机器学习稀疏之L1正则化
2015-01-22 10:21
453 查看
一、L1正则化
在L0 正则化中,通常我们有很多特征时, 这样在计算后验形式p(r|D) 有很大的复杂度。即使利用贪心算法,很容易陷入局部拟合情况。
其中一部分原因是因为 rj 特征是离散形式的, 这样造成目标函数的不光滑,

。
在优化领域中,通常的做法是对于离散的约束,我们通过松弛的方法来将其变为连续的约束。 我们可以在spike-and-slab 尖峰与平波模型中,通过在wj =0, 的 阶跃函数 取值处来用一定大小的概率值进行代替,这样通过在wj =0 用一定值代替,来构造成为连续函数的形式,这样来接近原始模型, 比如可以用零均值的laplace 模型代替。 这里我们应用了laplace
具有的长尾,(并且这里对于异常值的鲁棒对长尾的模型是很好的,正太情况将会有很大的异常变化。)

从图中可以看出, u = 0,也存在尖峰的,这样就可以用连续的形式进行代替,从而更好的优化目标函数。
更加精确的我们利用的Laplace
模型作为先验
&space;=&space;%5Cprod%5Climits_%7Bj&space;=&space;1%7D%5ED&space;%7BLap(%7Bw_j%7D%7C0,1/%5Clambda&space;)%7D&space;%5Cpropto&space;%5Cprod%5Climits_%7Bj&space;=&space;1%7D%5ED&space;%7B%7Be%5E%7B&space;-&space;%5Clambda&space;%7C%7Bw_j%7D%7C%7D%7D%7D)
我们用均匀先验的形式在截距项
&space;%5Cpropto&space;1)
,
, 因而在MAP 估计,其带罚的负log 似然形式为:
&space;=&space;-&space;logp(D%7Cw)&space;-&space;logp(w%7C%5Clambda&space;)&space;=&space;NLL(w)&space;+&space;%5Clambda&space;%7C%7Cw%7C%7B%7C_1%7D)
其中

为
w 的L1模, 利用合适的
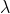
, 可得到稀疏的

,
这里 我们认为 LI 正则是L0 非凸函数的 凸近似, 因为 L0 的模值 是0 ,wi, wj , ... 0 ... 每个是离散的, 而L1 模 是 |wj| 的加和, 因而是连续的一个值的过程,因而是凸近似。
所以在 线性回归中 L1 目标函数:
&space;&&space;=&space;%5Csum%5Climits_%7Bi&space;=&space;1%7D%5EN&space;%7B&space;-&space;%5Cfrac%7B1%7D%7B%7B2%7B%5Csigma&space;%5E2%7D%7D%7D%7B%7B(%7By_i%7D&space;-&space;(%7Bw_0%7D&space;+&space;%7Bw%5ET%7D%7Bx_i%7D))%7D%5E2%7D%7D&space;+&space;%5Clambda&space;%7C%7Cw%7C%7B%7C_1%7D%5C%5C&space;&&space;=&space;RSS(w)+&space;%7B%5Clambda&space;'%7D%7C%7Cw%7C%7B%7C_1%7D%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;where%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Clambda&space;'%7D&space;=&space;2%5Clambda&space;%7B%5Csigma&space;%5E2%7D&space;%5Cend%7Balign*%7D)
通常 用 0均值Laplace 先验参数, 这样的MAP估计就是L1正则,存在着 凸的和非凸的NLL项, 有很多算法设计解决这个问题(这个以后讨论)。
二、 为什么 L1 正则产生的是稀疏解
我们现在来说说 L1 产生的是稀疏解, 而L2 不是。我们主要以线性回归为例说明,这个在 逻辑回归和 其他GLMs 中是相似的。
虽然L1 是连续的,但是 还是不光滑的函数, 所以不光滑的目标函数为:
&space;+&space;%5Clambda&space;%7C%7Cw%7C%7B%7C_1%7D)
我们将其进行改写, 将后面的作为约束,但是变为光滑的目标函数: (二次函数 约束是线性的)
%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;s.t.%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7C%7Cw%7C%7B%7C_1%7D&space;%5Cle&space;B)
B是 w 的L1 模的上界, 小的 B 对应的是
大的罚项。
上式的光滑加约束的形式 ,就是 LASSO, 表示 “least absolute shrinkage and selection operator”, 最小绝对值收缩及选择算子。
同样对于 ridge regression L2 正则, 也可进行约束改写:
&space;+&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%5Clambda&space;%7C%7Cw%7C%7C_%7B_2%7D%5E2%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%5Cleftrightarrow&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%5Cmathop&space;%7B%5Cmin&space;%7D%5Climits_w&space;RSS(w)%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;s.t.%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7C%7Cw%7C%7C_%7B_2%7D%5E2&space;%5Cle&space;B)
。
通过图形来直观的解释:

