润乾集算报表优化应用结构之中间数据外置
2015-01-30 14:17
302 查看
绝大多数报表项目的数据库中,除了支撑系统运行的业务数据表之外,还有很多中间表。业务数据表是报表系统必须的基础数据表,是支持报表系统运行的持久化数据层,例如:销售报表系统中的订单、客户、产品等等。报表中间表则是计算和生成报表的中间计算过程,中间表的名字经常是五花八门。按道理说,业务数据表应该是大部分,报表中间表只是小部分。但是,实际情况却恰恰相反。有些运行了较长时间的报表系统中,报表中间表达到几千个或者更多,而业务数据表只有一两百。关系型数据库的综合成本是和数据表的数量、数据量相关的。数据库中存放较多的报表中间表会存在下面的问题:1、 表越多,数据量越大,数据库的负载压力越大,会造成性能的下降。2、 数据库压力达到一定程度就必须扩容,项目成本会增加不少。3、 数据库是扁平结构,不能以多级目录的形式来管理数据,只适合管理数量较少的表。中间表命名随意,形成大量意义混淆的表名,可管理性变差。4、 表多、数据量大,会直接造成数据库管理和维护成本的增加。那么如何减少报表开发中的数据库内中间表呢?分库是解决数据库内中间冗余数据的办法之一,也是目前报表项目中常见的做法。但是,不管是将数据库分成多个,还是构建专门的数据仓库,本质上还是用传统关系型数据库来承载中间数据,因此,上边所说的问题依然存在。是否可以将中间数据从数据库中移出来呢?小结果集直接计算后返回,大结果集放到硬盘文件上?这样做的好处非常明显:1、降低了数据库的压力,让报表系统运行更快。2、 数据库不必因为报表中间表的原因扩容,降低了项目成本。3、 文件可以按照业务种类、模块关系、时间顺序进行多级目录管理,可管理性较高。4、 数据表少了,数据库管理和维护自然变得容易,降低了运维成本。但是,中间数据外置对于多数程序员来说,只是个美好的愿望而已。他们不是不愿意把中间表放到数据库外,而是不能放到库外。这是因为,数据一旦离开了数据库,就“失去了计算能力”。例如:某项目中有个中间表temp2009sales,是按照客户分组的2009年客户-订单数据。在数据库中,对这个表可以按照客户排序。但是一旦导出到文本文件中,文件本身是没有办法替程序员做排序的。 采用润乾集算报表,可以实现复杂计算与报表展现分离,其内置的集算引擎可以使文件拥有计算能力,实现程序员“把报表中间数据从数据库中移出来”的愿望。引入集算报表和内置集算引擎后的报表系统结构对比如下图:
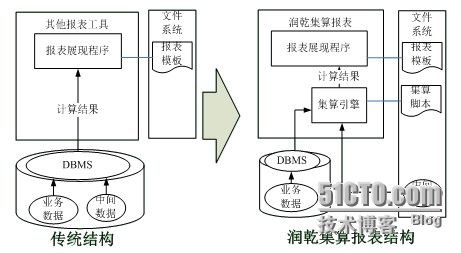
由于集算报表支持异构的数据源,上面提到的中间temp2009sales数据文件虽然已经放到了库外,但是依然可以和数据库中其他的业务表进行关联计算,用于最终生成报表。例如下图这张“某公司客户累计销售额与去年全年销售额对比报表”:

这张报表中的客户、订单数、销售额都是直接从数据库中计算的2010年1月-10月的数据。2009年全年的订单数、销售额是从文件系统中的temp2009sales.b文件中读取。“销售额/去年销售额”则是今年和去年的数据共同计算的。报表上部的查询按钮是集算报表提供的“参数模板”功能,具体做法参见教程,这里不再赘述。这里,重点看一下这个报表的开发过程。
首先,要提前用集算器从数据库中读取2009年等各个年份的销售数据,计算好之后,以集算器的二进制编码导出到temp2009sales.b文件中,每年一个文件。中间数据制作好之后,数据库中2009年的数据就可以移除备份了,不再占用数据库的空间。
第二,编写集算器脚本salesProportion.dfx如下:
注意,脚本的参数是:argyear(要查询的年份),argmonth(要查询的月份)。

