7 Support vector machine(2)
2015-02-11 08:03
351 查看
本学习笔记参考自Andrew的机器学习课程(点此打开),
内容来自视频以及其讲义, 部分内容引用网友的学习笔记,会特别注明
本集内容
1.最优间隔分类器2.原始优化、对偶优化
3.KTT条件
4.SVM dual
5.核方法(kernels)
最优间隔分类器
上一节里面介绍了函数间隔,几何间隔,我们知道要想获得一个好的模型,必须使这些间隔最大化,我们用如下定义最优间隔分类器: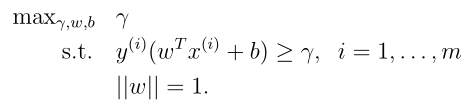
这里是选的 最优化的目标是几何间隔,并且满足||w|| = 1,且该几何间隔是所有样本中最小的,这里||w|| = 1也是满足了几何间隔等于函数间隔。现在我们的目标就是根据这个最优问题求解出w, b。但事实上这个最优模型并不容易求的一个全局最优解,所以需要对该模型做一些变换以便于我们求出w,b使得目标函数达到一个全局最优。为了理解接下来的一系列模型变换,需要了解一点点凸优化问题的知识。
凸集
一个集合C是凸集,当任意的 x,y ∈ C ,且θ ∈ R 并满足 0 ≤ θ ≤ 1,有θx + (1 − θ)y ∈ C。直观的看就是在集合C里面挑两个元素,如果两个元素的连线上所有点都在C里面,那么C就是凸集。可以看到上面定义的最优间隔分类器模型的一个约束条件是||w||
= 1,并不是凸集。可以想象如果w是二维的,那么||w|| = 1所在的区域则是二维图上的一个圆环,任意选两个点连接起来,中间的点并不在圆上,所以不是凸集
凸函数
一个函数f是凸函数,当它的定义域(记作D(f))是凸集,且对所有的 x,y ∈ D(f), θ ∈ R, 0 ≤ θ ≤ 1,有如下:f(θx + (1 − θ)y) ≤ θf(x) + (1 − θ)f(y)
直观的看,就是在f上选两个点,两个点的连线在函数f的上面
凸优问题
一个凸优问题描述如下:1.目标函数(最大或最小):f(x)
2.x ∈ C
其中目标函数是凸函数,C是凸集,x是最优变量
也就是凸优化是指目标函数为凸函数且由约束条件得到的定义域为凸集的优化问题,这类问题可以有一套非常完备的求解算法,能够快速的给出全局最优解,我们要做的是尽量把最优问题转换为凸优化问题,计算该凸优问题可以直接交给一些软件去做即可。所以我们尽可能的把最优间隔分类器往这上面转换,继续回到最优间隔分类器
我们将这个模型稍微改变一下,去掉那个非凸集的约束:

这个时候目标函数仍然是几何间隔,因为γ = ˆ γ/||w|,但是这个目标函数并不是凸函数,所以得继续改。我们在前面介绍过,缩放w,b任意倍,几何间隔不会改变,所以我们总是可以缩放一定倍数的w, b使得函数间隔等于1,即ˆ γ = 1,但是缩放过程中,我们的目标函数——几何间隔不会发生任何变化,也就是现在目标函数可以改变为1/||w||,要最大化1/||w||等效于最小化||w||^2,这样就得到凸二次函数了,可以用一些商业化的代码去计算,所以最终的最优间隔分类器可以形式化如下:
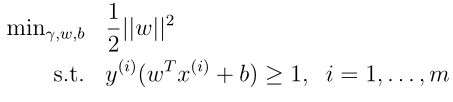
拉格朗日对偶(Lagrange duality )
拉格朗日乘数法