我们首先画出RSS 目标函数的轮廓线, 和 L1 、 L2 的约束边界线。 根据优化原理, 最优解点存在在图中阶数最小处的点,即 顶点处, 因而LI 是四个角点, L2 整个圆周处。 对于L1约束范围 进行扩张,
这时角点更容易接触到目标函数,尤其在高维的情况下, 角点是突出的,角点对应的是稀疏解。 对于L2, 是一个球, 没有角点, 所以没有更好的点来进行稀疏。
另外的看法, 对与 岭回归, 比如 坐标点是稀疏解, 比如 w=(1, 0),, 这时其cost 与 dense 解相同(稠密解, 因为没有在坐标轴上,没有值为0) , 如
)
,
即:
%7C%7B%7C_2%7D&space;=&space;%7C(1/%5Csqrt&space;2&space;,1/%5Csqrt&space;2&space;)%7C%7B%7C_2%7D&space;=&space;1)
。
而对于 lasso , w = (1, 0) 的花费是比
,
更小的。
%7C%7B%7C_1%7D&space;=&space;1&space;)
最严密的方法对于L1 产生的是稀疏解是检验其是否具备 优化条件。
三、 lasso 满足的优化条件
lasso 的目标函数形式:
&space;=&space;RSS(%5Ctheta&space;)&space;+&space;%5Clambda&space;%7C%7Cw%7C%7B%7C_1%7D)
,
由于

在wj = 0 处 不是连续可导的, 即是折线式的增长, 因而我们要进行的是非光滑的优化过程。
为了能操作不光滑的函数,我们需要定义一个倒数符号: 定义子导数(次梯度) subderivative 或 subgradient . 对于函数f , 在 点

处(此处是不光滑的)定义一个标量有
g:
&space;-&space;f(%7B%5Ctheta&space;_0%7D)&space;%5Cge&space;g(%5Ctheta&space;-&space;%7B%5Ctheta&space;_0%7D)%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%5Cforall&space;%5Ctheta&space;%5Cin&space;I)

可以看到蓝线即为不光滑的,在X0 ,不光滑点 ,我们 利用c, 或者c‘ 处直线的导数 ,即斜率来近似此处的导数。 这样就得到子导数了。
I 是
的一个邻域区间,
我们定义子导数 在区间[a, b] 这个是次梯度, 子导数的集合, 上有, a, b 是单侧极限
&space;-&space;f(%7B%5Ctheta&space;_0%7D)%7D%7D%7B%7B%5Ctheta&space;-&space;%7B%5Ctheta&space;_0%7D%7D%7D,%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;%7B%5Ckern&space;1pt%7D&space;b&space;=&space;%5Cmathop&space;%7B%5Clim&space;%7D%5Climits_%7B%5Ctheta&space;%5Cto&space;%5Ctheta&space;_%7B_0%7D%5E&space;+&space;%7D&space;%5Cfrac%7B%7Bf(%5Ctheta&space;)&space;-&space;f(%7B%5Ctheta&space;_0%7D)%7D%7D%7B%7B%5Ctheta&space;-&space;%7B%5Ctheta&space;_0%7D%7D%7D)
在集合[a, b]上 , 这一区间的子导数 叫做f 的 子一致可导点, 在
表示为
%7B%7C_%7B%7B%5Ctheta&space;_0%7D%7D%7D)
。
举个例子 , 对于绝对值函数 ,
&space;=&space;%7C%5Ctheta&space;%7C)
,
其子导数 实在
= 0 点, 所以有:
&space;=&space;%5Cbegin%7Bcases%7D&space;%5C%7B&space;-&space;1%5C%7D&space;&if&space;%5Ctheta&space;)
这样整个函数都可导了, 并且我们能够找到局部最小点 即 在点

