float类型数据在计算机中的表示方法以及转换方法
2015-03-11 11:40
786 查看
一、float类型数据在计算机中的表示方法
A.
下面的代码为什么第一行返回false,而第二行和第三行都返回true。
Console.WriteLine("1.123f + 1.345f == 2.468f ? {0}",
1.123f + 1.345f == 2.468f); // False
Console.WriteLine("1.123f + 1.344f == 2.467f ? {0}",
1.123f + 1.344f == 2.467f); // True
Console.WriteLine("1.123 + 1.345 == 2.468 ? {0}",
1.123 + 1.345 == 2.468); // True
我们知道,integer类型占用的是4个字节,可以表示的数字范围在2**-32到2**32之间.而且每一个整数在计算机里面都有相应的内存表示方法,例如数字12345的表示方法就是:
00000000 00000000 00110000 00111001
即根据二进制到十进制的转换方法: 12345 = 213 + 212 + 25 + 24 +
23 + 20
而在计算机float型,这种表示方法最大的问题就是如何在二进制里面保存小数点的位置--因为小数点的位置不固定.于是计算机专家们就想到了用科学计数法的方式来表示浮点数,因为在科学计数法里面,小数点的位置总是固定,就是在第一个数字的后面,例如12345的科学计数法的表示为: 1.2345
* 105。而0.012345的科学计数法表示方式为: 1.2345 * 10-2.
使用公式来表示的话,科学计数法的公式是 。
因为我们的计算机比较笨,只能处理0和1,所以在计算机里面表示浮点数的时候,上面的公式中的基数b是2,而不是10.在计算机内存当中,保存的实际是浮点数的计算公式,而不是确切的值,所以说计算机里面浮点数都是近似值,而不是确切的值.在计算机中,以float类型为例,内存中32个位所代表的内容分别是:
SEEEEEEE EMMMMMMM MMMMMMMM MMMMMMMM
其中S代表符号位,1代表这个浮点数是一个负数,而0则表示是正数。而E就是科学计数法里面的指数e,由于 e既有可能是正数,也有可能是负数,因为1234.5的科学计数法是1.2345
* 104,而0.12345的科学计数法是1.2345 * 10-1。所以e的计算规则是EEEEEEE
E表示的数减去27- 1(7是因为我们有8个位来表示指数),这样8个表示指数的位就可以用来表示负数和正数了。
而M就是用来计算科学计数法里面的m,计算规则是,从左往右开始,第一个M代表2-1,第二个M表示2-2,依次类推。由于m要么就是大于1的小数,要么就是小于1的小数(记住,我们计数法里面的基数是2 ,而不是10),如果e的值大于0,那么我们就可以加上这个1,如果e的值小于0,那么我们可以省略这个1,这是因为我们总是可以通过调整e的值来做到这一点。因此m里面小数点前面的1被省略掉了,这个省略掉的1可以根据e的值来推算出m的小数点前面到底有没有这个1。
而对于double类型来说,在计算机中各个位表示的信息如下所示:
SEEEEEEE EEEEMMMM MMMMMMMM MMMMMMMM MMMMMMMM MMMMMMMM MMMMMMMM MMMMMMMM
现在我们再回过头来看看上面的代码:
double a = 1.345f;
double b = 1.123f;
double result = a + b;
double expected = 2.468f;
Console.WriteLine("result == expected ? {0}", result
== expected);
调试这个程序,在内存中看一看a的值是3ff5851ec0000000(为了说明方便,我将文章开头的程序改头换面了一下),在计算器里面将这个十六进制的值换算成二进制的是:
11111111110101100001010001111011000000000000000000000000000000
因为计算器会将前缀零省略掉,因此上面的值实际上是:
00111111 11110101 10000101 00011110 11000000 00000000 00000000 00000000
由于e部分的值大于等于0,因为127 – (27 – 1) = 1,所以我们在计算m的时候需要加上隐含的1,也就是说上面黄色背景的值实际上表示的是:
(十进制的)1.0 + 0101 10000101 00011110 11000000 00000000 00000000 00000000所表示的小数
= 1.0 + 2**-2 + 2**-4 + 2**-5 + 2**-10 + 2**-12 + 2**-16 + 2**-17 + 2**-18 + 2**-19 + 2**-21 + 2**-22