这里先引出如下问题: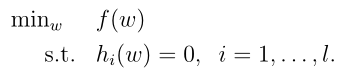
这类问题,可以看做是在满足某些等式条件下求函数最值或极值的问题,在同济版高等数学下册介绍过拉格朗日乘数法,定义拉格朗日函数如下:
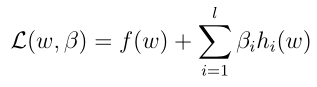
其中 β是拉格朗日乘数,这里L(w,β)是等于f(w)的,要求解出目标最优值,需要分别对参数求偏导,并分别令其等于0得到方程组来解出参数:
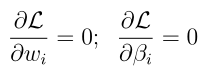
广义的拉格朗日
将上面的优化问题扩展为不止等式约束的情况,如下,这个问题也称原始优化问题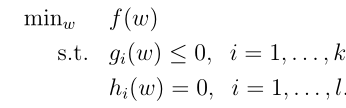
广义的拉格朗日函数定义为:
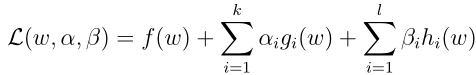
α i , β i是拉格朗日乘数,注意这里的L(w,α,β) != f(w),继续构造如下:
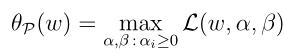
其中P是指primal,即原始的。我们看一下这个函数的性质,注意在等式的右边是给定w,调整α,β使得 L(w,α,β)最大,等式左边则是以w为自变量的函数(这里和下面要介绍的对偶有一点不一样)。如果w并不满足gi(w)<=0,或者并不满足hi(w)
=0, 那么
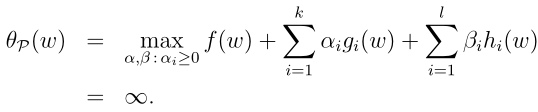
因为我们总可以选择α i ,β i 使得θ P (w)为∞。如果w满足约束条件,即gi(w) <=0,即L(w,α,β) 最大的取值就是f(w),所以该函数可以写成如下:
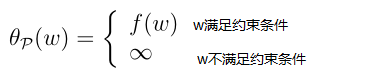
这样我们的原始问题的解也就等价于下面的最优化问题的解:
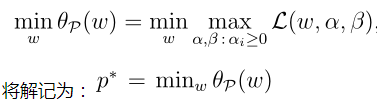
P*表示的是L(w,α,β) 先调整α,β获得其关于w最大值的表达式(这个最大值的表达式等于f(w)),然后调整w,获得最大值表达式中的最小值。下面看另一个问题,待会儿会与之原始优化问题关联起来。
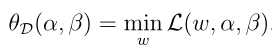
D表示对偶,注意等式的右边是固定α,β,调整w来获得L(w,α,β)的最小值,等式的左边是关于α,β的函数,同样的,下面看对偶优化问题:
那么d*表示的是在固定α,β找出L(w,α,β)关于α,β最小值的表达式,然后调整α,β求出该表达式的最大值,可以看做是求的最小值中的最大值,而原始优化问题求解的是最大值中的最小值,所以明显有:
某些条件下,d* = p*,这样我们就可以用对偶优化去替代原始优化,因为常常对偶优化更简单一些,下面说明等号成立的条件:
1. f是凸函数
2. gi 是凸函数
3. hi 是仿射函数,仿射函数即由1阶多项式构成的函数,一般形式为
f (x) = A x + b,这里,A 是一个 m×k 矩阵,x 是一个 k 向量,b是一个m向量,实际上反映了一种从 k 维到 m 维的空间映射关系。
4. 存在w 使得 g i (w) < 0 对于所有 i成立
