hadoop put内部调用,hdfs写文件流程
2015-03-10 15:58
691 查看
HDFS是一个分布式文件系统,在HDFS上写文件的过程与我们平时使用的单机文件系统非常不同,从宏观上来看,在HDFS文件系统上创建并写一个文件,流程如下图(来自《Hadoop:The Definitive Guide》一书)所示:
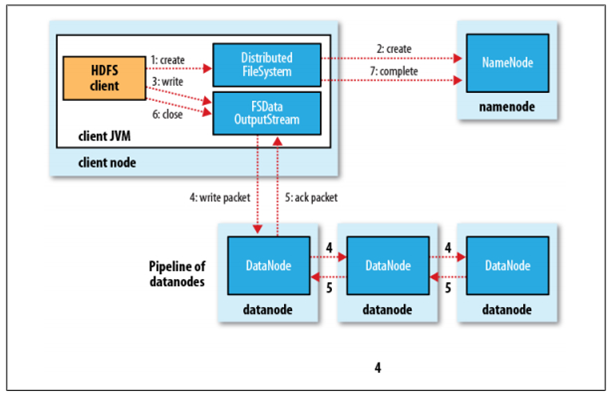
具体过程描述如下:
Client调用DistributedFileSystem对象的create方法,创建一个文件输出流(FSDataOutputStream)对象
通过DistributedFileSystem对象与Hadoop集群的NameNode进行一次RPC远程调用,在HDFS的Namespace中创建一个文件条目(Entry),该条目没有任何的Block
通过FSDataOutputStream对象,向DataNode写入数据,数据首先被写入FSDataOutputStream对象内部的Buffer中,然后数据被分割成一个个Packet数据包
以Packet最小单位,基于Socket连接发送到按特定算法选择的HDFS集群中一组DataNode(正常是3个,可能大于等于1)中的一个节点上,在这组DataNode组成的Pipeline上依次传输Packet
这组DataNode组成的Pipeline反方向上,发送ack,最终由Pipeline中第一个DataNode节点将Pipeline ack发送给Client
完成向文件写入数据,Client在文件输出流(FSDataOutputStream)对象上调用close方法,关闭流
调用DistributedFileSystem对象的complete方法,通知NameNode文件写入成功
下面代码使用Hadoop的API来实现向HDFS的文件写入数据,同样也包括创建一个文件和写数据两个主要过程,代码如下所示:
结合上面的示例代码,我们先从fs.create(path);开始,可以看到FileSystem的实现DistributedFileSystem中给出了最终返回FSDataOutputStream对象的抽象逻辑,代码如下所示:
上面,DFSClient dfs的create方法中创建了一个OutputStream对象,在DFSClient的create方法:
创建了一个DFSOutputStream对象,如下所示:
下面,我们从DFSOutputStream类开始,说明其内部实现原理。
DFSOutputStream内部原理
打开一个DFSOutputStream流,Client会写数据到流内部的一个缓冲区中,然后数据被分解成多个Packet,每个Packet大小为64k字节,每个Packet又由一组chunk和这组chunk对应的checksum数据组成,默认chunk大小为512字节,每个checksum是对512字节数据计算的校验和数据。
当Client写入的字节流数据达到一个Packet的长度,这个Packet会被构建出来,然后会被放到队列dataQueue中,接着DataStreamer线程会不断地从dataQueue队列中取出Packet,发送到复制Pipeline中的第一个DataNode上,并将该Packet从dataQueue队列中移到ackQueue队列中。ResponseProcessor线程接收从Datanode发送过来的ack,如果是一个成功的ack,表示复制Pipeline中的所有Datanode都已经接收到这个Packet,ResponseProcessor线程将packet从队列ackQueue中删除。
在发送过程中,如果发生错误,所有未完成的Packet都会从ackQueue队列中移除掉,然后重新创建一个新的Pipeline,排除掉出错的那些DataNode节点,接着DataStreamer线程继续从dataQueue队列中发送Packet。
下面是DFSOutputStream的结构及其原理,如图所示:

我们从下面3个方面来描述内部流程:
创建Packet
Client写数据时,会将字节流数据缓存到内部的缓冲区中,当长度满足一个Chunk大小(512B)时,便会创建一个Packet对象,然后向该Packet对象中写Chunk Checksum校验和数据,以及实际数据块Chunk Data,校验和数据是基于实际数据块计算得到的。每次满足一个Chunk大小时,都会向Packet中写上述数据内容,直到达到一个Packet对象大小(64K),就会将该Packet对象放入到dataQueue队列中,等待DataStreamer线程取出并发送到DataNode节点。
发送Packet
DataStreamer线程从dataQueue队列中取出Packet对象,放到ackQueue队列中,然后向DataNode节点发送这个Packet对象所对应的数据。
接收ack
发送一个Packet数据包以后,会有一个用来接收ack的ResponseProcessor线程,如果收到成功的ack,则表示一个Packet发送成功。如果成功,则ResponseProcessor线程会将ackQueue队列中对应的Packet删除。
