深入浅出Linux内核内存管理基础
2015-01-18 16:45
225 查看
1 背景
1.1 用户空间与内核空间内存的划分
从Linux操作系统层次上,内存可划分为用户空间内存和内核空间内存。32位的CPU,最大寻址范围为2^32 - 1也就是4G的线性地址空间。Linux简化了分段机制,使得虚拟地址与线性地址总是一致的。Linux一般把这个4G的地址空间划分为两个部分:其中 0~3G为用户程序地址空间,虚地址0x00000000到0xBFFFFFFF,供各个进程使用;3G~4G为内核的地址空间,虚拟地址 0xC0000000到0xFFFFFFFF, 供内核使用。(注意,ARM架构不是3G/1G划分的,而是2G/2G划分。这里以3G/1G划分作讲解)。如下图所示:

可以看出,每个进程都有自己的私有用户空间(0-3GB),这个空间对系统中的其他进程是不可见的。最高的1GB内核空间则由则由所有进程以及内核共享。可见,内核最多寻址1G的虚拟地址空间。
Linux 内核采用了最简单的映射方式来映射物理内存,即把物理地址+PAGE_OFFSET按照线性关系直接映射到内核空间。PAGE_OFFSET大小为 0xC000000.
但是Linux内核并没有把整个1G空间用于线性映射,而只映射了最多896M物理内存,预留了最高端的128M虚拟地址空间给IO 设备和其他用途。有关此知识点的深入理解,读者可随后参考章节1.2.2内存区域(ZONE)的概念。
1.2 物理内存管理基础概念
Linux为了用统一的代码获得最大的兼容性,引入了以下物理内存管理概念:(1)内存结点(node);(2)内存区域(Zone);(3)内存页(page)1.2.1 内存节点Node
一般来说,存在 两种物理内存管理模型:(1)UMA ,一致内存访问模型;(2)NUMA,非一直内存访问模型。与UMA不同,NUMA模型下处理器访问本地内存的速度要快于其他内存访问本地内存的速度。
Linux源码中,以struct pglist_data数据结构表示单个内存节点。对于NUMA模型,多个内存节点通过链表串接起来;而UMA模型只有一个内存节点。

1.2.2 内存区域Zone
从理论上来讲,一个页帧就是一个内存存储单元,可永于做任何事情,如存储内核数据或用户数据,缓存磁盘数据,等等。然而,实际中,由于不同计算机类型的硬件架构不同,页帧的用途可能会有所限制。例如,在80X86架构下,Linux内核必须正确处理以下两个硬件限制:(1)旧的ISA总线的DMA处理器只能访问RAM的前16MB;
(2)现代的32位计算机ram内存越来越大,因为线性地址空间过小,CPU没办法访问所有内存。
为了解决以上两个限制,进而对物理页面进行有效的管理,对于每个内存节点Node, Linux又把物理页面划分为三个区:
· 专供DMA使用的ZONE_DMA区(小于16MB,其页帧可以被旧的ISA总线访问)
· 常规的ZONE_NORMAL区(大于16MB小于896MB)
· 内核不能直接映射的区ZONE_HIGME区(大于896MB)。
也就是说,Linux系统的物理内存被分配到几个内存节点Node, 而每个节点又划分为几个内存区域Zone.
high memory也是被内核管理的(有对应的page结构),只是没有映射到内核虚拟地址空间。当内核需要分配high memory时,通过kmap等从预留的地址空间中动态分配一个地址,然后映射到high memory,从而访问这个物理页。high memory映射到内核地址空间一般是暂时性的映射,不是永久映射。
1.2.3 内存页page
内存页(page frame) 是物理管理内存管理中的最小单位。Linux系统为物理内存的每个页创建一个struct page对象,并用全局对象struct page *mem_map (数组)来存放所有物理页对象的指针。LINUX采用4K页帧大小作为标准的内存分配单位,因此本文以4K页面作为讨论对象。Linux主要采用分页机制来实现虚拟存储器管理。这是因为:
· (1)Linux的分段机制使得所有的进程都使用相同的段寄存器值,这就使得内存管理变得简单,也就是说,所有的进程都使用同样的线性地址空间(0~4G)。
· (2)Linux设计目标之一就是能够把自己移植到绝大多数流行的处理器平台。但是,许多RISC处理器支持的段功能非常有限。
早期, 对于32位的计算机而言,页式管理是这么进行的,逻辑地址格式如下:
0 -11位:页内偏移OFFSET
12-21位:页面表偏移PT
22-31位:页面目录偏移PGD
寻址过程如下:
1)操作系统从寄存器CR3获得当前页面目录指针(基地址);
2)基地址+页面目录偏移->页面表指针(基地址);
3)页面表指针+页面表偏移->内存页基址;
4)内存页基址+页内偏移->具体物理内存单元。
显然,12位的页内偏移可以寻址4K,所以一张内存页为4K;而总共可寻内存为4G=2^10
* 2^10 * 2^12;因此在32位机器上内存上限一般为4G。
从内核2.6.11版本开始,Linux定义了四种类型的页表:
(1)总目录PGD(Page Global Directory),包含PUD的地址。
(2)上级目录PUD(Page Upper Derectory),包含PMD的地址
(3)中间目录PMD(Page Middle Derectory),包含PT的地址
(4)页表PT(Page Table),Page Table Entry指向页框
其页面寻址模型可用下图表示:

