HDU 4162 Shape Number
2015-01-27 21:39
399 查看
Description
In computer vision, a chain code is a sequence of numbers representing directions when following the contour of an object. For example, the following figure shows the contour represented by the chain code 22234446466001207560 (starting
at the upper-left corner).
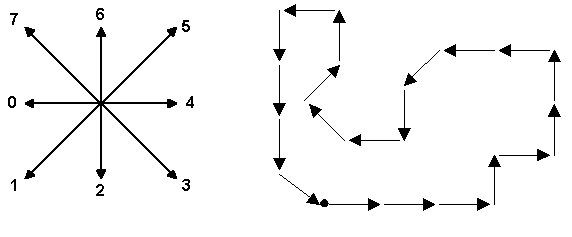
Two chain codes may represent the same shape if the shape has been rotated, or if a different starting point is chosen for the contour. To normalize the code for rotation, we can compute the first difference of the chain code instead. The first difference is
obtained by counting the number of direction changes in counterclockwise direction between consecutive elements in the chain code (the last element is consecutive with the first one). In the above code, the first difference is
00110026202011676122
Finally, to normalize for the starting point, we consider all cyclic rotations of the first difference and choose among them the lexicographically smallest such code. The resulting code is called the shape number.
00110026202011676122
01100262020116761220
11002620201167612200
...
20011002620201167612
In this case, 00110026202011676122 is the shape number of the shape above.
Input
The input consists of a number of cases. The input of each case is given in one line, consisting of a chain code of a shape. The length of the chain code is at most 300,000, and all digits in the code are between 0 and 7 inclusive.
The contour may intersect itself and needs not trace back to the starting point.
Output
For each case, print the resulting shape number after the normalizations discussed above are performed.
Sample Input
Sample Output
Source
The 2011 Rocky Mountain Regional Contest
解析
最小表示法。
题目的大概意思是给你一串数字编码,先两两相减( b[1] = a[2] – a[1],如果a[2] < a[1],那么b[1] = (a[2] + 8) – a[1] )。得到一个处理过后的编码,然后把此编码视为循环编码,输出出字典序最小的编码。例如15011的编码有15011, 50111, 01115, 11150, 11501。其中,字典序最小的编码为:01115
其维护i和j指针,分别指向(共有L(串长)个串)其中2个串(其实只有一个串,拆成2个串好理解点)的串头(注意当比较这两个串的大小的时候i和j都不动,任然指串头,而这个串头是指以该位置开始而得到的串的串头),他是通过k(因为如果不引入k,而i和j是移动的,比较完成后i和j回不了串头)来比较这两个串,即i+k和j+k就是比较这两个串时的指针……
然后,当不相等的时候,因为我们求的是最小的串,所以要移动大的指针,而小的指针不动,而这个小的指针很有可能就是我们所想要求的指针……而移动的幅度是k+1使效率大大提高……因为如果移到[大指针后.....k]中的一个的话,(为什么这么移动?因为(拿 i 来说),此时以[ i , i+k ]开头的任意串都对应一个[
j , j+k ]中开头的字符串比它字典序小,所以就可以移动到 i + k 了,同时要保证i j 指针不指向同一个字符串。)
以这个位置为开头的串也一定比小串大……注意一点,i或j指的位置都可能是想求的位置……
总之,求最小表示,就小的不变,求最大表示就大不变……
还有一点,就是始终保持i<j,因为如果i == j的话事实上就在比较同一个串……没意义,而最后返回的就是i == j时
的指针,而这个指针极小可能是想要的结果……最后为什么返回小的那个呢?因为到达该位置就不在动了……
而另外一个指针已经后移到出界了(即该指针 == len)
/article/7160392.html
这个blog讲的很好了
In computer vision, a chain code is a sequence of numbers representing directions when following the contour of an object. For example, the following figure shows the contour represented by the chain code 22234446466001207560 (starting
at the upper-left corner).
Two chain codes may represent the same shape if the shape has been rotated, or if a different starting point is chosen for the contour. To normalize the code for rotation, we can compute the first difference of the chain code instead. The first difference is
obtained by counting the number of direction changes in counterclockwise direction between consecutive elements in the chain code (the last element is consecutive with the first one). In the above code, the first difference is
00110026202011676122
Finally, to normalize for the starting point, we consider all cyclic rotations of the first difference and choose among them the lexicographically smallest such code. The resulting code is called the shape number.
00110026202011676122
01100262020116761220
11002620201167612200
...