,
处有
%7B%7C_%7B%5Chat&space;%5Ctheta&space;%7D%7D)
满足。
通过之前的分析知道了对于含有L1模项可以利用子导数来进行求解, 因而我们对于 RSS 项时:
&space;&=&space;%7Ba_j%7D%7Bw_j%7D&space;-&space;%7Bc_j%7D%5C%5C&space;%7Ba_j%7D&&space;=&space;2%5Csum%5Climits_%7Bi&space;=&space;1%7D%5En&space;%7Bx_%7B_%7Bij%7D%7D%5E2%7D&space;%5C%5C&space;%7Bc_j%7D&=&space;2%5Csum%5Climits_%7Bi&space;=&space;1%7D%5En&space;%7B%7Bx_%7Bij%7D%7D(%7By_i%7D&space;-&space;w_%7B&space;-&space;j%7D%5ET%7Bx_%7Bi,&space;-&space;j%7D%7D)%7D&space;%5Cend%7Balign*%7D)
其中w-j 是不包含第j 个成分的, xi,-j 也是这样的。 cj 项描述的是第 j 个特征x:,j 和 由于其他特征得到的残差项的相关性大小, r-j = y - X:-jw-j. 因此 cj 的大小描述的是 第j 个参量 与预测值y 的相关程度。 因为消除了其他项的成分。
这样整体目标函数有:
&space;&=&space;(%7Ba_j%7D%7Bw_j%7D&space;-&space;%7Bc_j%7D)&space;+&space;%5Clambda&space;%7B%5Cpartial&space;_%7B%7Bw_j%7D%7D%7D%7C%7Cw%7C%7B%7C_1%7D%5C%5C&space;&&space;=&space;%5Cbegin%7Bcases%7D&space;%5C%7B%7Ba_j%7D%7Bw_j%7D&space;-&space;%7Bc_j%7D&space;-&space;%5Clambda&space;%5C%7D&space;&if%7Bw_j%7D&space;)
这两者等价的。 我们要找最优解,求导 = 0 ,这时 的wj 的取值, 与cj 有关存在三种情况:
1) 如果

,
此式 cj 与残差强负相关, 这时的子梯度为零(即最小值)在

2) 若

,
,此式与残差弱相关,且得到的

3) 若

,
此时 cj 与残差 强正相关, 且有


所以综合以上三种情况有:
&space;=&space;%5Cbegin%7Bcases%7D&space;(%7Bc_j%7D&space;+&space;%5Clambda&space;)/%7Ba_j%7D&space;&&space;%5Cif&space;%5C;%7Bc_j%7D%3C%7B-%5Clambda%7D%5C%5C&space;0&space;&&space;%5Cif&space;%5C;%7Bc_j%7D%5Cin%5C%5B-%5Clambda,+%5Clambda%5D%5C%5C&space;(%7Bc_j%7D&space;-&space;%5Clambda&space;)/%7Ba_j%7D&space;&&space;%5Cif&space;%5C;%7Bc_j%7D%3E%5Clambda&space;%5Cend%7Bcases%7D)
可以写作:
&space;%5Cqquad&space;where&space;%5C;%5C;soft(a;%5Cdelta)&space;%7B%5Cbuildrel&space;%5CDelta&space;%5Cover=%7D&space;sign(a)(%7Ca%7C-%5Cdelta)_+)
其中
)
是正的
x 部分, 这个叫做软阈值。 下面左图中, 我们画

, 根据cj 的取值来画, 虚线表示 wj = cj/aj , 对应的是最小二乘拟合的情况,
实现对应的是
(cj)利用正则估计的结果, 移动虚线点的位置 大小为
,
特别在-
<= cj <=
,
这时有wj = 0。
相反的情况是右边的图, 硬阈值情况,只是在在-
<=
cj <=
, 这时有wj = 0, 其他情况不进行收缩。

在软阈值的情况, 软阈值线 的斜率与 对角线并不相关, 这就是说即使大的系数也可能收缩到0, 这样 lasso 是有偏估计。 这是我们不期望发生的, 因为 如果似然表明(通过cj) 其系数 wj 是很大的, 我们 就不想去收缩它。 这个将后续讨论。
这样我们就明白了为什么lasso 叫做“least absolute selection and shrinkage operator” 因为他选择一部分变量, 并且对所有的系数都通过罚的绝对值进行收缩, 如果
=0,
我们得到的是OLS解(最初的), 如果
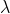
,
我们将得到