上述模型没有对线性地址按不同页表类型分配不同的位数,原因在于不同的架构表现不同。那么CR3是什么?请参考如下寄存器描述:
标志寄存器 :EFLAGS
指令指针:EIP
机器状态字:CR0
CR1是未定义的控制寄存器,供将来的处理器使用。
CR2是页故障线性地址寄存器,保存最后一次出现页故障的全32位线性地址。
CR3是页目录基址寄存器,保存页目录表的物理地址,页目录表总是放在以4K字节为单位的存储器边界上,因此,它的地址的低12位总为0,不起作用,即使写上内容,也不会被理会。
2 内存管理模型深入
2.1 内存模型总览
以NUMA模型为例,其内存管理组织架构大体如下图所示:
对于每个内存区Zone,它采用伙伴系统算法管理内存,其大致结构如下:

什么是Per-CPU page frame cache呢?
由于内核经常性的会请求一个页帧然后又释放它,这会带来系统性能问题。为了提高性能,每个内存区域zone定义了一个Per-CPU page frame cache。每个Per-CPU page frame cache包含了一些预分配的页帧。
在前面的总览图中可以看到,内核划分为节点Node。每个节点关联到系统中的一个处理器,在内核中表示为pg_data_t。示意图如下:

每个内存zone结构体都有一个成员struct free_area free_area[MAX_ORDER], 它用于实现伙伴系统,每个数组元素都表示某种固定长度的一些连续内存区,对于包含在每个区域中的空闲内存页的管理,free_area是一个起点。
每个内存zone结构体都有一个成员struct page *zone_mem_map,它指向内存区域zone的第一个页帧。
总之,memory node对应于结构pg_data_t,memory zone对应于结构zone,page对应于结构page,由zone_mem_map指向。
从数据结构的角度,可以绘制出如下关系图:

也有网友按照架构分层的概念,提出了如下内存管理架构模型:
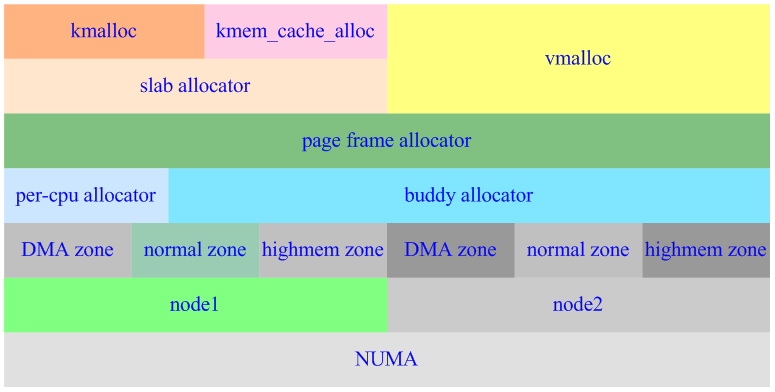
详见:http://blog.csdn.net/S_E_A_N/article/details/5829978
此架构模型是我较为推崇的,下面按照其思想从下往上分析。
2.2 内存节点Node数据结构分析
NUMA(Non-Uniform Memory Access)即非一致内存访问。在多CPU系统中有可能出现给定CPU对不同内存单元访问的时间不同。为了让指定CPU总能最先使用访问时间最短的内存,Linux把物理内存分成几块并以节点(node)标识。这样一来,每个CPU都有最快访问内存的节点,但并不等于只能访问这个节点。下表中node_zonelists将其他节点的各管理区也链了进来,但均排在本节点管理区之后,以示其它节点优先级低于本节点。内核中用struct pglist_data结构体来存放节点信息,各成员解释如下:
| 类型 | 名字 | 说明 |
| struct zone [] | node_zones | 节点中管理区描述符的数组,其子元素为结点中各内存域(zone)的数据结构 |
| struct zonelist [] | node_zonelists | zone表,页分配器获取内存的入口 |
| int | nr_zones | 节点中管理区的个数 |
| struct page * | node_mem_map | 节点中页描述符数组。它是一个指向page实例数组的指针,用于描述结点的所有物理内存页,可把它看做一个数组,包含了结点中所有内存域的页。 |
| struct bootmem_data * | bdata | 内核初始化阶段内存管理入口 |
| unsigned long | node_start_pfn | 节点中第一个叶框下标或逻辑编号,系统中所有的页帧是依次编号的,每个页帧的号码都是全局唯一的(不只是结点内唯一)。 |
| unsigned long | node_present_pages | 属于本节点的内存的页框数(不包括洞) |
| unsigned long | node_spanned_pages | 属于本节点的内存的页框数(包括洞) |
| int | node_id | 节点标识符,全局结点ID,系统中的NUMA结点都从0开始编号 |
| wait_queue_head_t | kswapd_wait | kswapd页换出守护进程使用的等待队列 |
| struct task_struct * | kswapd | 指针指向kswapd内核线程的进程描述符 |
| int | kswapd_max_order | kswapd将要创建空闲块大小取对数的值 |
2.3 内存域Zone数据结构分析
内核用struct zone来管理内存区,各成员解释如下:| 类型 | 名字 | 说明 |
| unsigned long | pages_min | 管理区中保留页的数目 |
| unsigned long | pages_low | 回收页框时使用的下界,同时也被管理区分配器作为阈值使用 |
| unsigned long | pages_high | 回收页框时使用的上界,同时也被管理区分配器作为阈值使用 |
| unsigned long [] | lowmem_reserve | 指明在处理内存不足的临界情况下管理区必须保留的页框数 |
| struct per_cpu_pageset [] | pageset | 用于实现单一页框的特殊高速缓存 |
| spinlock_t | lock | 保护该描述符的自旋锁 |
| struct free_area [] | free_area | 标识出管理区中的空闲页框 |
| spinlock_t | lru_lock | 活动以及非活动链表使用的自旋锁 |
| struct lru [] | lru | 活动以及非活动链表 |
| unsigned long | flags | 管理区标志 |
| atomic_long_t [] | vm_stat | 管理区内各类型内存统计 |
| int | prev_priority | 管理区优先级,由回收页框算法使用 |
| wait_queue_head_t * | wait_table | 进程等待队列的散列表,这些进程正在等待管理区中的某项。 |
| unsigned long | wait_table_bits | 等待队列散列表数组大小,置位2的order幂 |
| struct pglist_data * | zone_pgdat | 包含该管理区的节点指针 |
| unsigned long | zone_start_pfn | 管理区的起始页框号 |
| unsigned long | spanned_pages | 管理区的页框数,包括洞 |
| unsigned long | present_pages | 管理区的页框数,不包括洞 |
| const char * | name | 指向管理区名字,一般为"DMA" "Normal" "HighMem" |
2.4 内存页数据结构分析
内核必须记录每个页框当前的状态。例如,内核必须能区分哪些页框包含的是属于进程的页,而哪些页框包含的是内核代码或内核数据。类似地,内核还必须能够确定动态内存中的页框是否空闲。如果动态内存中的页框不包含有用的数据,那么这个页框就是空闲的。在以下情况下页框是不空闲的:包含用户态进程的数据、某个软件高速缓存的数据、动态分配的内核数据结构、设备驱动程序缓冲的数据、内核模块的代码等等。页框的状态信息保存在一个类型为page的页描述符中,其中的字段如下表所示。所有的页描述符存放在mem_map数组中。因为每个描述符长度为32字节,所以mem_map所需要的空间略小于整个内存的1%。virt_to_page(addr)宏产生线性地址addr对应的页描述符地址。pfn_to_page(pfn)宏产生与页框号pfn对应的页描述符地址。