DFSOutputStream初始化
首先看一下,DFSOutputStream的初始化过程,构造方法如下所示:
我们用默认的参数值替换上面的参数,得到:
上面对应的参数,说明如下表所示:
在计算好一个packet相关的参数以后,调用create方法与Namenode进行RPC请求,请求创建文件:
远程调用上面方法,会在FSNamesystem中创建对应的文件路径,并初始化与该创建的文件相关的一些信息,如租约(向Datanode节点写数据的凭据)。文件在FSNamesystem中创建成功,就要初始化并启动一个DataStreamer线程,用来向Datanode写数据,后面我们详细说明具体处理逻辑。
Packet结构与定义
Client向HDFS写数据,数据会被组装成Packet,然后发送到Datanode节点。Packet分为两类,一类是实际数据包,另一类是heatbeat包。一个Packet数据包的组成结构,如图所示:
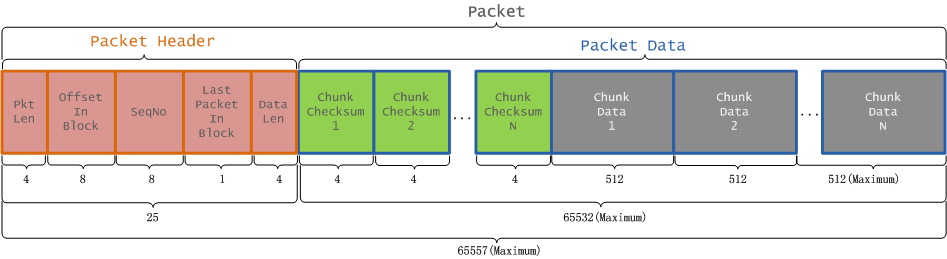
上图中,一个Packet是由Header和Data两部分组成,其中Header部分包含了一个Packet的概要属性信息,如下表所示:
Data部分是一个Packet的实际数据部分,主要包括一个4字节校验和(Checksum)与一个Chunk部分,Chunk部分最大为512字节。
在构建一个Packet的过程中,首先将字节流数据写入一个buffer缓冲区中,也就是从偏移量为25的位置(checksumStart)开始写Packet数据的Chunk Checksum部分,从偏移量为533的位置(dataStart)开始写Packet数据的Chunk Data部分,直到一个Packet创建完成为止。如果一个Packet的大小未能达到最大长度,也就是上图对应的缓冲区中,Chunk Checksum与Chunk Data之间还保留了一段未被写过的缓冲区位置,这种情况说明,已经在写一个文件的最后一个Block的最后一个Packet。在发送这个Packet之前,会检查Chunksum与Chunk
Data之间的缓冲区是否为空白缓冲区(gap),如果有则将Chunk Data部分向前移动,使得Chunk Data 1与Chunk Checksum N相邻,然后才会被发送到DataNode节点。
我们看一下Packet对应的Packet类定义,定义了如下一些字段:
Packet类有一个默认的没有参数的构造方法,它是用来做heatbeat的,如下所示:
通过代码可以看到,一个heatbeat的内容,实际上只有一个长度为25字节的header数据。通过this.seqno = HEART_BEAT_SEQNO;的值可以判断一个packet是否是heatbeat包,如果seqno为-1表示这是一个heatbeat包。
Client发送Packet数据
可以DFSClient类中看到,发送一个Packet之前,首先需要向选定的DataNode发送一个Header数据包,表明要向DataNode写数据,该Header的数据结构,如图所示:
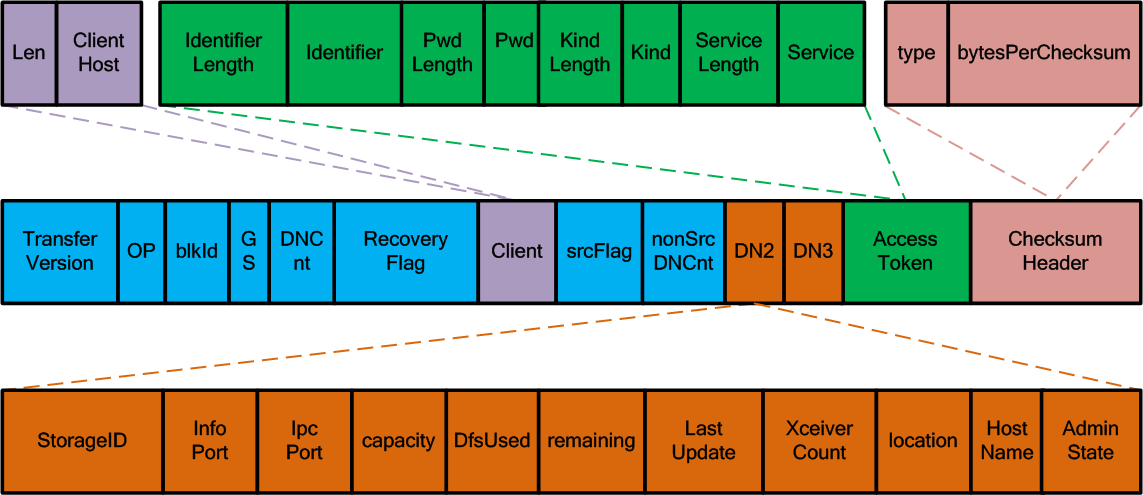
上图显示的是Client发送Packet到第一个DataNode节点的Header数据结构,主要包括待发送的Packet所在的Block(先向NameNode分配Block ID等信息)的相关信息、Pipeline中另外2个DataNode的信息、访问令牌(Access Token)和校验和信息,Header中各个字段及其类型,详见下表:
Header数据包发送成功,Client会收到一个成功响应码(DataTransferProtocol.OP_STATUS_SUCCESS = 0),接着将Packet数据发送到Pipeline中第一个DataNode上,如下所示:
否则,如果失败,则会与NameNode进行RPC调用,删除该Block,并把该Pipeline中第一个DataNode加入到excludedNodes列表中,代码如下所示:
DataNode端服务组件
数据最终会发送到DataNode节点上,在一个DataNode上,数据在各个组件之间流动,流程如下图所示:
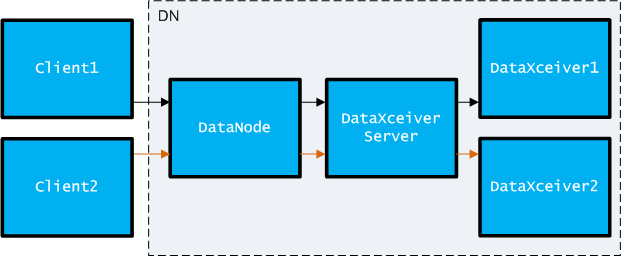
DataNode服务中创建一个后台线程DataXceiverServer,它是一个SocketServer,用来接收来自Client(或者DataNode Pipeline中的非最后一个DataNode节点)的写数据请求,然后在DataXceiverServer中将连接过来的Socket直接派发给一个独立的后台线程DataXceiver进行处理。所以,Client写数据时连接一个DataNode Pipeline的结构,实际流程如图所示:
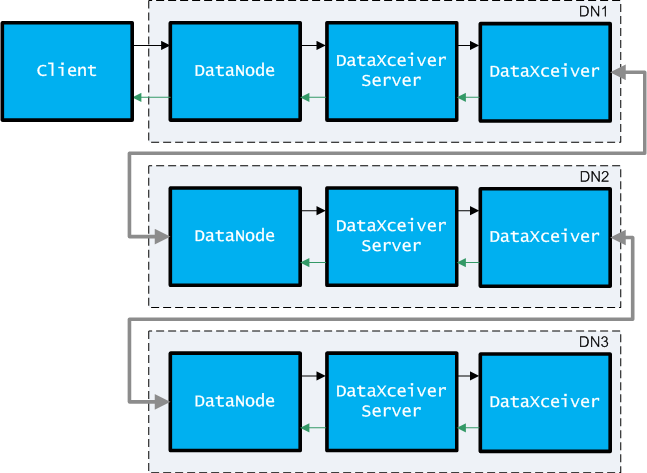
每个DataNode服务中的DataXceiver后台线程接收到来自前一个节点(Client/DataNode)的Socket连接,首先读取Header数据:
上面代码中,读取Header的数据,与前一个Client/DataNode写入Header字段的顺序相对应,不再累述。在完成读取Header数据后,当前DataNode会首先将Header数据再发送到Pipeline中下一个DataNode结点,当然该DataNode肯定不是Pipeline中最后一个DataNode节点。接着,该DataNode会接收来自前一个Client/DataNode节点发送的Packet数据,接收Packet数据的逻辑实际上在BlockReceiver中完成,包括将来自前一个Client/DataNode节点发送的Packet数据写入本地磁盘。在BlockReceiver中,首先会将接收到的Packet数据发送写入到Pipeline中下一个DataNode节点,然后再将接收到的数据写入到本地磁盘的Block文件中。
DataNode持久化Packet数据
在DataNode节点的BlockReceiver中进行Packet数据的持久化,一个Packet是一个Block中一个数据分组,我们首先看一下,一个Block在持久化到磁盘上的物理存储结构,如下图所示:
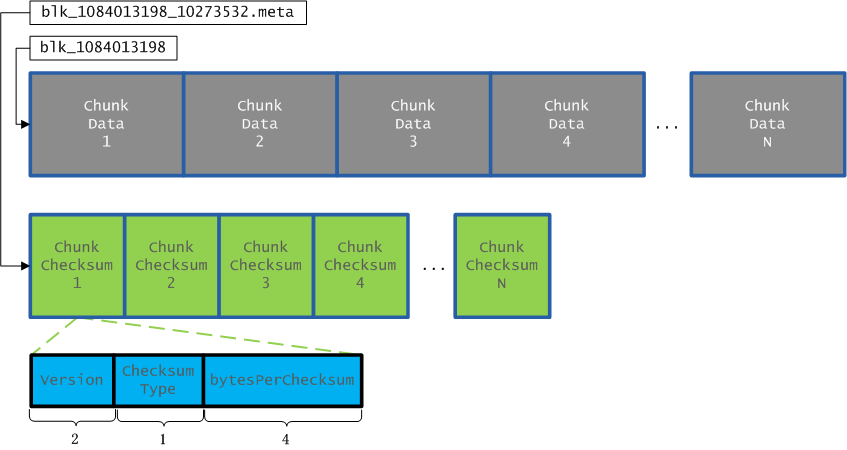
每个Block文件(如上图中blk_1084013198文件)都对应一个meta文件(如上图中blk_1084013198_10273532.meta文件),Block文件是一个一个Chunk的二进制数据(每个Chunk的大小是512字节),而meta文件是与每一个Chunk对应的Checksum数据,是序列化形式存储。
写文件过程中Client/DataNode与NameNode进行RPC调用
Client在HDFS文件系统中写文件过程中,会发生多次与NameNode节点进行RPC调用来完成写数据相关操作,主要是在如下时机进行RPC调用:
写文件开始时创建文件:Client调用create在NameNode节点的Namespace中创建一个标识该文件的条目
在Client连接Pipeline中第一个DataNode节点之前,Client调用addBlock分配一个Block(blkId+DataNode列表+租约)
如果与Pipeline中第一个DataNode节点连接失败,Client调用abandonBlock放弃一个已经分配的Block
一个Block已经写入到DataNode节点磁盘,Client调用fsync让NameNode持久化Block的位置信息数据
文件写完以后,Client调用complete方法通知NameNode写入文件成功
DataNode节点接收到并成功持久化一个Block的数据后,DataNode调用blockReceived方法通知NameNode已经接收到Block
具体RPC调用的详细过程,可以参考源码。
具体过程描述如下:
Client调用DistributedFileSystem对象的create方法,创建一个文件输出流(FSDataOutputStream)对象
通过DistributedFileSystem对象与Hadoop集群的NameNode进行一次RPC远程调用,在HDFS的Namespace中创建一个文件条目(Entry),该条目没有任何的Block
通过FSDataOutputStream对象,向DataNode写入数据,数据首先被写入FSDataOutputStream对象内部的Buffer中,然后数据被分割成一个个Packet数据包
以Packet最小单位,基于Socket连接发送到按特定算法选择的HDFS集群中一组DataNode(正常是3个,可能大于等于1)中的一个节点上,在这组DataNode组成的Pipeline上依次传输Packet
这组DataNode组成的Pipeline反方向上,发送ack,最终由Pipeline中第一个DataNode节点将Pipeline ack发送给Client
完成向文件写入数据,Client在文件输出流(FSDataOutputStream)对象上调用close方法,关闭流
调用DistributedFileSystem对象的complete方法,通知NameNode文件写入成功
下面代码使用Hadoop的API来实现向HDFS的文件写入数据,同样也包括创建一个文件和写数据两个主要过程,代码如下所示:
01 | static String[] contents = new String[]
{ |
02 | "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" , |
03 | "bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb" , |
04 | "cccccccccccccccccccccccccccccccccccccccccccccccccccccccccc" , |
05 | "dddddddddddddddddddddddddddddddd" , |
06 | "eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee" , |
