
import sqlj.runtime.*;
import sqlj.runtime.ref.*;
class Openftch
{ static
{ try
{ Class.forName ("COM.ibm.db2.jdbc.app.DB2Driver").newInstance ();
}
catch (Exception e)
{ System.out.println ("\n Error loading DB2 Driver...\n");
System.out.println (e);
System.exit(1);
}
}
public static void main(String argv[])
{ try
{ System.out.println (" Java Openftch Sample");
String url = "jdbc:db2:sample"; // URL is jdbc:db2:dbname
Connection con = null;
// Set the connection
if (argv.length == 0)
{ // connect with default id/password
con = DriverManager.getConnection(url);
}
else if (argv.length == 2)
{ String userid = argv[0];
String passwd = argv[1];
// connect with user-provided username and password
con = DriverManager.getConnection(url, userid, passwd);
}
else
{ throw new Exception(
"\nUsage: java Openftch [username password]\n");
} // if - else if - else
// Set the default context
DefaultContext ctx = new DefaultContext(con);
DefaultContext.setDefaultContext(ctx);
// Enable transactions
con.setAutoCommit(false);
// Executing SQLJ positioned update/delete statements.
try
{ OpF_Curs forUpdateCursor;
String name = null;
short dept=0;
#sql forUpdateCursor =
{ SELECT name, dept
FROM staff
WHERE job='Mgr'
FOR UPDATE OF job
}; // #sql (1)(2)
while (true)
{ #sql
{ FETCH :forUpdateCursor
INTO :name, :dept
}; // #sql (3)
if (forUpdateCursor.endFetch()) break;
if (dept > 40)
{ System.out.println (
name + " in dept. "
+ dept + " will be demoted to Clerk");
#sql
{ UPDATE staff SET job = 'Clerk'
WHERE CURRENT OF :forUpdateCursor
}; // #sql (4)
}
else
{ System.out.println (
name + " in dept. " + dept
+ " will be DELETED!");
#sql
{ DELETE FROM staff
WHERE CURRENT OF :forUpdateCursor
}; // #sql
} // if - else
}
forUpdateCursor.close(); (5)
}
catch( Exception e )
{ throw e; }
finally
{ // Rollback the transaction
System.out.println("\nRollback the transaction...");
#sql { ROLLBACK };
System.out.println("Rollback done.");
} // try - catch - finally
}
catch( Exception e )
{ System.out.println (e); } // try - catch
} // main
} // class OpenftchOPENFTCH程序是如何工作的:
1.声明游标。DECLARE CURSOR语句将游标c1与一个查询关联起来。查询确定应用程序使用FETCH语句提取的行。表staff的job字段被定义为可更新的,即使它不在结果表中。
2.打开游标。游标c1被打开,导致数据库管理器执行查询并创建一个结果表。游标的位置位于第一行的前面。
3.提取一行。FETCH语句将游标指向下一行,并将行的内容移到宿主变量中。那行成为当前行。
4.更新或删除当前行。当前行被更新或者被删除,决定于FETCH语句返回dept的值。
如果一个UPDATE语句被执行,游标的位置保持不变,因为UPDATE语句不改变当前行的位置。
如果一个DELETE语句被执行,游标的位置位于下一行的前面,因为当前行已被删除。在进行另外的WHERE CURRENT OF操作之前,必须执行一条FETCH语句。
5.关闭游标。CLOSE语句被发出,释放与游标关联的资源。游标可以被再次打开。
3.4 诊断信息处理与SQLCA结构
3.4.1 SQLCA结构
SQLCA的全称为SQL通信区(Communication Area),是应用程序用来接收数据库管理返回的SQL执行情况信息的数据结构。下面是SQLCA的C语言定义:
SQL_STRUCTURE sqlca
{
_SQLOLDCHAR sqlcaid[8]; /*Eyecatcher = 'SQLCA ' */