= 1.0 + 0.25
+ 0.0625
+ 0.03125
+ 0.0009765625
+ 0.000244140625
+ 0.0000152587890625
+ 0.00000762939453125
+ 0.000003814697265625
+ 0.0000019073486328125
+ 0.000000476837158203125
+ 0.0000002384185791015625
= 1.0 + 0.3450000286102294921875
= 1.3450000286102294921875
因此按照上面的算法,b的值实际上应该是1.1230000257492065,因此a
+ b实际上是2.468000054359436,而上面的程序expected的实际值应该是2.4679999351501465,这就是为什么上面1.345f
+ 1.123f != 2.468f的原因。
而1.344f + 1.123f == 2.467f,纯粹是巧合,因为前两者相加的值恰好等于后者在计算机里面的表现形式。
最后洋洋洒洒一大篇的结论就是,浮点类型不能用==号来判断,因为浮点数是一个近似值,只能通过两者相减小于一个可以接受的误差来判断。
B.
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit,double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,那世界岂不是乱套了么,其实不论是float还是double在存储方式上都是遵从IEEE的规范的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。
无论是单精度还是双精度在存储中都分为三个部分:
符号位(Sign) : 0代表正,1代表为负
指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
尾数部分(Mantissa):尾数部分
其中float的存储方式如下图所示:
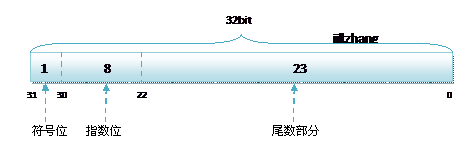
而双精度的存储方式为:

R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十进制的科学计数法表示就为:8.25*
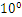
,而120.5可以表示为:1.205*

,这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用二进制的科学计数法表示1000.01可以表示为1.0001*
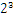
,1110110.1可以表示为1.1101101*
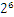
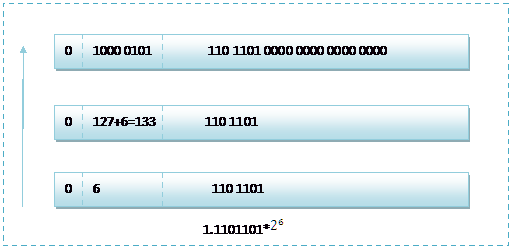
,任何一个数都的科学计数法表示都为1.xxx*
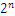
,尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据+127,下面就看看8.25和120.5在内存中真正的存储方式。
首先看下8.25,用二进制的科学计数法表示为:1.0001*
按照上面的存储方式,符号位为:0,表示为正,指数位为:3+127=130 ,位数部分为,故8.25的存储方式如下图所示:
而单精度浮点数120.5的存储方式如下图所示:
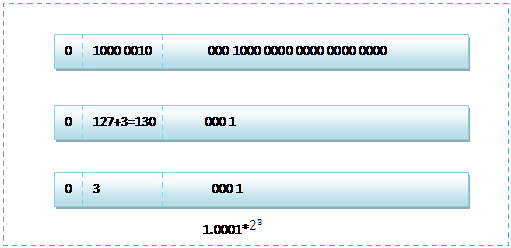
那么如果给出内存中一段数据,并且告诉你是单精度存储的话,你如何知道该数据的十进制数值呢?其实就是对上面的反推过程,比如给出如下内存数据:0100001011101101000000000000,首先我们现将该数据分段,0 10000 0101 110 1101 0000 0000 0000 0000,在内存中的存储就为下图所示:

根据我们的计算方式,可以计算出,这样一组数据表示为:1.1101101*
=120.5
而双精度浮点数的存储和单精度的存储大同小异,不同的是指数部分和尾数部分的位数。所以这里不再详细的介绍双精度的存储方式了,只将120.5的最后存储方式图给出,大家可以仔细想想为何是这样子的

下面我就这个基础知识点来解决一个我们的一个疑惑,请看下面一段程序,注意观察输出结果
float f = 2.2f;
double d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
f = 2.25f;
d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