A1:连接预先配置好的数据源demo。
A2:从数据库中计算取出要查询的年份订单数、销售额。
A3:从前一年的数据文件中取出数据。
A4:将A3中的数据按照A2中的CLIENT字段对齐,A2中有A3中没有的补空行。
A5:利用A2来生成新的续表。其中增加了A4的对应行数据,比如A4(#).C:lastCOUNT就是A4的对应行(#是A2的当前行号)中取出C字段。
A6:关闭数据库连接。
A7:向报表返回结果集。
第三,在集算报表中定义报表参数(argyear、argmonth)和计算数据集:

上图中,参数名是指dfx定义的参数名称,参数值是指报表提交给集算引擎的值。这里是将报表的两个参数的值传递给集算器的同名参数。
第四,设计报表,如下图:

输入参数计算后,即可得到前面希望的报表。
由于集算报表支持异构的数据源,上面提到的中间temp2009sales数据文件虽然已经放到了库外,但是依然可以和数据库中其他的业务表进行关联计算,用于最终生成报表。例如下图这张“某公司客户累计销售额与去年全年销售额对比报表”:
这张报表中的客户、订单数、销售额都是直接从数据库中计算的2010年1月-10月的数据。2009年全年的订单数、销售额是从文件系统中的temp2009sales.b文件中读取。“销售额/去年销售额”则是今年和去年的数据共同计算的。报表上部的查询按钮是集算报表提供的“参数模板”功能,具体做法参见教程,这里不再赘述。这里,重点看一下这个报表的开发过程。
首先,要提前用集算器从数据库中读取2009年等各个年份的销售数据,计算好之后,以集算器的二进制编码导出到temp2009sales.b文件中,每年一个文件。中间数据制作好之后,数据库中2009年的数据就可以移除备份了,不再占用数据库的空间。
第二,编写集算器脚本salesProportion.dfx如下:
注意,脚本的参数是:argyear(要查询的年份),argmonth(要查询的月份)。
A1:连接预先配置好的数据源demo。
A2:从数据库中计算取出要查询的年份订单数、销售额。
A3:从前一年的数据文件中取出数据。
A4:将A3中的数据按照A2中的CLIENT字段对齐,A2中有A3中没有的补空行。
A5:利用A2来生成新的续表。其中增加了A4的对应行数据,比如A4(#).C:lastCOUNT就是A4的对应行(#是A2的当前行号)中取出C字段。
A6:关闭数据库连接。
A7:向报表返回结果集。
第三,在集算报表中定义报表参数(argyear、argmonth)和计算数据集:
上图中,参数名是指dfx定义的参数名称,参数值是指报表提交给集算引擎的值。这里是将报表的两个参数的值传递给集算器的同名参数。
第四,设计报表,如下图:
输入参数计算后,即可得到前面希望的报表。

相关文章推荐
- 报表系统结构优化之中间数据外置
- 润乾集算报表优化应用结构之混合数据源
- 报表系统结构优化之中间数据外置
- 润乾集算报表优化应用结构之数据分库存储
- 润乾集算报表优化应用结构之特定报表数据源绑定
- 润乾集算报表优化应用结构之实现T+0实时报表
- 润乾集算报表优化应用结构之报表复杂数据源的管理
- 润乾集算报表优化应用结构之减少存储过程
- 润乾集算报表优化应用结构之可挂接算法
- 报表应用结构优化之数据分库存储
- 润乾集算报表优化应用结构之本地计算
- 应用高级数据结构优化Redis
- 润乾集算报表提升性能之数据外置
- VB之数据报表设计器在多层结构开发的应用---技术在更新,而思路则不变
- 润乾集算报表优化应用结构之报表数据源复用
- 润乾报表语义层数据管理批量置数之修改现有数据
- 润乾报表语义层数据管理之置空
- 润乾报表语义层数据管理之替换
- 数据结构实现顺序线性表的一些小应用
- 润乾报表语义层数据管理之数据迁移