caffe笔记之例程学习(三)
2015-02-26 19:51
337 查看
原文链接:caffe.berkeleyvision.org/tutorial/layers.html
创建caffe模型,首先要在protocol buffer 定义文件(prototxt)中定义结构。
在caffe环境中,图像的明显特征是其空间结构。

Documents:注意维度变化与参数选择
example:
池化: 概述
在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做面临计算量的挑战。例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) * (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 892 * 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在 另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平 均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。
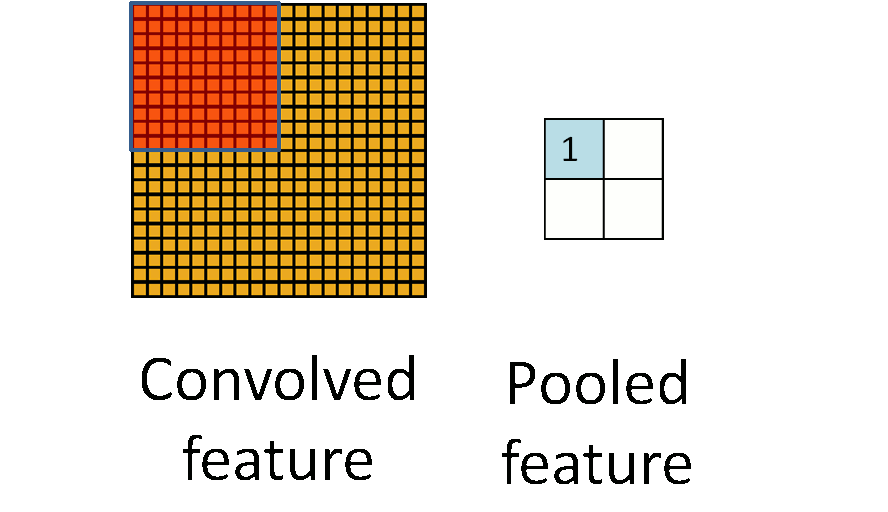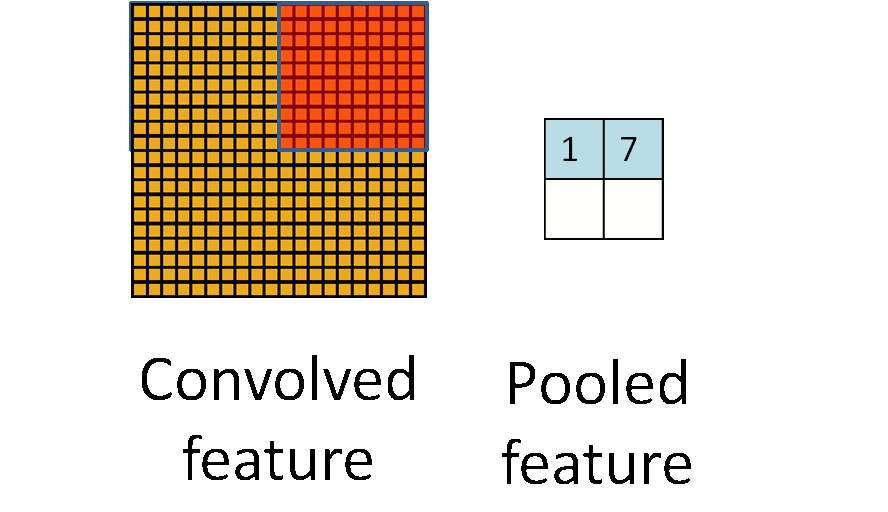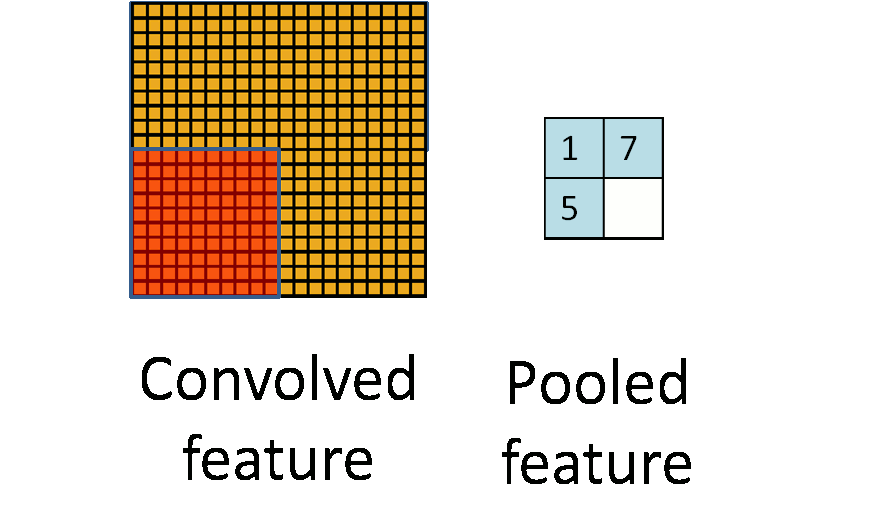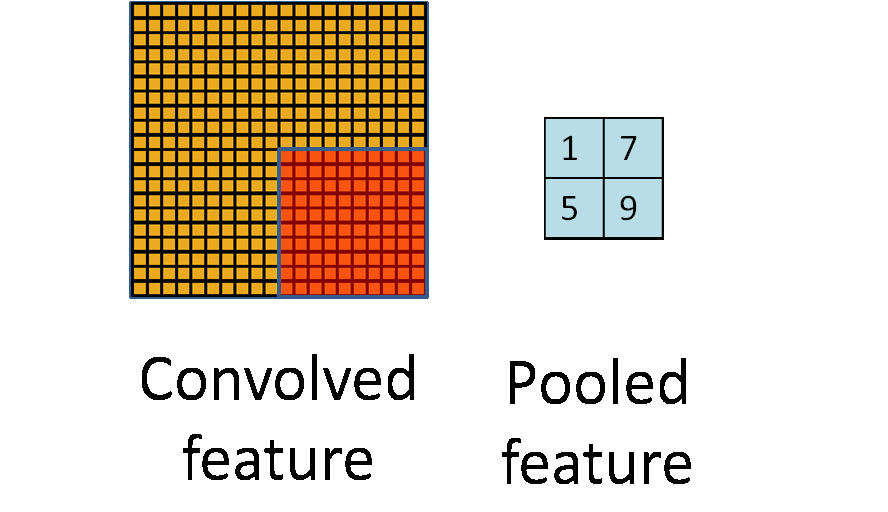
参数解释:
示例:
创建caffe模型,首先要在protocol buffer 定义文件(prototxt)中定义结构。
在caffe环境中,图像的明显特征是其空间结构。
| 主要layers | 主要功能 | 主要类型 | 其他 |
| 卷积层 | 提取特征 | CONVOLUTION | 学习率、数据维度 |
| 池化层 | 特征池化 | POOLING | 池化方法,数据维度 |
| 局部响应归一化层 | 临近抑制 | LRN | |
| 损失计算层 | loss计算 | SOFTMAX_LOSS EUCLIDEAN_LOSS HINGE_LOSS ACCURACY正确率 | 选择合适的loss 范数可选 |
| 激励层 | 非线性函数 | ReLU SIGMOID TANH ABSVAL POWER BNLL | ReLU收敛更快 |
| 数据层 | 数据源 | Level-DB LMDB HDF5_DATA HDF5_OUTPUT IMAGE_DATA | Level-DB和LMDB更加高效 |
| 一般层 | INNER_PRODUCT 全连接层 SPLIT FLATTEN 类似shape方法 CONCAT ARGMAX MVN |
一、卷积层 Convolution:
Documents:注意维度变化与参数选择
Parameters (ConvolutionParameter convolution_param) Required num_output (c_o): 输出数(filter数) kernel_size (or kernel_h and kernel_w): 指定卷积核 Strongly Recommended weight_filler [default type: 'constant' value: 0] Optional bias_term [default true]: 指定是否提供偏置10 pad (or pad_h and pad_w) [default 0]: 指定输入图片的两侧像素填充量 stride (or stride_h and stride_w) [default 1]: 过滤器步长 group (g) [default 1]: 如果 g > 1, 我们限制每一个filter之间的连通性 对于输入的子集. 指定输入和输出被分为 g 组,第i输出组只会和第i输入组相连接. Input n * c_i * h_i * w_i Output n * c_o * h_o * w_o, where h_o = (h_i + 2 * pad_h - kernel_h) / stride_h + 1 and w_o likewise.
example:
layers {
name: "conv1"
type: CONVOLUTION
bottom: "data"
top: "conv1"
blobs_lr: 1 # learning rate multiplier for the filters
blobs_lr: 2 # learning rate multiplier for the biases