页描述符,在内核中表示为struct page:
| 类型 | 名字 | 说明 |
| unsigned long | flags | 页标志,包括所在的节点及管理区编号(高位上) |
| atomic_t | _count | 页框的引用计数器 |
| atomic_t | _mapcount | 页框中的页表项数目,如果没有则为-1 |
| unsigned long | private | 可用于正在使用页的内核成分(例如,在缓冲页的情况下它是一个缓冲器头指针)。如果页是空闲的,则该字段由伙伴系统使用(存放order值) |
| struct address_space * | mapping | 当页被插入页高速缓存中时使用,或者当页属于匿名区时使用 |
| pgoff_t | index | 作为不同的含义被几种内核成分使用。例如,它在页磁盘映像或匿名区中标识存放在页框中的数据的位置,或者它存放一个换出页标识符 |
| struct list_head | lru | 包含页的最近最少使用(LRU)双向链表的指针 |
_count
页的引用计数器。如果该字段为-1,则相应页框空闲,并可被分配给任一进程或内核本身;如果该字段的值大于或等于0,则说明页框被分配给了一个或多个进程,或用于存放一些内核数据结构。page_count()函数返回_count加1后的值,也就是该页的使用者的数目。
flags
包含多达32个用来描述页框状态的标志,如下表。对于每个PG_xyz标志,内核都定义了操作其值的一些宏。通常,PageXyz宏返回标志的值,而SetPageXyz和ClearPageXyz宏分别设置和清除相应的位。页标志32位分布如下:
Page flags: | [SECTION] | [NODE] | ZONE | ... | FLAGS |
| 标志名 | 含义 |
| PG_locked | 页被锁定。例如,在磁盘I/O操作中涉及的页 |
| PG_error | 在传输页时发生I/O错误 |
| PG_referenced | 刚刚访问过的页 |
| PG_uptodate | 在完成读操作后置位,除非发生磁盘I/O错误 |
| PG_dirty | 页已经被修改 |
| PG_lru | 页在活动或非活动页链表中 |
| PG_active | 页在活动页链表中 |
| PG_slab | 包含在slab中的页框 |
| PG_highmem | 页框属于ZONE_HIGHMEM管理区 |
| PG_checked | 由一些文件系统(如Ext3)使用的标志 |
| PG_reserved | 页框留给内核代码或没有使用 |
| PG_private | 页描述符的private字段存放了有意义的数据 |
| PG_writeback | 正在使用writepage方法将页写到磁盘上 |
| PG_nosave | 系统挂起/唤醒时使用 |
| PG_compound | 通过扩展分页机制处理页框 |
| PG_swapcache | 页属于对换高速缓存 |
| PG_mappedtodisk | 页框中的所有数据对应于磁盘上分配的块 |
| PG_reclaim | 为回收内存对页已经做了写入磁盘的标记 |
| PG_nosave_free | 系统挂起/恢复时使用 |
2.5 伙伴系统算法减少外部碎片
从总体上把握Linux内存管理
读者可参考如上文章建立内存碎片的概念。这里为了方便,复习如下:外部碎片是出于任何已分配区域或页面外部的空闲存储块。这些存储块的总和可以满足当前申请的长度要求,但是由于它们的地址不连续或其他原因,使得系统无法满足当前申请。 造成问题:系统虽有足够的内存,但却都是分散的碎片,无法满足对大块“连续内存”的需求。为了避免“外部碎片”这种问题的发生,有两种办法:
(1)通过使用页转换电路,把那些不连续的未分配的页帧转换为线性地址;
(2)开发出一种算法,追踪现存的连续的未分配的页帧,尽可能避免拆分一个大得多的内存块去满足较小的内存开辟请求。 即将大内存分成各种固定大小的块,每次分配时,尽量使用最接近申请大小的那一块,尽量避免为满足小块内存的申请而分拆大的块。
上述办法(1)即是vmalloc的思想,但有时后要求申请到内存必须是连续,这就需要方法II。其实方法(1)还有一个缺点:它需要修改页表,需要硬件的频繁动作,这增加了内存申请和使用的时间。因此多数情况都采用方法(2)来申请内存。伙伴系统算法即是方法(2)的一个使用算法,使用它可减少外部碎片。
伙伴系统特征如下:
I 把所有的空闲页框分组为MAX_ORDER(ICE为11)个块链表,每个块链表分别包含大小为2n(n为0~10的整数)个连续的页框,即1、2、4、6、8、16、32、64、128、256、512和1024个连续的页框。
II 每个块的第一个页框的物理地址是该块大小的整数倍。
前面提到了,内存区域zone数据结构,但是在zone中主要关心的是下面的这个结构体数组:
struct zone
{
..........
struct free_area free_area[MAX_ORDER];
..........
}
struct free_area定义如下:
struct free_area
{
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
其中free_list用来连接不用的页描述符,nr_free指定了当前区中空闲页的数目,free_list用于连接空闲页的链表。而在free_area数组中MAX_ORDER定义为11,其数组下标对应为该内存块的阶。也就是说,伙伴算法把内存块按大小分组管理,即将所有空闲页帧分组为11个块链表(block List),每个块链表分别包含1,2,4,8,16,32,64,128,256,512,1024个连续的页帧(也就是2的0次方,到2的10次方)。
一个简单的图示:

更详细点的图示:

下面详细叙述伙伴系统的工作原理:
比如说我们要申请一个b阶大小的页块,那么系统会直接在b阶块中查找看这个链表是否为空,如果不为空则说明恰好有这么大的页可以用于分配。如果该链表为空,则会在b+1阶中寻找,如过b+1阶链表不为空,则将b+1中页块一分为二,一半用于分配,另一半加入b阶链表中。如果b+1阶链表也为空那么就继续向上寻找,如果都没找到空闲地址,就只能返回NULL。
上面的过程是分配空间的过程,在释放页的时候正好是分配的一个逆过程,内核会试图将两个b阶的页块合并程一个2b阶的大页块,如果可以合并就将这两个页块称为伙伴,满足伙伴的的要求如下:
1)两个块具有相同的大小,记作b。
2)它们的物理地址是连续的。
3)第一块的第一个页的物理地址是2*b*PAGE_SIZE的倍数即第0块和第1块是伙伴,第2块和第3块是伙伴,但是第1块和第2块不是伙伴。这样规定的目的是确保一对伙伴中的两个块可以合并成更高级的大块。
2.6 页框分配器
页框分配器核心函数是__alloc_pages_internal()它主要调用的函数是__rmqueue()。简单的说页框分配器是对伙伴系统的一种封装。我们常用的页框分配函数又是对__alloc_pages_internal()的封装,如:alloc_pages_node()。alloc_pages_node()返回给调用者的是页框描述符。下面slab分配器使用的kmem_getpages()仅是将alloc_pages_node()返回的页框描述符转换成了线性地址。2.7 SLAB机制管理内存,减少内部碎片
内部碎片是处于区域内部或页面内部的存储块。占有这些区域或页面的进程并不使用这个块。而在进程占有这块存储存储块时,系统无法利用它。直到进程释放它,或进程结束时,系统才有可能利用这个存储块。造成原因一般为:系统为了一小段连续内存区的需要,不得已给它分配了一大块连续内存,从而造成了内存浪费。为了满足内核对这种小内存块的需要,Linux系统采用了一种被称为slab分配器的技术。Slab分配器的实现相当复杂,但原理不难,其核心思想就是“存储池”的运用。内存片段(小块内存)被看作对象,当被使用完后,并不直接释放而是被缓存到“存储池”里,留做下次使用,这无疑避免了频繁创建与销毁对象所带来的额外负载。
slab分配器有三个目标:
I 减少系统分配小块内存时产生的碎片;
II 把经常使用的对象缓存起来,减少分配、初始化及释放对象的时间开销;
III 调整对象以更好的使用硬件高速缓存。
Slab技术不但避免了内存内部分片(下文将解释)带来的不便(引入Slab分配器的主要目的是为了减少对伙伴系统分配算法的调用次数——频繁分配和回收必然会导致内存碎片——难以找到大块连续的可用内存),而且可以很好利用硬件缓存提高访问速度。
Slab并非是脱离伙伴关系而独立存在的一种内存分配方式,slab仍然是建立在页面基础之上。SLAB分配器的基本思想是先利用页面分配器分配出单个或连续的物理页面,然后在此基础上将整块页面分割成多个相等的小内存单元,以满足小内存空间分配的需要。换句话说,Slab将页面(来自于伙伴关系管理的空闲页框链)撕碎成众多小内存块以供分配,slab中的对象分配和销毁使用kmem_cache_alloc()与kmem_cache_free()。
常用的kmalloc建立在slab分配器的基础之上。
SLAB机制的工作层次示意如下:

注:本文参考大量网友著作,并经过了本人的系统研究、总结或组合。
部分参考列表:
(1)http://blog.csdn.net/S_E_A_N/article/details/5829978

相关文章推荐
- 深入浅出Linux内核内存管理基础
- Linux下Shell基础知识深入浅出
- C++内存管理基础之new & delete
- Linux内核及ARM的内存管理
- Linux内核基础知识汇总(不断添加中...)
- Object-C 基础之7 — 内存管理(0)
- linux内核内存管理中的pagevec结构体
- 【51CTO电子书最新力作】深入浅出Linux基础教程 免费下载 经典珍藏
- C++内存管理基础之new & delete
- Linux内核在I386架构下的内存管理
- 共享好书:ajax基础教程与深入浅出Hibernate两本电子书
- C++内存管理基础之new & delete
- WINCE内存管理基础
- Linux内核中的内存管理浅谈
- Linux测试基础-Linux内核剖析
- Linux内核管理基础知识概述 二
- Linux内核管理基础知识概述
- 【嵌入式Linux学习七步曲之第五篇 Linux内核及驱动编程】Linux内核线程之深入浅出
- Linux内核及ARM的内存管理(再续)
- objective-c内存管理基础