07 | }; |
08 |
09 | public static void main(String[]
args){ |
10 | String file = "hdfs://h1:8020/data/test/test.log" ; |
11 | Path path = new Path(file); |
12 | Configuration conf = new Configuration(); |
13 | FileSystem fs = null ; |
14 | FSDataOutputStream output = null ; |
15 | try { |
16 | fs = path.getFileSystem(conf); |
17 | output = fs.create(path); // 创建文件 |
18 | for (String
line : contents){// 写入数据 |
19 | output.write(line.getBytes( "UTF-8" )); |
20 | output.flush(); |
21 | } |
22 | } catch (IOException
e){ |
23 | e.printStackTrace(); |
24 | } finally { |
25 | try { |
26 | output.close(); |
27 | } catch (IOException
e){ |
28 | e.printStackTrace(); |
29 | } |
30 | } |
31 | } |
1 | public FSDataOutputStream create(Path f,FsPermission permission, |
2 | boolean overwrite, |
3 | int bufferSize, short replication, long blockSize, |
4 | Progressable progress) throws IOException
{ |
5 |
6 | statistics.incrementWriteOps( 1 ); |
7 | return new FSDataOutputStream |
8 | (dfs.create(getPathName(f), permission,overwrite, true , |
9 | } |
01 | public OutputStream create(String src, |
02 | FsPermission permission, |
03 | boolean overwrite, |
04 | boolean createParent, |
05 | short replication, |
06 | long blockSize, |
07 | Progressable progress, |
08 | int buffersize |
09 | ) throws IOException
{ |
10 | ... ... |
11 | } |
1 | final DFSOutputStream result = new DFSOutputStream(src, masked, |
2 | overwrite, |
3 | conf.getInt( "io.bytes.per.checksum" , 512 )); |
DFSOutputStream内部原理
打开一个DFSOutputStream流,Client会写数据到流内部的一个缓冲区中,然后数据被分解成多个Packet,每个Packet大小为64k字节,每个Packet又由一组chunk和这组chunk对应的checksum数据组成,默认chunk大小为512字节,每个checksum是对512字节数据计算的校验和数据。
当Client写入的字节流数据达到一个Packet的长度,这个Packet会被构建出来,然后会被放到队列dataQueue中,接着DataStreamer线程会不断地从dataQueue队列中取出Packet,发送到复制Pipeline中的第一个DataNode上,并将该Packet从dataQueue队列中移到ackQueue队列中。ResponseProcessor线程接收从Datanode发送过来的ack,如果是一个成功的ack,表示复制Pipeline中的所有Datanode都已经接收到这个Packet,ResponseProcessor线程将packet从队列ackQueue中删除。
在发送过程中,如果发生错误,所有未完成的Packet都会从ackQueue队列中移除掉,然后重新创建一个新的Pipeline,排除掉出错的那些DataNode节点,接着DataStreamer线程继续从dataQueue队列中发送Packet。
下面是DFSOutputStream的结构及其原理,如图所示:
我们从下面3个方面来描述内部流程:
创建Packet
