伪分布式hadoop安装的几个问题
2015-03-08 22:54
246 查看
关于伪分布式hadoop安装的几个问题
1. 关于单机模式,伪分布式和分布式的区别
1. 单机模式:单机模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统。因此一般用来编写程序,测试程序正误。 2. 伪分布式:伪分布模式也是在一台单机上运行,具有模拟的分布式文件系,但用不同的Java进程模仿分布式运行中的各类结点(NameNode,DataNode,JobTracker,TaskTracker,SecondaryNameNode) 3. 分布式:顾名思义,就是在机器集群上进行真正的分布式文件处理
2. 安装hadoop
建议最好是在Linux系统下安装hadoop,当然也可以在虚拟机下安装。因为我也是新手,我的是安装ubuntu14.04下安装的,所以后面的文章大多是基于这个系统下的。 安装hadoop,这样的文章网络上有很多,而且江的很是详细,这里就不再赘述了。下面提几个我在安装hadoop为分布式过程的中遇到的几个问题和解决办法 1. 权限问题 为了便于进行hadoop开发,以及管理权限问题。所以首先创建专门作为hadoop开发的用户,并赋予其root权限。将下载下来的hadoo安装包安装在/usr/local/目录下,并且文件的所有权赋予hadoop用户。命令chown -R hadoop hadoop-1.2.1,chgrp -R hadoop hadoop-1.2.1. 2. 配置ssh免登陆 同样网上有很多教程,这里就不再赘述。
3. 修改配置文件
在单机模式下的Hadoop无需配置,在这种方式下,Hadoop被认为是一个单独的Java进程,这种方式经常用来调试程序。 伪分布式需要对hadoop进行一些配置。事实上,可以把伪分布式的hadoop当做是自由一个节点群组,在这个群组中,你的电脑即作为主节点,也是分节点,即是namenode,也是datanode,即是JobTracker,也是TaskTracker。伪分布式的配置过程很简单,只需要修改几个文件。在hadoop安装目中的conf文件夹中分别修改core-site.xml,hdfs-site.xml,mapred-site.xml三个文件即可。具体内容修改网上有很多文章,这里不再赘述。
4. 安装完成