sqlint32 sqlcabc; /* SQLCA size in bytes = 136 */
sqlint32 sqlcode; /* SQLreturn code */
short sqlerrml; /* Lengthfor SQLERRMC */
_SQLOLDCHAR sqlerrmc[70]; /* Errormessage tokens */
_SQLOLDCHAR sqlerrp[8]; /*Diagnostic information */
sqlint32 sqlerrd[6]; /*Diagnostic information */
_SQLOLDCHAR sqlwarn[11]; /* Warningflags */
_SQLOLDCHAR sqlstate[5]; /* Statecorresponding to SQLCODE */
};
下表是SQLCA数据结构的详细描述:
| 元素名 | | |
| sqlcaid | CHAR(8) | 有助于从外观上识别该数据的视觉—捕捉器。它应当包含字符串‘SQLCA’ |
| sqlcabc | INTEGER | 包含SQLCA的长度。它应当总是包含值136 |
| sqlcode | INTEGER | 这可能是SQLCA结构的最重要元素。如果SQL被成功地处理,这个值包含错误代码或者是零值。如果该值是正数,那么返回警告信息并且处理SQL语句。如果该值是负数,那么有错误信息发生并且不处理SQL语句。如果该值是零(0),那么没有出现错误和警告信息并且处理了SQL语句 |
| sqlerrml | SMAIIINT | 包含在元素sqlerrmc中字符串的长度 |
| sqlerrmc | VARCHAR(70) | 包含用X’FF’间隔的一个到多个信息标志。这些信息标志提供了所发生错误/警告的更多情况。间隔符用来传递多个参数/标志 |
| sqlerrp | CHAR(8) | 通常,这个元素包含产品的签名。这个产品签名是一个代表目前正在被使用的DB2数据库服务器的类型。例如SQL02010说明当前的服务器是DB2通用服务器2.1.0版本。其它的DB2数据库服务器是: DSN —DB2 for MVS SQS —DB2 for OS/400 ARI — DB2 for VM/VSE(SQL/DS) 格式是pppvvrrm,其中: ppp — product(产品) vv — version (版本号) rr — release (颁布号) m — modification level (修改级别) |
| sqlerrd | INTEGER ARRAY | 当发现错误条件时,这6个整数值的数组能够包含附加的诊断信息 SQLERRD(1) — 内部返回码 SQLERRD(2) — 内部返回码 复合的SQL —失败号 SQLERRD(3) PREPARE — 返回的行数(估计) UPDATE/DELETE/INSERT — 受影响的行数 复合的SQL — 所有行的总和 CONNECT — 1,如果数据库可更新;2,如果数据库不可更新 SQLERRD(4) PREPARE — 开销评估 复合的SQL — 成功的子语句数 CONNECT 0 — 由底层客户机的一阶段委托确认 0 — 一阶段委托确认 0 — 一阶段只读委托确认 0 — 二阶段委托确认 SQLERRD(5) DELETE/INSERT/UPDATE—行数(根据限制条件) 复合的SQL—行数(根据限制条件) SQLERRD(6)—保留(未使用) |
| sqlwarn | CHARACTER ARRAY | 对应于各种警告条件的指示符的集合 SQLWARN0 — 全局指示符,’’,若无警告;’W’,否则 SQLWARN1 — ‘W’,字符串被截断地复制到宿主变量 SQLWARN2 — ‘W’, null value(s) eliminated from evaluation of a column function SQLWARN3 — ‘W’, 列的个数大于宿主变量的个数 SQLWARN4 — ‘W’, UPDATE/DELETE语句不包含’WHERE’子句 SQLWARN5 — 保留 SQLWARN6 — date or timestamp value adjusted to correct an invalid data resulting from arithmetic operation SQLWARN7 — 保留 SQLWARN8 — 字符结果不能被转换,而被子串替换 SQLWARN9 — 在列函数的处理过程中,忽略了有错误的算术表达式 SQLWARNA —在转换SQLCA中的一个字符数据值时发生转换错误 |
| sqlstate | CHAR(5) | 交叉平台错误代码。sqlstate的值对应于sqlcode。某些sqlcodes没有对应的sqlstate,因为对于指定的错误条件没有等价的sqlstate |
[注解]:在DB2 REXX环境中自动地提供SQLCA
开发者的应用程序必须在发出任何SQL语句之前声明SQLCA(SQL 通信区)。有以下两种在程序中定义SQLCA的方法:
l 使用EXEC SQL INCLUDE SQLCA。
l 在DB2的头文件中声明一个叫做sqlca的结构。
在表中给出的SQLCA数据结构可以作为在应用程序与DB2之间处理错误的主要手段。关键的是开发者的应用程序要在执行每条SQL语句之后核查SQLCA的内容。不能核查SQLCA的内容可能会引起无法预料的错误发生。对于可能发生的许多错误,通常系统会向用户建议相应的措施(它们可以被编码到用户的应用程序中)。例如,假设开发者试图与数据库服务器相连接并且收到一个错误信息,说尚未启动数据库管理器。应用程序可以发出DB2START命令去启动数据库管理器,然后再次试图与数据库服务器相连接。
3.4.2 WHENEVER语句
由于错误或警告的发生是不可预料的,所以我们无法象普通编程那样用条件或者循环等控制结构来实现错误处理,于是DB2提供了WHENEVER语句.WHENEVER这一控制结构使预编译器产生的执行代码,使应用程序在遇到错误、警告或"没有行发现"时转到指定的代码段,继续执行相应的处理程序. WHENEVER对同一源程序中所有另一同类WHENEVER前的SQL执行语句均有效.