Client写数据时,会将字节流数据缓存到内部的缓冲区中,当长度满足一个Chunk大小(512B)时,便会创建一个Packet对象,然后向该Packet对象中写Chunk Checksum校验和数据,以及实际数据块Chunk Data,校验和数据是基于实际数据块计算得到的。每次满足一个Chunk大小时,都会向Packet中写上述数据内容,直到达到一个Packet对象大小(64K),就会将该Packet对象放入到dataQueue队列中,等待DataStreamer线程取出并发送到DataNode节点。
发送Packet
DataStreamer线程从dataQueue队列中取出Packet对象,放到ackQueue队列中,然后向DataNode节点发送这个Packet对象所对应的数据。
接收ack
发送一个Packet数据包以后,会有一个用来接收ack的ResponseProcessor线程,如果收到成功的ack,则表示一个Packet发送成功。如果成功,则ResponseProcessor线程会将ackQueue队列中对应的Packet删除。
DFSOutputStream初始化
首先看一下,DFSOutputStream的初始化过程,构造方法如下所示:
01 | DFSOutputStream(String boolean overwrite, |
02 | boolean createParent, short replication, long blockSize, Progressable progress, |
03 | int buffersize, int bytesPerChecksum) throws IOException
{ |
04 | this (src, |
05 |
06 | computePacketChunkSize(writePacketSize, bytesPerChecksum); // 默认 writePacketSize=64*1024(即64K),bytesPerChecksum=512(没512个字节计算一个校验和), |
07 |
08 | try { |
09 | if (createParent)
{// createParent为true表示,如果待创建的文件的父级目录不存在,则自动创建 |
10 | namenode.create(src, |
11 | } else { |
12 | namenode.create(src, false , |
13 | } |
14 | } catch (RemoteException |
15 | throw re.unwrapRemoteException(AccessControlException. class , |
16 | FileAlreadyExistsException. class , |
17 | FileNotFoundException. class , |
18 | NSQuotaExceededException. class , |
19 | DSQuotaExceededException. class ); |
20 | } |
21 | streamer.start(); // 启动一个DataStreamer线程,用来将写入的字节流打包成packet,然后发送到对应的Datanode节点上 |
22 | } |
23 | 上面computePacketChunkSize方法计算了一个packet的相关参数,我们结合代码来查看,如下所示: |
24 | int chunkSize = csize +checksum.getChecksumSize(); |
25 | int n = DataNode.PKT_HEADER_LEN +SIZE_OF_INTEGER; |
26 | chunksPerPacket = Math.max((psize -n +chunkSize- 1 )/chunkSize, 1 ); |
27 | packetSize = n +chunkSize*chunksPerPacket; |
1 | int chunkSize = 512 + 4 ; |
2 | int n = 21 + 4 ; |
3 | chunksPerPacket = Math.max(( 64 * 1024 - 25 + 516 - 1 )/ 516 , 1 ); // 127 |
4 | packetSize = 25 + 516 * 127 ; |
| 参数名称 | 参数值 | 参数含义 |
| chunkSize | 512+4=516 | 每个chunk的字节数(数据+校验和) |
| csize | 512 | 每个chunk数据的字节数 |
| psize | 64*1024 | 每个packet的最大字节数(不包含header) |
| DataNode.PKT_HEADER_LEN | 21 | 每个packet的header的字节数 |
| chunksPerPacket | 127 | 组成每个packet的chunk的个数 |
| packetSize | 25+516*127=65557 | 每个packet的字节数(一个header+一组chunk) |
1 | if (createParent)
{// createParent为true表示,如果待创建的文件的父级目录不存在,则自动创建 |