这些条件全部成立的话,就一定能够找到 w ∗ ,α ∗ ,β ∗ ,使得 p ∗ = d ∗ = L(w ∗ ,α ∗ ,β ∗ )。并且这时 w
∗ ,α ∗ ,β ∗ 满足库恩-塔克条件 (Karush-Kuhn-Tucker, KKT condition) ,KKT条件入下:

并且如果w ∗ ,α ∗ ,β ∗ 满足KKT条件,则也是原始问题和对偶问题的解。KKT条件中的α
∗ i g i (w ∗ ) = 0被称为互补条件,可以看到如果α ∗ i>0(这里*是α上标,i是α下标),则g i (w ∗ ) = 0,表示极值会在约束条件的边界上面取到。在实际情况中,也常常是α
∗ i>0,g i (w ∗ ) = 0,这是g i称作一个活动约束
回到最优间隔分类器
我们之前推导出来的最优间隔分类器如下,并且已经可以交给一些软件直接计算出最优参数,现在考虑用上面讲的对偶优化重新来求解这个最优间隔分类器(注意这里假设所有样本是线性可分的!):
根据这个最优问题,然后结合上面讲的一般化的拉格朗日,从约束出发,有
现在的问题是原始优化问题,下面的思路都是通过KKT条件,将原始问题的求解转换到对偶优化问题上。考虑KKT条件中的互补条件,即α i*gi(w) = 0,也就是要满足KKT,至少α i或gi(w)为0,当gi(w)
= 0时,对应样本的函数间隔为1,可以认为这些样本的α i >0,且其他样本的gi(w) <0,α i = 0。函数间隔为1的样本是所有样本函数间隔最小的,对应的其几何间隔也是最小的,因为它们是正比关系。在图中表现出来如下:
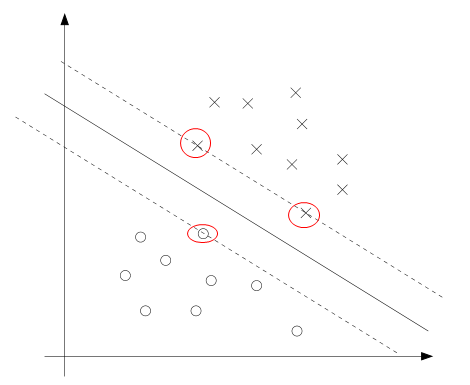
画圈的样本表示距离超平面最近的样本点,也就是它们的函数间隔为1,这些样本点被称为支持向量,并且可以看到支持向量比所有样本数量小很多。
现在我们的一般拉格朗日可以写成如下:

我们的对偶优化问题如下,当然现在讨论的问题不存在β,公式里面的w包含现在的w, b两个参数
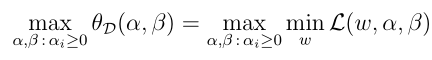
先来求
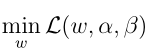
这部分。即需要L(w,b,α)对w,
b求偏导,并令其为0,得到:
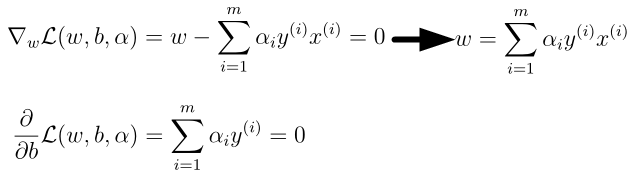
我们将上面求解出来的式子带入L(w,b,α),这里带入过程是比较繁琐的推导,推导内容来自JerryLead的学习笔记,这里引用一下:
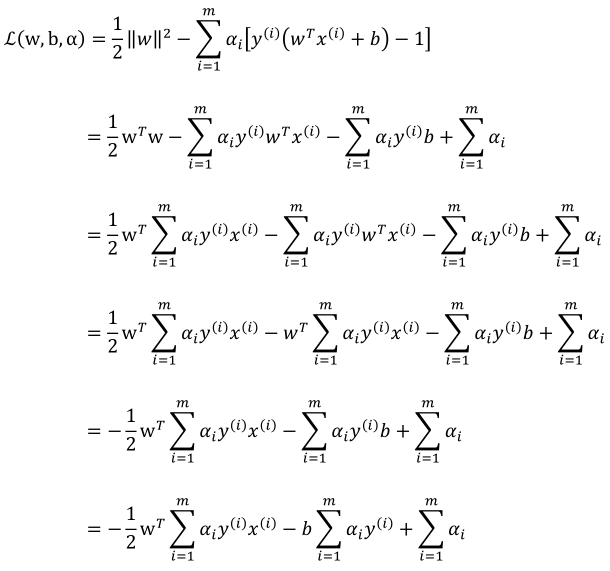
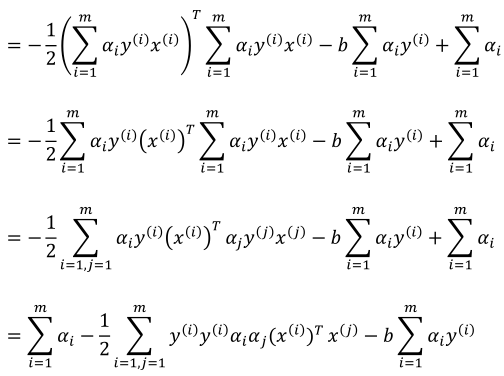
注意最后一项等于0的,所以最后的式子如下:
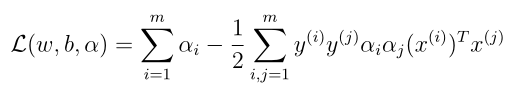
接下来是考虑对偶优化中
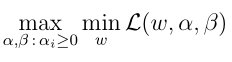
的第二步,maxL(w,b,α),即
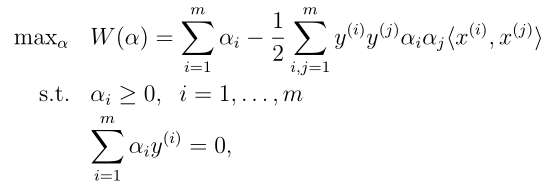
注意表达式中的
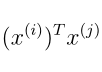
内积现在换了一种写法