在修改完配置文件后,hadoop安装就已经完成了。接下来只要对namenode进行格式化之后就可以启动hadoop了。 格式化namenode命令:[hadoop安装目录]/bin/hadoop namenode -format 接下来输入指令:start-all.sh就可以启动hadoop了。
5. 检查hadoop是否启动成功
有两中方式:
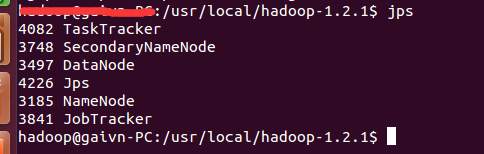
1. 使用jps指令查看:jps指令是显示当前所有java进程pid的命令,如果安装成功会有如下显示:
2. 通过浏览器查看,在浏览器地址栏分别数输入:http://localhost:50070,
http://localhost:50030可以看到如下结果:
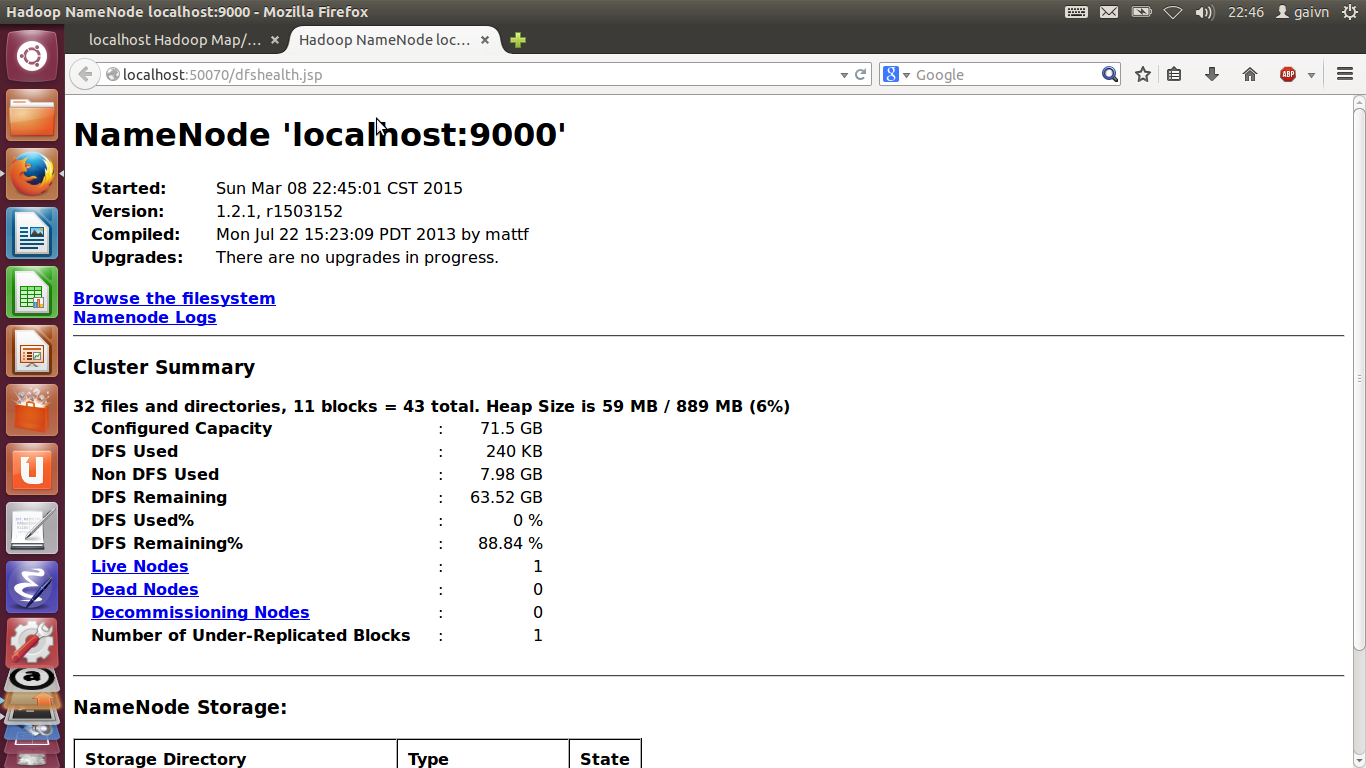
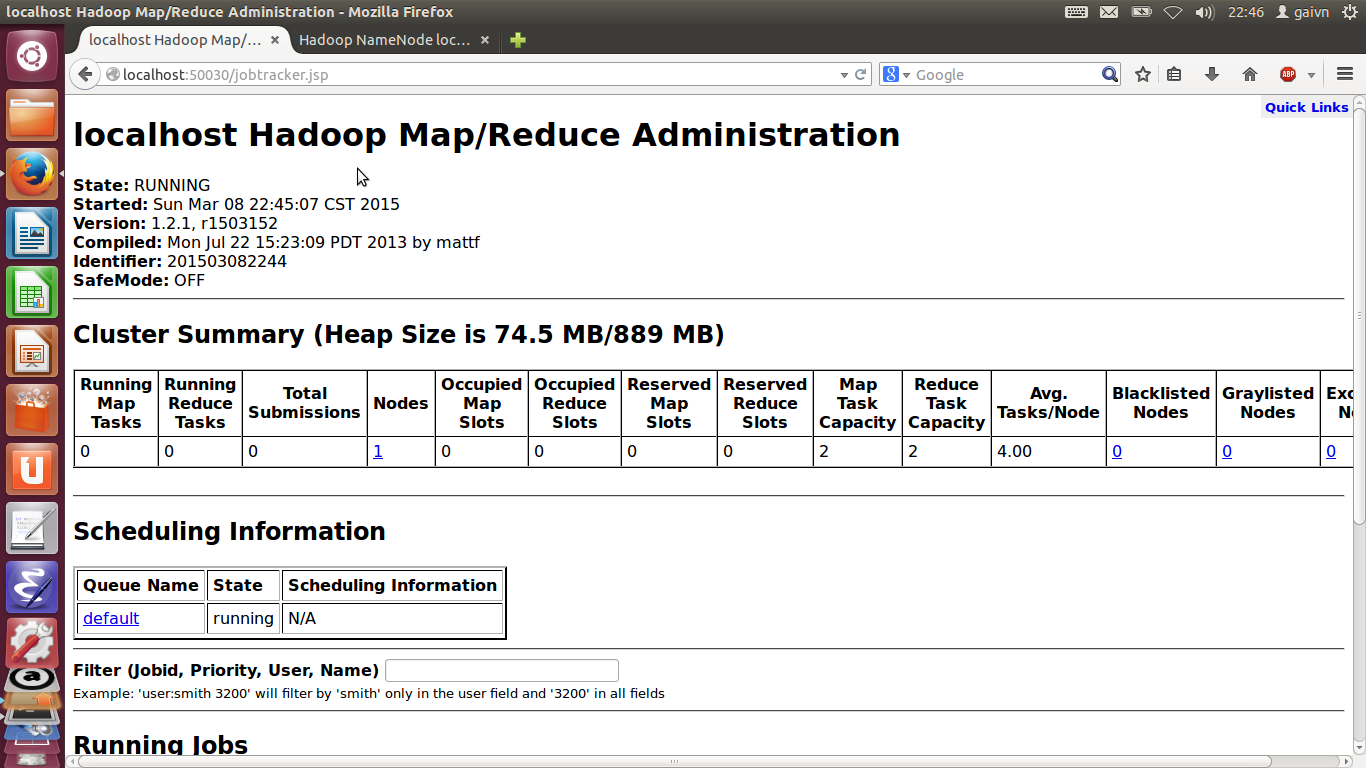
这样到此为为止,我们的hadoop就安装好了。

相关文章推荐
- Windows使用cygwin安装Hadoop-0.20.2的伪分布式模式常见问题
- ubuntu中安装伪分布式Hadoop问题总结
- ubuntu上搭建eclipse下hadoop-2.7.1集群(全分布式)开发环境遇到的几个问题笔记
- 安装Hadoop过程中遇到的几个问题
- 分布式Hadoop安装入门(5)——问题汇总
- Hadoop 2.6 single node cluster安装中的几个问题
- 在Windows下安装Hadoop遇到的几个问题
- [总结]关于数据库安装中的几个问题
- USBTO232的几个问题,乱码,回车无效,驱动安装
- 安装集群的时候遇到的几个问题
- Oracle Database Vault安装过程中遇到的几个问题及解决
- Hadoop 安装的几个关键点
- Win7+SSRS2008安装及配置时容易遇到的几个问题
- UNIX上安装ORACLE碰见的几个问题
- 关于SAP安装过程中的几个问题的TCODE
- 关于SAP安装过程中的几个问题的TCODE
- Windows7 安装VS2008RTM中文版遇到几个问题
- sharepoint安装中的几个问题
- ArcGIS Server安装的几个问题
- 关于SAP安装过程中的几个问题的TCODE