2 | namenode.create(src, |
3 | } else { |
4 | namenode.create(src, false , |
5 | } |
Packet结构与定义
Client向HDFS写数据,数据会被组装成Packet,然后发送到Datanode节点。Packet分为两类,一类是实际数据包,另一类是heatbeat包。一个Packet数据包的组成结构,如图所示:
上图中,一个Packet是由Header和Data两部分组成,其中Header部分包含了一个Packet的概要属性信息,如下表所示:
| 字段名称 | 字段类型 | 字段长度 | 字段含义 |
| pktLen | int | 4 | 4 +dataLen +checksumLen |
| offsetInBlock | long | 8 | Packet在Block中偏移量 |
| seqNo | long | 8 | Packet序列号,在同一个Block唯一 |
| lastPacketInBlock | boolean | 1 | 是否是一个Block的最后一个Packet |
| dataLen | int | 4 | dataPos – dataStart,不包含Header和Checksum的长度 |
在构建一个Packet的过程中,首先将字节流数据写入一个buffer缓冲区中,也就是从偏移量为25的位置(checksumStart)开始写Packet数据的Chunk Checksum部分,从偏移量为533的位置(dataStart)开始写Packet数据的Chunk Data部分,直到一个Packet创建完成为止。如果一个Packet的大小未能达到最大长度,也就是上图对应的缓冲区中,Chunk Checksum与Chunk Data之间还保留了一段未被写过的缓冲区位置,这种情况说明,已经在写一个文件的最后一个Block的最后一个Packet。在发送这个Packet之前,会检查Chunksum与Chunk
Data之间的缓冲区是否为空白缓冲区(gap),如果有则将Chunk Data部分向前移动,使得Chunk Data 1与Chunk Checksum N相邻,然后才会被发送到DataNode节点。
我们看一下Packet对应的Packet类定义,定义了如下一些字段:
01 | ByteBuffer // only one of buf and buffer is non-null |
02 | byte [] buf; |
03 | long seqno; // sequencenumber of buffer in block |
04 | long offsetInBlock; // 该packet在block中的偏移量 |
05 | boolean lastPacketInBlock; // is this the last packet in block? |
06 | int numChunks; // number of chunks currently in packet |
07 | int maxChunks; // 一个packet中包含的chunk的个数 |
08 | int dataStart; |
09 | int dataPos; |
10 | int checksumStart; |
11 | int checksumPos; |
01 | Packet()
{ |
02 | this .lastPacketInBlock = false ; |
03 | this .numChunks = 0 ; |
04 | this .offsetInBlock = 0 ; |
05 | this .seqno = HEART_BEAT_SEQNO; // 值为-1 |
06 |
07 | buffer = null ; |
08 | int packetSize =DataNode.PKT_HEADER_LEN +SIZE_OF_INTEGER; // 21+4=25 |
09 | buf = new byte [packetSize]; |
10 |
11 | checksumStart = dataStart = packetSize; |
12 | checksumPos = checksumStart; |
13 | dataPos = dataStart; |
14 | maxChunks = 0 ; |
15 | } |
Client发送Packet数据
可以DFSClient类中看到,发送一个Packet之前,首先需要向选定的DataNode发送一个Header数据包,表明要向DataNode写数据,该Header的数据结构,如图所示:
上图显示的是Client发送Packet到第一个DataNode节点的Header数据结构,主要包括待发送的Packet所在的Block(先向NameNode分配Block ID等信息)的相关信息、Pipeline中另外2个DataNode的信息、访问令牌(Access Token)和校验和信息,Header中各个字段及其类型,详见下表:
| 字段名称 | 字段类型 | 字段长度 | 字段含义 |
| Transfer Version | short | 2 | Client与DataNode之间数据传输版本号,由常量DataTransferProtocol.DATA_TRANSFER_VERSION定义,值为17 |
| OP | int | 4 | 操作类型,由常量DataTransferProtocol.OP_WRITE_BLOCK定义,值为80 |
| blkId | long | 8 | Block的ID值,由NameNode分配 |
| GS | long | 8 | 时间戳(Generation Stamp),NameNode分配blkId的时候生成的时间戳 |
| DNCnt | int | 4 | DataNode复制Pipeline中DataNode节点的数量 |
| Recovery Flag | boolean | 1 | Recover标志 |
| Client | Text | Client主机的名称,在使用Text进行序列化的时候,实际包含长度len与主机名称字符串ClientHost | |
| srcNode | boolean | 1 | 是否发送src node的信息,默认值为false,不发送src node的信息 |
| nonSrcDNCnt | int | 4 | 由Client写的该Header数据,该数不包含Pipeline中第一个节点(即为DNCnt-1) |
| DN2 | DatanodeInfo | DataNode信息,包括StorageID、InfoPort、IpcPort、capacity、DfsUsed、remaining、LastUpdate、XceiverCount、Location、HostName、AdminState | |
| DN3 | DatanodeInfo | DataNode信息,包括StorageID、InfoPort、IpcPort、capacity、DfsUsed、remaining、LastUpdate、XceiverCount、Location、HostName、AdminState | |
| Access Token | Token | 访问令牌信息,包括IdentifierLength、Identifier、PwdLength、Pwd、KindLength、Kind、ServiceLength、Service | |
| CheckSum Header | DataChecksum | 1+4 | 校验和Header信息,包括type、bytesPerChecksum |
1 | Packet one = null ; |
2 | one = dataQueue.getFirst(); // regular data packet |
3 | ByteBuffer buf = one.getBuffer(); |
4 | // write out data to remote datanode |
5 | blockStream.write(buf.array(), |
6 |
7 | if (one.lastPacketInBlock)
{// 如果是Block中的最后一个Packet,还要写入一个0标识该Block已经写入完成 |
8 | blockStream.writeInt( 0 ); // indicate end-of-block |
9 | } |
01 | if (!success)
{ |
02 | LOG.info( "Abandoning " + block); |
03 | namenode.abandonBlock(block, |
04 |
05 | if (errorIndex |
06 | LOG.info( "Excluding datanode " + nodes[errorIndex]); |
07 | excludedNodes.add(nodes[errorIndex]); |
08 | } |
09 |
10 | // |
11 | retry = true ; |
12 | } |
数据最终会发送到DataNode节点上,在一个DataNode上,数据在各个组件之间流动,流程如下图所示:
DataNode服务中创建一个后台线程DataXceiverServer,它是一个SocketServer,用来接收来自Client(或者DataNode Pipeline中的非最后一个DataNode节点)的写数据请求,然后在DataXceiverServer中将连接过来的Socket直接派发给一个独立的后台线程DataXceiver进行处理。所以,Client写数据时连接一个DataNode Pipeline的结构,实际流程如图所示:
每个DataNode服务中的DataXceiver后台线程接收到来自前一个节点(Client/DataNode)的Socket连接,首先读取Header数据:
01 | Block block = new Block(in.readLong(), |
02 | LOG.info( "Receiving " + " src: " + " dest: " + localAddress); |
