Spark资源分配异常闪Bug
2015-01-17 14:52
323 查看
故障描述
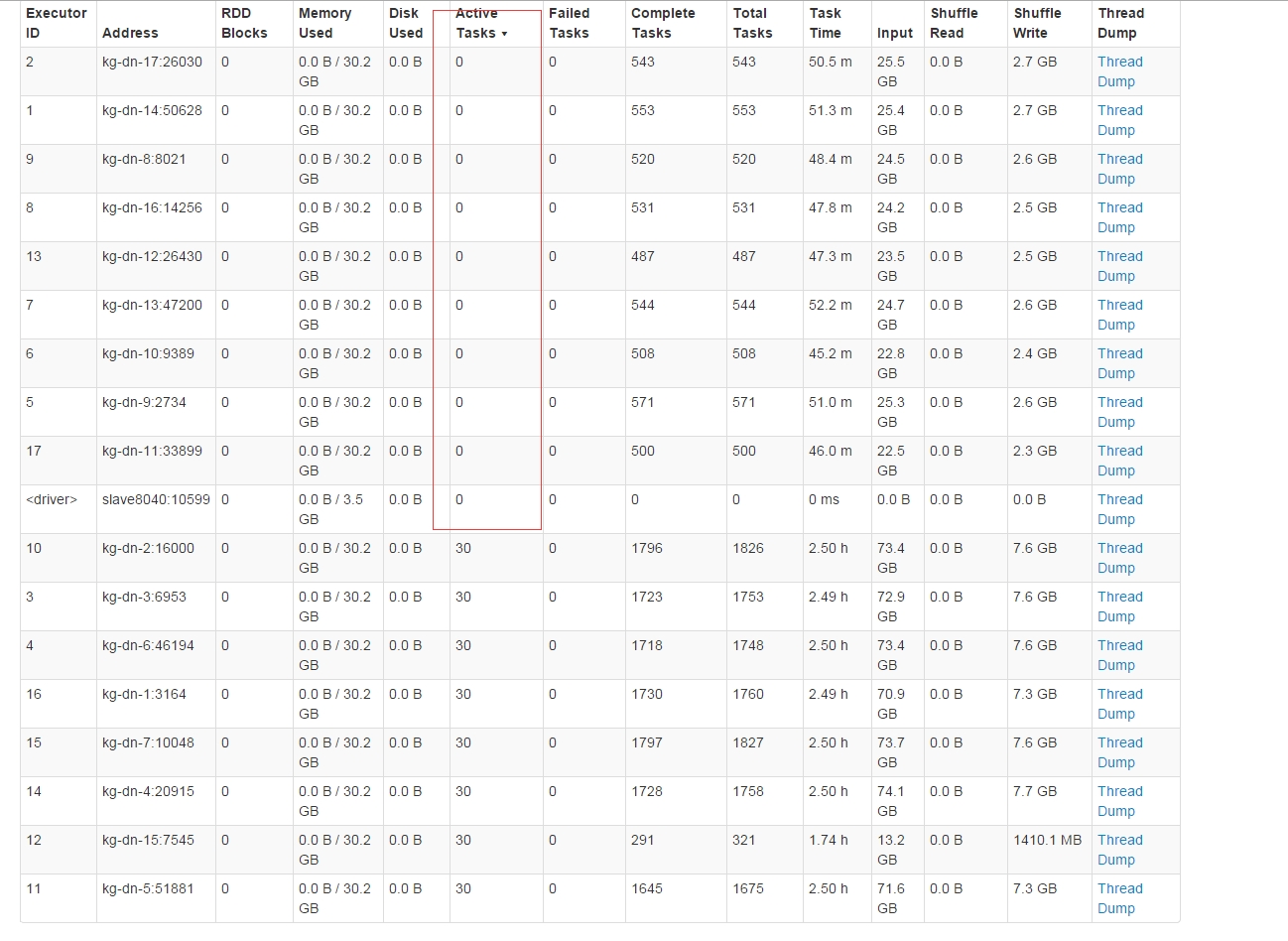
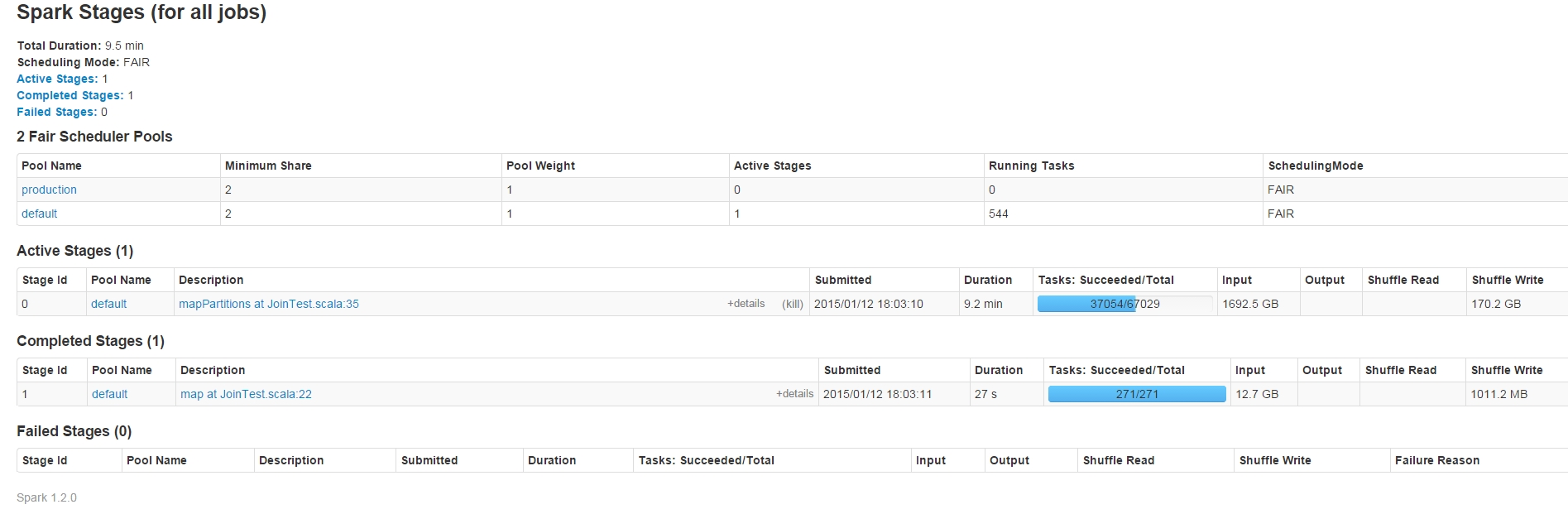
前段时间在测试Spark的RDD转换的lazy特性是发现了一个Spark内部对taskSet在executor的运行分配不均匀问题。先上两张图出现问题时间点的图,大家估计就明白怎么回事了:
再看看简单的测试代码:
前段时间在测试Spark的RDD转换的lazy特性是发现了一个Spark内部对taskSet在executor的运行分配不均匀问题。先上两张图出现问题时间点的图,大家估计就明白怎么回事了:
再看看简单的测试代码:
import org.apache.spark._
import org.apache.spark.storage.StorageLevel
/**
* Created by zhaozhengzeng on 2015/1/5.
*/
import java.util.Random
import org.apache.hadoop.io.compress.CompressionCodec
import org.apache.spark.rdd.RDD
import org.apache.spark.SparkContext._
object JoinTest {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("Spark count test").
set("spark.kryoserializer.buffer.max.mb", "128").
set("spark.shuffle.manager", "sort")
// set("spark.default.parallelism","1000")
val sc = new SparkContext(sparkConf)
//连接表1
val textFile1 = sc.textFile("/user/hive/warehouse/test1.db/st_pc_lifecycle_list/dt=2014-07-01").map(p => {
val line = p.split("\\|")
(line(10), 1)
}
).reduceByKey((x, y) => x + y)
//测试RDD的lozy特性
val textFile3 = sc.textFile("/user/hive/warehouse/test1.db/st_pc_lifecycle_list/dt=2014-09-*").map(p => {
val line = p.split("\\|")
(line(11),"")
})
val textFile2 = sc.textFile("/user/hive/warehouse/test1.db/st_pc_lifecycle_list/*").mapPartitions({ it =>