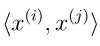
,。现在该对偶优化问题的解与原始问题解等价,因为满足那几个条件:1.目标函数是凸函数
2.约束函数是凸函数 3.存在w,对所有i,使gi(w)<0。对于该优化问题,加入求出了α(后面会讲方法),我们可以用
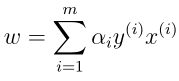
来求解w,并且可以得到:
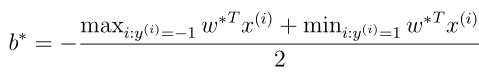
现在假设我们已经求到了参数,对于一个新的样本,我们进行预测,首先要计算如下:
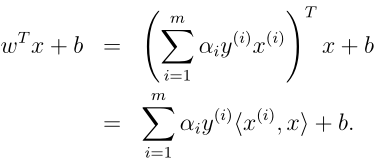
这里我们需要计算内积,但是在前面讨论过,只有支持向量的αi > 0,而支持向量的点是很少的,所以需要计算的内积的样本点也是比较少的。而且在推导计算过程中,每一步有αi乘以内积的形式都会有这样的优点,不需要计算出每一个内积向量(仍然注意这里所讨论的优化都是假设所有样本是线性可分的!)

相关文章推荐
- 机器学习技法课程学习笔记1 -- Linear Support Vector Machine
- 可支持向量机SVM(support vector machine)基础
- [DL]机器学习算法之支持向量机(Support Vector Machine)
- 机器学习技法-01-4-Support Vector Machine
- 林轩田之机器学习课程笔记( embedding numerous feature之 soft-margin support vector machine)(32之20)
- [Machine Learning] SVM--support vector machine
- R语言高级算法之支持向量机(Support Vector Machine)
- 机器学习:支持向量机(Support Vector Machine, SVM)
- 机器学习实战(5)--SVM(Support vector machine)(六)--Python实现
- Support Vector Machine 组会报告
- 支持向量机 Support Vector Machine 概念
- pDHS-SVM:A prediction method for plant DNase I hypersensitive sites based on support vector machine
- 【Linear Support Vector Machine】林轩田机器学习技法
- 支持向量机(Support Vector machine)--libSvm中自定义核的扩展
- 支持向量机(support vector machine)--模型的由来
- Matlab: Support Vector Machine (SVM 支持向量机)
- 机器学习技法课程学习笔记2 -- Dual Support Vector Machine
- 机器学习技法-Linear Support Vector Machine
- SVM (support vector machine)
- 机器学习笔记 - Hard-Margin Support Vector Machine