hashMap的实现原理
2015-03-09 10:33
197 查看
面试的时候经常被问到hashmap的实现,故根据源码,以及网上的一些资料整理了以下笔记,以便以后查阅,如有不正确之处,还请各位多多指教。
我们知道数组存储空间连续,占用内存严重,而且空间复杂度大,它查找速度快,但是插入和删除慢,而链表存储空间离散,占用内存宽松,空间复杂度小,时间复杂度大,查找慢,但是插入和删除快。
根据数组和链表的特点,我们结合这两者的优点,所以产生了hash table,下图是hash table的结构
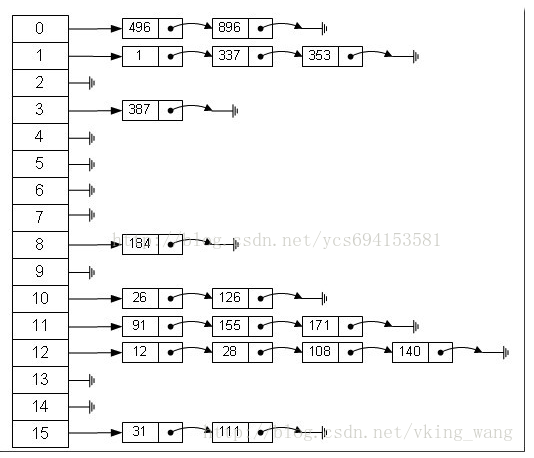
上图引用http://blog.csdn.net/vking_wang/article/details/14166593
初始化
当我们new 一个hashMap时,会创建一个Entry[],Entry 里存储的数据是一个链表结构,里面有四个变量,int hash,Entry next,Object key,Object value; hash是哈希值,next为指向下一个Entry,key和value则是键值对。
向hashMap里put数据
put(key,value)时,根据hash(key),算出hash值,用该hash值与Entry[]的长度取模,得到一个值index,这个index则为存放数据的下标地址,既Entry的某个下标。
根据hash值,如果发现key有相同的值,则新值会取代旧值,并返回旧值(public Object put(key,value);如果key不重复,则根据index值找到对应的Entry,把旧的Entry作为新Entry的next。
以下是部分源码:
向hashMap里get数据
原理和向hashMap数据类似
我们知道数组存储空间连续,占用内存严重,而且空间复杂度大,它查找速度快,但是插入和删除慢,而链表存储空间离散,占用内存宽松,空间复杂度小,时间复杂度大,查找慢,但是插入和删除快。
根据数组和链表的特点,我们结合这两者的优点,所以产生了hash table,下图是hash table的结构
上图引用http://blog.csdn.net/vking_wang/article/details/14166593
初始化
当我们new 一个hashMap时,会创建一个Entry[],Entry 里存储的数据是一个链表结构,里面有四个变量,int hash,Entry next,Object key,Object value; hash是哈希值,next为指向下一个Entry,key和value则是键值对。
向hashMap里put数据
put(key,value)时,根据hash(key),算出hash值,用该hash值与Entry[]的长度取模,得到一个值index,这个index则为存放数据的下标地址,既Entry的某个下标。
根据hash值,如果发现key有相同的值,则新值会取代旧值,并返回旧值(public Object put(key,value);如果key不重复,则根据index值找到对应的Entry,把旧的Entry作为新Entry的next。
以下是部分源码:
public Object put(Object obj, Object obj1)
{
if(obj == null)
return putForNullKey(obj1);
int i = hash(obj);
int j = indexFor(i, table.length);
for(Entry entry = table[j]; entry != null; entry = entry.next)
{
Object obj2;
if(entry.hash == i && ((obj2 = entry.key) == obj || obj.equals(obj2)))
{
Object obj3 = entry.value;
entry.value = obj1;
entry.recordAccess(this);
return obj3;
}
}
modCount++;
addEntry(i, obj, obj1, j);
return null;
}
void addEntry(int i, Object obj, Object obj1, int j)
{
if(size >= threshold && null != table[j])
{
resize(2 * table.length);
i = null == obj ? 0 : hash(obj);
j = indexFor(i, table.length);
}
createEntry(i, obj, obj1, j);
}
void createEntry(int i, Object obj, Object obj1, int j)
{
Entry entry = table[j];
table[j] = new Entry(i, obj, obj1, entry);
size++;
}
Entry(int i, Object obj, Object obj1, Entry
4000
entry)
{
value = obj1;
next = entry;
key = obj;
hash = i;
}向hashMap里get数据
原理和向hashMap数据类似
public Object get(Object obj)
{
if(obj == null)
{
return getForNullKey();
} else
{
Entry entry = getEntry(obj);
return null != entry ? entry.getValue() : null;
}
}
private Object getForNullKey()
{
if(size == 0)
return null;
for(Entry entry = table[0]; entry != null; entry = entry.next)
if(entry.key == null)
return entry.value;
return null;
}
final Entry getEntry(Object obj)
{
if(size == 0)
return null;
int i = obj != null ? hash(obj) : 0;
for(Entry entry = table[indexFor(i, table.length)]; entry != null; entry = entry.next)
{
Object obj1;
if(entry.hash == i && ((obj1 = entry.key) == obj || obj != null && obj.equals(obj1)))
return entry;
}
return null;
}

相关文章推荐
- HashMap的实现原理
- Java HashMap实现原理
- HashMap的实现原理
- HashMap的实现原理
- Hashmap实现原理
- java集合框架学习—HashMap的实现原理
- 深入Java集合学习系列:HashMap的实现原理
- hash算法 (hashmap 实现原理)
- 深入Java集合学习系列:HashMap的实现原理
- Java集合框架解析:HashMap的实现原理
- Java集合----HashMap的实现原理
- 深入Java集合学习系列:HashMap的实现原理
- HashMap的实现原理
- 深入Java集合学习系列:HashMap的实现原理
- (转)java学习:HashMap的实现原理
- 深入Java集合学习系列:HashMap的实现原理
- hashMap的实现原理
- Hashmap实现原理
- 深入Java集合学习系列:HashMap的实现原理
- Hashmap实现原理