可能输出的结果让大家疑惑不解,单精度的2.2转换为双精度后,精确到小数点后13位后变为了2.2000000476837,而单精度的2.25转换为双精度后,变为了2.2500000000000,为何2.2在转换后的数值更改了而2.25却没有更改呢?很奇怪吧?其实通过上面关于两种存储结果的介绍,我们已经大概能找到答案。首先我们看看2.25的单精度存储方式,很简单 0 1000 0001 001 0000 0000 0000 0000 0000,而2.25的双精度表示为:0
100 0000 0001 0010 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000,这样2.25在进行强制转换的时候,数值是不会变的,而我们再看看2.2呢,2.2用科学计数法表示应该为:将十进制的小数转换为二进制的小数的方法为将小数*2,取整数部分,所以0.282=0.4,所以二进制小数第一位为0.4的整数部分0,0.4×2=0.8,第二位为0,0.8*2=1.6,第三位为1,0.6×2 = 1.2,第四位为1,0.2*2=0.4,第五位为0,这样永远也不可能乘到=1.0,得到的二进制是一个无限循环的排列
00110011001100110011... ,对于单精度数据来说,尾数只能表示24bit的精度,所以2.2的float存储为:

但是这样存储方式,换算成十进制的值,却不会是2.2的,应为十进制在转换为二进制的时候可能会不准确,如2.2,而double类型的数据也存在同样的问题,所以在浮点数表示中会产生些许的误差,在单精度转换为双精度的时候,也会存在误差的问题,对于能够用二进制表示的十进制数据,如2.25,这个误差就会不存在,所以会出现上面比较奇怪的输出结果。
二、float类型数据的转换方法
C++
#include "stdafx.h"
#include <process.h>
int _tmain(int argc, _TCHAR* argv[])
{
// 将十六进制转换为float形式
unsigned char pMem[] = {0x66,0xE6,0xF0,0x42};
float *p = (float*)pMem;
printf("%g\r\n",*p);
// 将float转换为16进制
float a=120.45f;
unsigned char * b = (unsigned char*)&a;
for(int i = 0; i<4; i++)
printf("0x%2X,", b[i]);
system("pause");
return 0;
}
python:
from ctypes import *
def convert(s):
i = int(s, 16)
cp = pointer(c_int(i))
fp = cast(cp, POINTER(c_float))
return fp.contents.value
print(convert('4756D800'))
源自:
http://www.cnblogs.com/killmyday/archive/2009/03/22/1419079.html
http://www.cnblogs.com/jillzhang/archive/2007/06/24/793901.html
http://blog.csdn.net/kingsollyu/article/details/8270168
A.
下面的代码为什么第一行返回false,而第二行和第三行都返回true。
Console.WriteLine("1.123f + 1.345f == 2.468f ? {0}",
1.123f + 1.345f == 2.468f); // False
Console.WriteLine("1.123f + 1.344f == 2.467f ? {0}",
1.123f + 1.344f == 2.467f); // True
Console.WriteLine("1.123 + 1.345 == 2.468 ? {0}",
1.123 + 1.345 == 2.468); // True
我们知道,integer类型占用的是4个字节,可以表示的数字范围在2**-32到2**32之间.而且每一个整数在计算机里面都有相应的内存表示方法,例如数字12345的表示方法就是:
00000000 00000000 00110000 00111001
即根据二进制到十进制的转换方法: 12345 = 213 + 212 + 25 + 24 +
23 + 20
而在计算机float型,这种表示方法最大的问题就是如何在二进制里面保存小数点的位置--因为小数点的位置不固定.于是计算机专家们就想到了用科学计数法的方式来表示浮点数,因为在科学计数法里面,小数点的位置总是固定,就是在第一个数字的后面,例如12345的科学计数法的表示为: 1.2345
* 105。而0.012345的科学计数法表示方式为: 1.2345 * 10-2.