= 0. 其中

这时的系数将都为0 , 这时将没有意义,因此通常我们将取 最大罚为 L1 正则化目标。
%7C)
。
四、总结
L1 正则可以通过子集凸近似的过程变光滑,并且也可实现稀疏的过程,因而其应用更加广范。 并且也解释了 L2 不能用来进行稀释,而 L1 可以。
五、参考文献
1. 《Machine Learning A Probabilistic Perspective》
在L0 正则化中,通常我们有很多特征时, 这样在计算后验形式p(r|D) 有很大的复杂度。即使利用贪心算法,很容易陷入局部拟合情况。
其中一部分原因是因为 rj 特征是离散形式的, 这样造成目标函数的不光滑,
。
在优化领域中,通常的做法是对于离散的约束,我们通过松弛的方法来将其变为连续的约束。 我们可以在spike-and-slab 尖峰与平波模型中,通过在wj =0, 的 阶跃函数 取值处来用一定大小的概率值进行代替,这样通过在wj =0 用一定值代替,来构造成为连续函数的形式,这样来接近原始模型, 比如可以用零均值的laplace 模型代替。 这里我们应用了laplace
具有的长尾,(并且这里对于异常值的鲁棒对长尾的模型是很好的,正太情况将会有很大的异常变化。)
从图中可以看出, u = 0,也存在尖峰的,这样就可以用连续的形式进行代替,从而更好的优化目标函数。
更加精确的我们利用的Laplace
模型作为先验
我们用均匀先验的形式在截距项
,
, 因而在MAP 估计,其带罚的负log 似然形式为:
其中
为
w 的L1模, 利用合适的
, 可得到稀疏的
,
这里 我们认为 LI 正则是L0 非凸函数的 凸近似, 因为 L0 的模值 是0 ,wi, wj , ... 0 ... 每个是离散的, 而L1 模 是 |wj| 的加和, 因而是连续的一个值的过程,因而是凸近似。
所以在 线性回归中 L1 目标函数:
通常 用 0均值Laplace 先验参数, 这样的MAP估计就是L1正则,存在着 凸的和非凸的NLL项, 有很多算法设计解决这个问题(这个以后讨论)。
二、 为什么 L1 正则产生的是稀疏解
我们现在来说说 L1 产生的是稀疏解, 而L2 不是。我们主要以线性回归为例说明,这个在 逻辑回归和 其他GLMs 中是相似的。
虽然L1 是连续的,但是 还是不光滑的函数, 所以不光滑的目标函数为:
我们将其进行改写, 将后面的作为约束,但是变为光滑的目标函数: (二次函数 约束是线性的)
B是 w 的L1 模的上界, 小的 B 对应的是
大的罚项。
上式的光滑加约束的形式 ,就是 LASSO, 表示 “least absolute shrinkage and selection operator”, 最小绝对值收缩及选择算子。
同样对于 ridge regression L2 正则, 也可进行约束改写:
。
通过图形来直观的解释:
我们首先画出RSS 目标函数的轮廓线, 和 L1 、 L2 的约束边界线。 根据优化原理, 最优解点存在在图中阶数最小处的点,即 顶点处, 因而LI 是四个角点, L2 整个圆周处。 对于L1约束范围 进行扩张,
这时角点更容易接触到目标函数,尤其在高维的情况下, 角点是突出的,角点对应的是稀疏解。 对于L2, 是一个球, 没有角点, 所以没有更好的点来进行稀疏。
另外的看法, 对与 岭回归, 比如 坐标点是稀疏解, 比如 w=(1, 0),, 这时其cost 与 dense 解相同(稠密解, 因为没有在坐标轴上,没有值为0) , 如
,
即:
。
而对于 lasso , w = (1, 0) 的花费是比
,
更小的。
最严密的方法对于L1 产生的是稀疏解是检验其是否具备 优化条件。
三、 lasso 满足的优化条件
lasso 的目标函数形式:
,
由于
在wj = 0 处 不是连续可导的, 即是折线式的增长, 因而我们要进行的是非光滑的优化过程。
为了能操作不光滑的函数,我们需要定义一个倒数符号: 定义子导数(次梯度) subderivative 或 subgradient . 对于函数f , 在 点
处(此处是不光滑的)定义一个标量有
g:
可以看到蓝线即为不光滑的,在X0 ,不光滑点 ,我们 利用c, 或者c‘ 处直线的导数 ,即斜率来近似此处的导数。 这样就得到子导数了。
I 是
的一个邻域区间,
我们定义子导数 在区间[a, b] 这个是次梯度, 子导数的集合, 上有, a, b 是单侧极限
在集合[a, b]上 , 这一区间的子导数 叫做f 的 子一致可导点, 在
表示为
。
举个例子 , 对于绝对值函数 ,
,
其子导数 实在
= 0 点, 所以有:
这样整个函数都可导了, 并且我们能够找到局部最小点 即 在点
,
处有
满足。
通过之前的分析知道了对于含有L1模项可以利用子导数来进行求解, 因而我们对于 RSS 项时:
其中w-j 是不包含第j 个成分的, xi,-j 也是这样的。 cj 项描述的是第 j 个特征x:,j 和 由于其他特征得到的残差项的相关性大小, r-j = y - X:-jw-j. 因此 cj 的大小描述的是 第j 个参量 与预测值y 的相关程度。 因为消除了其他项的成分。
这样整体目标函数有:
这两者等价的。 我们要找最优解,求导 = 0 ,这时 的wj 的取值, 与cj 有关存在三种情况:
1) 如果
,
此式 cj 与残差强负相关, 这时的子梯度为零(即最小值)在
2) 若
,
,此式与残差弱相关,且得到的
3) 若
,
此时 cj 与残差 强正相关, 且有
所以综合以上三种情况有:
可以写作:
其中
是正的
x 部分, 这个叫做软阈值。 下面左图中, 我们画
, 根据cj 的取值来画, 虚线表示 wj = cj/aj , 对应的是最小二乘拟合的情况,
实现对应的是
(cj)利用正则估计的结果, 移动虚线点的位置 大小为
,
特别在-
<= cj <=
,
这时有wj = 0。
相反的情况是右边的图, 硬阈值情况,只是在在-
<=
cj <=
, 这时有wj = 0, 其他情况不进行收缩。
在软阈值的情况, 软阈值线 的斜率与 对角线并不相关, 这就是说即使大的系数也可能收缩到0, 这样 lasso 是有偏估计。 这是我们不期望发生的, 因为 如果似然表明(通过cj) 其系数 wj 是很大的, 我们 就不想去收缩它。 这个将后续讨论。
这样我们就明白了为什么lasso 叫做“least absolute selection and shrinkage operator” 因为他选择一部分变量, 并且对所有的系数都通过罚的绝对值进行收缩, 如果
=0,
我们得到的是OLS解(最初的), 如果
,
我们将得到
= 0. 其中
这时的系数将都为0 , 这时将没有意义,因此通常我们将取 最大罚为 L1 正则化目标。
。
四、总结
L1 正则可以通过子集凸近似的过程变光滑,并且也可实现稀疏的过程,因而其应用更加广范。 并且也解释了 L2 不能用来进行稀释,而 L1 可以。
五、参考文献
1. 《Machine Learning A Probabilistic Perspective》