WHENEVER有三种基本形式:
1. EXEC SQL WHENEVER SQLERROR action
2. EXEC SQL WHENEVER SQLWARNING action
3. EXEC SQL WHENEVER NOT FOUND action
在这些形式中,SQLERROR指的是SQLCODE<0的情况;SQLWARNING指的是SQLWARN0 = ‘w’或者SQLCODE>0;NOT FOUND指的则是SQLCODE=+100的情况.
action可以是以下两种情况之一:
CONTINUE: 表示忽略这个异常,继续应用程序的下一步执行;
Go To label: 表示发生异常时,转到label所标识的语句开始.
例子:
… SQL statement … EXEC SQL WHENEVER SQLERROR GO TO :A; … SQL statement IF SQLCODE <0 ―>A … SQL statement IF SQLCODE <0 ―>A … EXEC SQL WHENEVER SQLWARNING GO TO :W; EXEC SQL WHENEVER SQLERROR GO TO :B; … SQL statement IF SQLCODE < 0 ―>B IF warning ―>w … EXEC SQL WHENEVER SQLERROR CONTINUE; SQL statement IF warning ―>W …
3.4.3 查询错误
无论何时在任何示例中输入出错时,或者如果执行 SQL 语句期间出错,则数据库 管理程序返回错误信息。错误信息由信息标识符、简要说明以及SQLSTATE 组 成。SQLSTATE 是 DB2 系列产品的公共错误码。 SQLSTATE 符合 ISO/ANSI SQL92 标准。
例如,如果 CONNECT 语句中用户名或口令不正确,则数据库管理程序将返回信息标识符 SQL1403N 和 SQLSTATE 为 08004。该信息如下:
SQL1403N 提供的用户名和/或口令不正确。 SQLSTATE=08004
可以通过输入一个问号(?),然后输入信息标识符或SQLSTATE 来 获取关于错误信息的更多信息:
? SQL1403N
或
? SQL1403
或
? 08004
注意:错误 SQL1403N 的说明中倒数第二行表明 SQLCODE为-1403。 SQLCODE 为产品特定错误码。 以 N(通知)或 C(严重)结尾的信息标识符表示一个错误,并且具有负 SQLCODE。 以 W(警告)结尾的信息标识符表示一个警告,并且具有正 SQLCODE。
3.5 复合SQL语句
3.5.1 复合SQL的定义
构建在客户/服务器体系结构上的数据库应用程序,每执行一条SQL语句就要与数据库管理器交互一次。为了减少客户与服务器之间的交互信息及次数、提高整体系统的性能,DB2在程序开发方法上提供了一种机制―复合SQL(CompoundSQL)语句。复合 SQL 允许您将几条 SQL 语句分组为单个的可执行块。包含于块中的 SQL 语句(子语句)可以单独执行;但是,通过创建和执行一个语句块,您可以减少数据库管理程序的额外开销。对于远程客户机,复合 SQL 也减少必须通过网络传送的请求的数目。
有两种类型的复合 SQL:
l 基本 (ATOMIC)
当所有子语句都成功完成时,或当一个子语句因出错而结束时,应用程序将从数据库管理程序收到一个响应。如果一个子语句因出错而结束,则将整个块视为因出错而结束,并且将回滚在此块中对数据库所做的任何更改。
l 非基本(NOT ATOMIC)
当所有子语句都完成时,应用程序将从数据库管理程序接收到一个响应。不管其前面的子语句是否成功执行,一个块中的所有子语句都要执行。仅当回滚包含非基本复合 SQL 的工作单元时,才可以回滚此语句组。
3.5.2 复合SQL的例子
我们通过一个例子来说明如何编写复合SQL语句:EXEC SQL BEGIN COMPOUND ATOMIC STATIC UPDATE SAVINGS SET BALANCE = BALANCE - :transfer WHERE ATMCARD = :atmcard; UPDATE CHECKING SET BALANCE = BALANCE + :transfer WHERE ATMCARD = :atmcard; INSERT INTO ATMTRANS (TTSTMP, CODE, AMOUNT) VALUES (CURRENT TIMESTAMP, :code, :transfer); COMMIT; END COMPOUND;
1. 这个例子演示了复合SQL语句的一个简单使用:将钱从银行存款帐号转到支票帐号,并将转帐记录在审计表中;
2. 关键字ATOMIC 指明:在其中的所有SQL语句都成功执行,复合SQL语句才算成功,也就是可以提交(COMMIT);如果其中有一条SQL语句失败,那么复合SQL语句中所有SQL语句对数据库所作的改变都被回滚(Roll Back);