使用公式来表示的话,科学计数法的公式是 。
因为我们的计算机比较笨,只能处理0和1,所以在计算机里面表示浮点数的时候,上面的公式中的基数b是2,而不是10.在计算机内存当中,保存的实际是浮点数的计算公式,而不是确切的值,所以说计算机里面浮点数都是近似值,而不是确切的值.在计算机中,以float类型为例,内存中32个位所代表的内容分别是:
SEEEEEEE EMMMMMMM MMMMMMMM MMMMMMMM
其中S代表符号位,1代表这个浮点数是一个负数,而0则表示是正数。而E就是科学计数法里面的指数e,由于 e既有可能是正数,也有可能是负数,因为1234.5的科学计数法是1.2345
* 104,而0.12345的科学计数法是1.2345 * 10-1。所以e的计算规则是EEEEEEE
E表示的数减去27- 1(7是因为我们有8个位来表示指数),这样8个表示指数的位就可以用来表示负数和正数了。
而M就是用来计算科学计数法里面的m,计算规则是,从左往右开始,第一个M代表2-1,第二个M表示2-2,依次类推。由于m要么就是大于1的小数,要么就是小于1的小数(记住,我们计数法里面的基数是2 ,而不是10),如果e的值大于0,那么我们就可以加上这个1,如果e的值小于0,那么我们可以省略这个1,这是因为我们总是可以通过调整e的值来做到这一点。因此m里面小数点前面的1被省略掉了,这个省略掉的1可以根据e的值来推算出m的小数点前面到底有没有这个1。
而对于double类型来说,在计算机中各个位表示的信息如下所示:
SEEEEEEE EEEEMMMM MMMMMMMM MMMMMMMM MMMMMMMM MMMMMMMM MMMMMMMM MMMMMMMM
现在我们再回过头来看看上面的代码:
double a = 1.345f;
double b = 1.123f;
double result = a + b;
double expected = 2.468f;
Console.WriteLine("result == expected ? {0}", result
== expected);
调试这个程序,在内存中看一看a的值是3ff5851ec0000000(为了说明方便,我将文章开头的程序改头换面了一下),在计算器里面将这个十六进制的值换算成二进制的是:
11111111110101100001010001111011000000000000000000000000000000
因为计算器会将前缀零省略掉,因此上面的值实际上是:
00111111 11110101 10000101 00011110 11000000 00000000 00000000 00000000
由于e部分的值大于等于0,因为127 – (27 – 1) = 1,所以我们在计算m的时候需要加上隐含的1,也就是说上面黄色背景的值实际上表示的是:
(十进制的)1.0 + 0101 10000101 00011110 11000000 00000000 00000000 00000000所表示的小数
= 1.0 + 2**-2 + 2**-4 + 2**-5 + 2**-10 + 2**-12 + 2**-16 + 2**-17 + 2**-18 + 2**-19 + 2**-21 + 2**-22
= 1.0 + 0.25
+ 0.0625
+ 0.03125
+ 0.0009765625
+ 0.000244140625
+ 0.0000152587890625
+ 0.00000762939453125
+ 0.000003814697265625
+ 0.0000019073486328125
+ 0.000000476837158203125
+ 0.0000002384185791015625
= 1.0 + 0.3450000286102294921875
= 1.3450000286102294921875
因此按照上面的算法,b的值实际上应该是1.1230000257492065,因此a
+ b实际上是2.468000054359436,而上面的程序expected的实际值应该是2.4679999351501465,这就是为什么上面1.345f
+ 1.123f != 2.468f的原因。
而1.344f + 1.123f == 2.467f,纯粹是巧合,因为前两者相加的值恰好等于后者在计算机里面的表现形式。
最后洋洋洒洒一大篇的结论就是,浮点类型不能用==号来判断,因为浮点数是一个近似值,只能通过两者相减小于一个可以接受的误差来判断。
B.