for {
line <- it
} yield (line.split("\\|")(10), "")
})
val count = textFile1.join(textFile2).count()
println("join 之后的记录数据:" + count)
//textFile1.saveAsTextFile("/user/hive/warehouse/test1.db/testRs/rs2")
sc.stop()
}
}描述下,上面代码主要测试RDD的Join转换,以及测试textFile3的translation的lazy特性。在整个测试过程通过观察Spark UI看到上面这种TaskSet分布不均匀情况。第一个图中的Active Task为0的executor中在运行第一个stage的taskSet后,spark不会讲第二个stage的taskSet分配到这些executor中执行了。但是奇怪的是这种情况并不是经常会出现,我再接下来的N次重跑作业又不会出现这种情况,具体什么原因暂时无法找到,连重现的机会都没有,哈哈。这里先记录下吧,再观察...

相关文章推荐
- 关于spark程序动态资源分配的一些理解
- finally不管有没有错都会运行 finally 块用于清除 try 块中分配的任何资源,以及运行任何即使在发生异常时也必须执行的代码
- Spark 动态资源分配(Dynamic Resource Allocation) 解析
- spark调度系列----1. spark stanalone模式下Master对worker上各个executor资源的分配
- Spark1.3从创建到提交:4)资源分配源码分析
- 第31课: Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
- 性能调优-给spark作业分配更多的资源
- Standalone模式下Spark任务资源分配
- [Spark内核] 第31课:Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
- Spark错误异常-资源占用,任务挂起
- Spark性能调优之资源分配
- spark&yarn&storm的资源管理分配对并发性的考量
- Spark性能调优之——在实际项目中分配更多的资源
- spark优化(一):合理分配资源
- 【原】Spark不同运行模式下资源分配源码解读
- Spark 源码阅读(6)——Master接收到ClientActor后,进行worker的资源分配
- Spark Streaming揭秘 Day17 资源动态分配
- spark集群无法分配资源
- spark学习-59-Spark的动态资源分配ExecutorAllocationManager
- 发现flex的bug——DateField属性formatString中文资源文件有问题导致DateField工作异常