3. 可以用关键字NOT ATOMIC替换ATOMIC。这样会忽略任何子语句的失败,数据库管理器不会回滚复合SQL语句中其他语句所作的改变。SQLCA中的信息指出有多少条语句处理成功和检测到的错误信息;
4. 关键字STATIC表示在复合SQL语句中引用的宿主变量在复合SQL语句被调用时获得的值,不会被复合SQL语句中的任何SQL语句改变。例如:
EXEC SQL BEGIN COMPOUND ATOMIC STATIC UPDATE SAVINGS SET BALANCE = BALANCE - :transfer WHERE ATMCARD = :atmcard; SELECT ACCOUNT INTO :atmcard WHERE CARDHOLDER = ‘Cartwright’; UPDATE CHECKING SET BALANCE = BALANCE + :transfer WHERE ATMCARD = :atmcard; INSERT INTO ATMTRANS (TTSTMP, CODE, AMOUNT) VALUES (CURRENT TIMESTAMP, :code, :transfer); COMMIT; END COMPOUND;
在每一条UPDATE和INSERT语句中使用:atmcard在复合SQL运行之前获得的值,而不是对应于‘Cartwright‘的值。
5. 语句:STOP AFTER FIRST host_var STATEMENTS可以加在BEGIN COMPOUND语句中,允许程序指定复合SQL语句执行时,只执行其中的多少条。例如:
EXEC SQL BEGIN COMPOUND NOT ATOMIC STATIC STOP AFTER FIRST :nbr STATEMENTS INSERT INTO TAB1 VALUES(:col1val1, :col2val1); INSERT INTO TAB1 VALUES(:col1val2, :col2val2); INSERT INTO TAB1 VALUES(:col1val3, :col2val3); INSERT INTO TAB1 VALUES(:col1val4, :col2val4); INSERT INTO TAB1 VALUES(:col1val5, :col2val5); INSERT INTO TAB1 VALUES(:col1val6, :col2val6); INSERT INTO TAB1 VALUES(:col1val7, :col2val7); INSERT INTO TAB1 VALUES(:col1val8, :col2val8); END COMPOUND;
将宿主变量:nbr的值设置为希望一次插入的行数。
6. 如果复合SQL语句中包含COMMIT语句,必须放在最后一条语句的位置,即在END COMPOUND之前。即使使用STOP AFTER FIRST host_varSTATEMENTS选项,并且host_var的值小于复合SQL语句中的SQL语句条数,COMMIT语句也会被执行。注意:当连接类型(CONNECT TYPE)为2时,不允许有COMMIT语句。
7. SQLSTATE和SQLCODE的值是复合SQL语句中的最后执行的语句的信息。
3.5.3复合SQL的限制
使用复合SQL语句的限制:1. DB2 Connect只支持NOT ATOMIC类型的复合SQL语句
2. 复合SQL语句只能包含静态SQL语句
3. 复合SQL语句只能在嵌入SQL语句程序中使用
4. 下列语句不能包含在复合SQL语句中:
CALL CLOSE CONNECT Compound SQL DESCRIBE DISCONNECT EXECUTE IMMEDIATE FETCH OPEN PREPARE RELEASE ROLLBACK SET CONNECTION

相关文章推荐
- DB2 9 运用开发(733 测验)认证指南,第 4 部分: 嵌入式 SQL 编程(6)
- Windows Mobile6 Vs2008 Sql Ce3.5 嵌入式应用开发(转)
- Windows Mobile6 Vs2008 Sql Ce3.5 嵌入式应用开发
- DB2数据库、事务控制语言、系统控制语言、函数、嵌入式SQL(SQLJ)
- Windows Mobile6 Vs2008 Sql Ce3.5 嵌入式应用开发
- Linux嵌入式实时操作系统开发与设计(九)
- 没有硬件条件下来进行嵌入式系统的开发
- Linux嵌入式实时操作系统开发与设计(十)
- 嵌入式开发要跨平台
- 10004.自己动手打造嵌入式Linux软硬件开发环境
- Linux嵌入式实时操作系统开发与设计(五)
- 00017.嵌入式LINUX开发资源大全
- Linux嵌入式实时操作系统开发与设计(十一)
- 自己动手打造嵌入式Linux软硬件开发环境
- 利用RTLinux开发嵌入式应用程序
- Linux嵌入式实时操作系统开发与设计(三)
- Linux嵌入式实时操作系统开发与设计(七)
- 嵌入式领域开放源码开发工具Eclipse受欢迎
- Linux嵌入式实时操作系统开发与设计(四)
- Delphi数据库开发之SQL写法的技巧1