03 | int pipelineSize // num of datanodes in entire pipeline |
04 | boolean isRecovery // is this part of recovery? |
05 | String // working on behalf of this client |
06 | boolean hasSrcDataNode // is src node info present |
07 | if (hasSrcDataNode)
{ |
08 | srcDataNode = new DatanodeInfo(); |
09 | srcDataNode.readFields(in); |
10 | } |
11 | int numTargets = in.readInt(); |
12 | if (numTargets < 0 )
{ |
13 | throw new IOException( "Mislabelled incoming datastream." ); |
14 | } |
15 | DatanodeInfo targets[] = new DatanodeInfo[numTargets]; |
16 | for ( int i = 0 ; |
17 | DatanodeInfo tmp = new DatanodeInfo(); |
18 | tmp.readFields(in); |
19 | targets[i] = tmp; |
20 | } |
21 | Token<BlockTokenIdentifier> accessToken = new Token<BlockTokenIdentifier>(); |
22 | accessToken.readFields(in); |
DataNode持久化Packet数据
在DataNode节点的BlockReceiver中进行Packet数据的持久化,一个Packet是一个Block中一个数据分组,我们首先看一下,一个Block在持久化到磁盘上的物理存储结构,如下图所示:
每个Block文件(如上图中blk_1084013198文件)都对应一个meta文件(如上图中blk_1084013198_10273532.meta文件),Block文件是一个一个Chunk的二进制数据(每个Chunk的大小是512字节),而meta文件是与每一个Chunk对应的Checksum数据,是序列化形式存储。
写文件过程中Client/DataNode与NameNode进行RPC调用
Client在HDFS文件系统中写文件过程中,会发生多次与NameNode节点进行RPC调用来完成写数据相关操作,主要是在如下时机进行RPC调用:
写文件开始时创建文件:Client调用create在NameNode节点的Namespace中创建一个标识该文件的条目
在Client连接Pipeline中第一个DataNode节点之前,Client调用addBlock分配一个Block(blkId+DataNode列表+租约)
如果与Pipeline中第一个DataNode节点连接失败,Client调用abandonBlock放弃一个已经分配的Block
一个Block已经写入到DataNode节点磁盘,Client调用fsync让NameNode持久化Block的位置信息数据
文件写完以后,Client调用complete方法通知NameNode写入文件成功
DataNode节点接收到并成功持久化一个Block的数据后,DataNode调用blockReceived方法通知NameNode已经接收到Block
具体RPC调用的详细过程,可以参考源码。

相关文章推荐
- 【Hadoop】HDFS - 创建文件流程详解
- <hadoop学习历程>--笔记心得4-HDFS文件读写流程
- 【Hadoop】HDFS - 创建文件流程详解
- Hadoop深入学习:解析HDFS的写文件流程
- hadoop之 解析HDFS的写文件流程
- Hadoop_HDFS文件读写代码流程解析和副本存放机制
- hadoop 提高hdfs删文件效率----hadoop删除文件流程解析
- Hadoop之HDFS文件读取流程
- hadoop2.7.3源码解析之hdfs删除文件全流程分析
- hadoop之 解析HDFS的写文件流程
- hadoop源码解析之hdfs写数据全流程分析---创建文件
- 一个hadoop hdfs put 文件失败的小情况
- 【Hadoop】HDFS - 创建文件流程详解
- Hadoop fs -put:上传文件至Hdfs总是失败
- hadoop 提高hdfs删文件效率----hadoop删除文件流程解析
- Hadoop (HDFS)分布式文件系统基本操作
- Hadoop (HDFS)分布式文件系统基本操作 推荐
- Hadoop Hdfs 配置 挂载hdfs文件系统
- 用FUSE挂载hadoop的hdfs文件系统
- zencart v150 文件调用流程(index.php分析)