相关文章推荐
- 机器学习稀疏之L0正则化
- 初学者如何学习机器学习中的L1和L2正则化
- 机器学习——正则化 (L1与L2范数)
- 【机器学习】贝叶斯角度看L1,L2正则化
- 机器学习笔记(二)L1,L2正则化
- 机器学习:L1与L2正则化项
- 笔记︱范数正则化L0、L1、L2-岭回归&Lasso回归(稀疏与特征工程)
- 笔记︱范数正则化L0、L1、L2-岭回归&Lasso回归(稀疏与特征工程)
- 【小结】机器学习中的正则化范数 -- L1范数与L2范数
- 笔记︱范数正则化L0、L1、L2-岭回归&Lasso回归(稀疏与特征工程)
- 机器学习正则化L0,L1,L2范数
- 范数正则化L0、L1、L2-岭回归&Lasso回归(稀疏与特征工程)
- Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解
- 机器学习中正则化方法简介:L1和L2正则化(regularization)、数据集扩增、dropout
- 机器学习稀疏 L1正则解法- LARS算法简介
- [置顶] 【机器学习 sklearn】模型正则化L1-Lasso,L2-Ridge
- 机器学习稀疏L1正则 - 修正的LARS算法和lasso
- 初学者如何学习机器学习中的L1和L2正则化
- 机器学习中的正则化技术L0,L1与L2范数
- 机器学习基础-正则化作用详解