20011002620201167612
In this case, 00110026202011676122 is the shape number of the shape above.
Input
The input consists of a number of cases. The input of each case is given in one line, consisting of a chain code of a shape. The length of the chain code is at most 300,000, and all digits in the code are between 0 and 7 inclusive.
The contour may intersect itself and needs not trace back to the starting point.
Output
For each case, print the resulting shape number after the normalizations discussed above are performed.
Sample Input
22234446466001207560 12075602223444646600
Sample Output
00110026202011676122 00110026202011676122
Source
The 2011 Rocky Mountain Regional Contest
解析
最小表示法。
题目的大概意思是给你一串数字编码,先两两相减( b[1] = a[2] – a[1],如果a[2] < a[1],那么b[1] = (a[2] + 8) – a[1] )。得到一个处理过后的编码,然后把此编码视为循环编码,输出出字典序最小的编码。例如15011的编码有15011, 50111, 01115, 11150, 11501。其中,字典序最小的编码为:01115
其维护i和j指针,分别指向(共有L(串长)个串)其中2个串(其实只有一个串,拆成2个串好理解点)的串头(注意当比较这两个串的大小的时候i和j都不动,任然指串头,而这个串头是指以该位置开始而得到的串的串头),他是通过k(因为如果不引入k,而i和j是移动的,比较完成后i和j回不了串头)来比较这两个串,即i+k和j+k就是比较这两个串时的指针……
然后,当不相等的时候,因为我们求的是最小的串,所以要移动大的指针,而小的指针不动,而这个小的指针很有可能就是我们所想要求的指针……而移动的幅度是k+1使效率大大提高……因为如果移到[大指针后.....k]中的一个的话,(为什么这么移动?因为(拿 i 来说),此时以[ i , i+k ]开头的任意串都对应一个[
j , j+k ]中开头的字符串比它字典序小,所以就可以移动到 i + k 了,同时要保证i j 指针不指向同一个字符串。)
以这个位置为开头的串也一定比小串大……注意一点,i或j指的位置都可能是想求的位置……
总之,求最小表示,就小的不变,求最大表示就大不变……
还有一点,就是始终保持i<j,因为如果i == j的话事实上就在比较同一个串……没意义,而最后返回的就是i == j时
的指针,而这个指针极小可能是想要的结果……最后为什么返回小的那个呢?因为到达该位置就不在动了……
而另外一个指针已经后移到出界了(即该指针 == len)
/article/7160392.html
这个blog讲的很好了
#include <cstdio>
#include <cstring>
using namespace std;
int b[300100],len;
char c[300100];
inline int ca(int x)
{return x<len?x:x-len;}
int minp()
{
int i=0,j=1,k=0;
while(i<len && j<len && k<len)
{
int det=b[ca(i+k)]-b[ca(j+k)];
if(det==0) k++;
else
{
if(det>0) i+=k+1; else j+=k+1;
if(i==j) j++;
k=0;
}
}
return i>j?j:i;
}
int main()
{
while(scanf("%s",c)==1)
{
len=strlen(c);c[len]=c[0];c[len+1]='\0';
for(int i=0;i<len;i++)
{
b[i]=c[i+1]-c[i];
if(c[i]>c[i+1]) b[i]+=8;
}
int k=minp();
for(int l=0;l<len;l++) printf("%d",b[ca(k+l)]); puts("");
}
}

相关文章推荐
- 【最小表示法】HDU-4162-Shape Number
- LA - 5734(hdu - 4162) - Shape Number(指针扫描+贪心)
- hdu 4162 Shape Number(最小表示法)
- HDU 4162 Shape Number 最小表示法
- HDU 4162 Shape Number
- HDU 4162 Shape Number (最小表示法)
- HDU 4162 Shape Number
- HDU 4162 Shape Number
- hdu 4162 Shape Number【循环字符串最小表示法】模板学习
- HDU 4162 Shape Number
- HDU 4162 Shape Number 最小表示法
- HDU 4162 Shape Number (模拟)
- LA - 5734(hdu - 4162) - Shape Number
- HDU 4162 Shape Number(最小表示法)
- HDU 4162 Shape Number(最小表示法)
- hdu 4162 Shape Number 最小表示法
- HDU 4162 Shape Number【字符串最小表示】
- 【HDU 4162】Shape Number(一阶差分链码+最小表示法)
- 字符串_最小表示法求循环串的最小序列(HDU_4162)
- HDOJ 4162 Shape Number(最小表示法 )