weight_decay: 1 # weight decay multiplier for the filters
weight_decay: 0 # weight decay multiplier for the biases
convolution_param {
num_output: 96 # learn 96 filters
kernel_size: 11 # each filter is 11x11
stride: 4 # step 4 pixels between each filter application
weight_filler {
type: "gaussian" # initialize the filters from a Gaussian
std: 0.01 # distribution with stdev 0.01 (default mean: 0)
}
bias_filler {
type: "constant" # initialize the biases to zero (0)
value: 0
}
}
}二、池化层 Pooling:
参考链接 deeplearning.stanford.edu/wiki/index.php/池化池化: 概述
在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做面临计算量的挑战。例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) * (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 892 * 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在 另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平 均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。
参数解释:
Required kernel_size (or kernel_h and kernel_w):池化核 Optional pool [default MAX]:指定池化方法. MAX, AVE, or STOCHASTIC(按照概率值大小随机选择,数值大的被选中的概率大) pad (or pad_h and pad_w) [default 0]: 指定输入图片的两侧像素填充量 stride (or stride_h and stride_w) [default 1]:过滤器步长 Input n * c * h_i * w_i Output n * c * h_o * w_o,where h_o = (h_i + 2 * pad_h - kernel_h) / stride_h + 1 and w_o likewise..
示例:
layers {
name: "pool1"
type: POOLING
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3 # 3*3 区域池化
stride: 2 # (in the bottom blob) between pooling regions
}
}

相关文章推荐
- caffe笔记之例程学习
- 深度学习框架Caffe学习笔记(2)-MNIST手写数字识别例程
- caffe笔记之例程学习(二)
- 深度学习框架Caffe学习笔记(7)-cifar10例程
- 深度学习框架Caffe学习笔记(3)-MNIST例程深入
- 基础学习笔记之opencv(16):grabcut使用例程
- Delphi 2010学习笔记(20)---例程的定义与使用---2011-01-26
- halcon例程学习笔记(2)----check_smd_tilt.hdev
- Delphi 2010学习笔记(17)---程序终止例程---2011-01-21
- caffe 学习笔记(一)
- halcon例程学习笔记(7)---检测漏焊board.hdev
- contiki学习笔记——cc2530dk例程实践和UDP重启问题解决
- Java学习笔记2:理解运行例程
- openFrameworks 学习笔记(一): 简单例程分析
- [笔记2.1]学习AFEPack的例程
- 学习笔记:Caffe上LeNet模型理解
- OpenCV学习笔记一 例程
- OpenCV学习笔记: 快速入门例程
- OpenCV学习笔记: 快速入门例程
- halcon例程学习笔记(5)----halcon中如何自己创建子过程