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit,double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,那世界岂不是乱套了么,其实不论是float还是double在存储方式上都是遵从IEEE的规范的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。
无论是单精度还是双精度在存储中都分为三个部分:
符号位(Sign) : 0代表正,1代表为负
指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
尾数部分(Mantissa):尾数部分
其中float的存储方式如下图所示:
而双精度的存储方式为:
R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十进制的科学计数法表示就为:8.25*
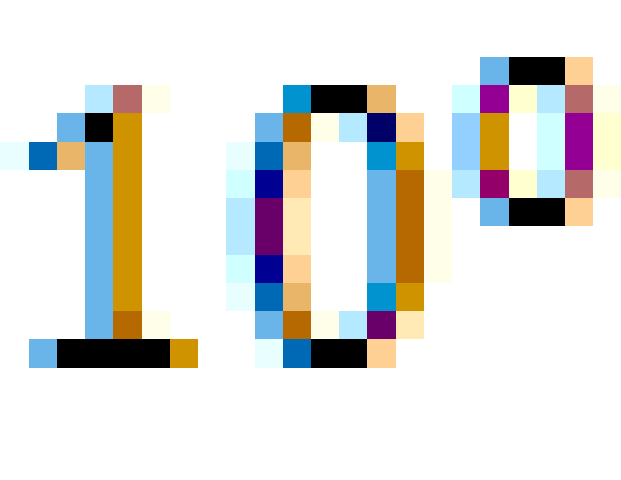
,而120.5可以表示为:1.205*
,这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用二进制的科学计数法表示1000.01可以表示为1.0001*

,1110110.1可以表示为1.1101101*

,任何一个数都的科学计数法表示都为1.xxx*

,尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据+127,下面就看看8.25和120.5在内存中真正的存储方式。
首先看下8.25,用二进制的科学计数法表示为:1.0001*
按照上面的存储方式,符号位为:0,表示为正,指数位为:3+127=130 ,位数部分为,故8.25的存储方式如下图所示:
而单精度浮点数120.5的存储方式如下图所示:
那么如果给出内存中一段数据,并且告诉你是单精度存储的话,你如何知道该数据的十进制数值呢?其实就是对上面的反推过程,比如给出如下内存数据:0100001011101101000000000000,首先我们现将该数据分段,0 10000 0101 110 1101 0000 0000 0000 0000,在内存中的存储就为下图所示:
根据我们的计算方式,可以计算出,这样一组数据表示为:1.1101101*
=120.5
而双精度浮点数的存储和单精度的存储大同小异,不同的是指数部分和尾数部分的位数。所以这里不再详细的介绍双精度的存储方式了,只将120.5的最后存储方式图给出,大家可以仔细想想为何是这样子的
下面我就这个基础知识点来解决一个我们的一个疑惑,请看下面一段程序,注意观察输出结果
float f = 2.2f;
double d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
f = 2.25f;
d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
可能输出的结果让大家疑惑不解,单精度的2.2转换为双精度后,精确到小数点后13位后变为了2.2000000476837,而单精度的2.25转换为双精度后,变为了2.2500000000000,为何2.2在转换后的数值更改了而2.25却没有更改呢?很奇怪吧?其实通过上面关于两种存储结果的介绍,我们已经大概能找到答案。首先我们看看2.25的单精度存储方式,很简单 0 1000 0001 001 0000 0000 0000 0000 0000,而2.25的双精度表示为:0
100 0000 0001 0010 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000,这样2.25在进行强制转换的时候,数值是不会变的,而我们再看看2.2呢,2.2用科学计数法表示应该为:将十进制的小数转换为二进制的小数的方法为将小数*2,取整数部分,所以0.282=0.4,所以二进制小数第一位为0.4的整数部分0,0.4×2=0.8,第二位为0,0.8*2=1.6,第三位为1,0.6×2 = 1.2,第四位为1,0.2*2=0.4,第五位为0,这样永远也不可能乘到=1.0,得到的二进制是一个无限循环的排列
00110011001100110011... ,对于单精度数据来说,尾数只能表示24bit的精度,所以2.2的float存储为:
但是这样存储方式,换算成十进制的值,却不会是2.2的,应为十进制在转换为二进制的时候可能会不准确,如2.2,而double类型的数据也存在同样的问题,所以在浮点数表示中会产生些许的误差,在单精度转换为双精度的时候,也会存在误差的问题,对于能够用二进制表示的十进制数据,如2.25,这个误差就会不存在,所以会出现上面比较奇怪的输出结果。
二、float类型数据的转换方法
C++
#include "stdafx.h"
#include <process.h>
int _tmain(int argc, _TCHAR* argv[])
{
// 将十六进制转换为float形式
unsigned char pMem[] = {0x66,0xE6,0xF0,0x42};
float *p = (float*)pMem;
printf("%g\r\n",*p);
// 将float转换为16进制
float a=120.45f;
unsigned char * b = (unsigned char*)&a;
for(int i = 0; i<4; i++)
printf("0x%2X,", b[i]);
system("pause");
return 0;
}
python:
from ctypes import *
def convert(s):
i = int(s, 16)
cp = pointer(c_int(i))
fp = cast(cp, POINTER(c_float))
return fp.contents.value
print(convert('4756D800'))
源自:
http://www.cnblogs.com/killmyday/archive/2009/03/22/1419079.html
http://www.cnblogs.com/jillzhang/archive/2007/06/24/793901.html
http://blog.csdn.net/kingsollyu/article/details/8270168

相关文章推荐
- .net学习之.net和C#关系、运行过程、数据类型、类型转换、值类型和引用类型、数组以及方法参数等
- c#数据类型转换,与其BYTE,float,double,char类型间的转换方法
- float、double类型的数据在计算机内部的表示法
- c#数据类型转换,BYTE,float,double,char类型间的转换方法
- 基本数据类型的转换和表示方法
- c#数据类型转换,BYTE,float,double,char类型间的转换方法
- int、double、boolean、char、float、long、Object等七种数据类型转换成String数据类型 用到的方法是String.valueOf();
- c#数据类型转换,BYTE,float,double,char类型间的转换方法
- Java中几种常用数据类型之间转换的方法
- 数据契约:CLR数据类型和与平台无关表示形式的转换
- 用ObjectDataProvider绑定方法,用IValueConverter实现数据类型转换,重载ValidationRule实现数据验证,BindsDirectlyToSource等
- 常见Java 中数据类型之间的转换的方法!
- 使用ASP.NET AJAX异步调用Web Service和页面中的类方法(9):服务器端和客户端数据类型的自动转换:DataTable和DataSet
- JAVA基本数据类型与其他语言数据类型之间的转换方法
- 关于2147217913 从 char 数据类型到 datetime 数据类型的转换导致 datetime 值越界 的问题解决方法
- 使用ASP.NET AJAX异步调用Web Service和页面中的类方法(9):服务器端和客户端数据类型的自动转换:DataTable和DataSet
- 更新数据库所有表的某一个指定字段 ,附加对‘将 varchar 值转换为数据类型为 int 的列时发生语法错误’处理方法
- 使用ASP.NET AJAX异步调用Web Service和页面中的类方法(6):服务器端和客户端数据类型的自动转换:复杂类型
- 使用ASP.NET AJAX异步调用Web Service和页面中的类方法(10):服务器端和客户端数据类型的自动转换:以XML方式序列化数据、小结
- Java基础小知识——基本数据类型和字符串以及字节数组的转换