开源日志收集软件fluentd 转发(forward)架构配置
2015-01-06 16:27
846 查看
需求:
通过开源软件fluentd收集各个设备的apache访问日志到fluentd的转发服务器中,然后通过webHDFS接口,写入到hdfs文件系统中。
软件版本说明:
hadoop版本:1.1.2
fluentd版本:1.1.21
测试环境说明:
node29服务器上安装了apache,以及fluentd,作为fluentd的客户端;
node1服务器,为hadoop服务器的namenode;
node29服务器上fluentd配置文件:
node1服务器配置,这个服务器上配置了hadoop的namenode,以及作为fluentd的转发角色,具体配置文件如下:
<match apache.access>
type webhdfs
host node1.test.com
port 50070
path /apache/%Y%m%d_%H/access.log.${hostname}
time_slice_format %Y%m%d
time_slice_wait 10m
#定义日志入库日志的时间;
time_format %Y-%m-%d %H:%M:%S
localtime
flush_interval 1s
</match>
配置好以后,重启fluentd服务;
开始测试,在node29用ab命令开始访问apache,生成访问日志;
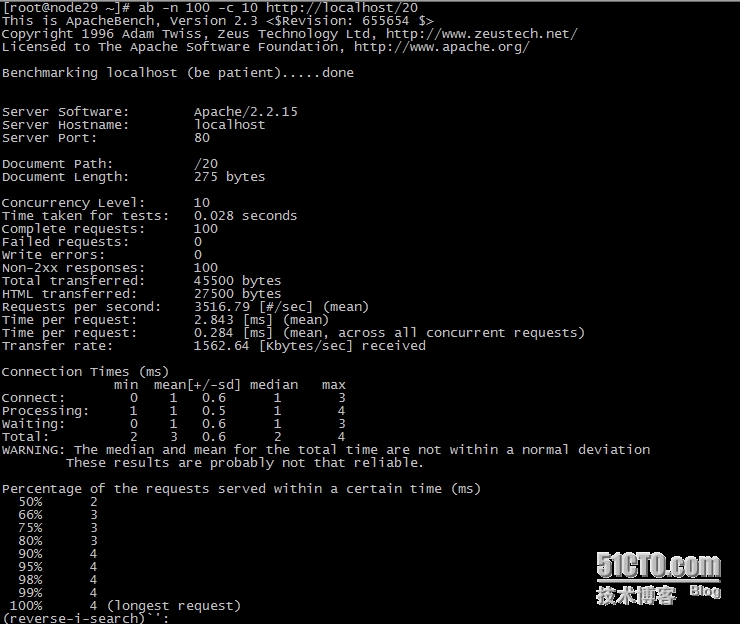
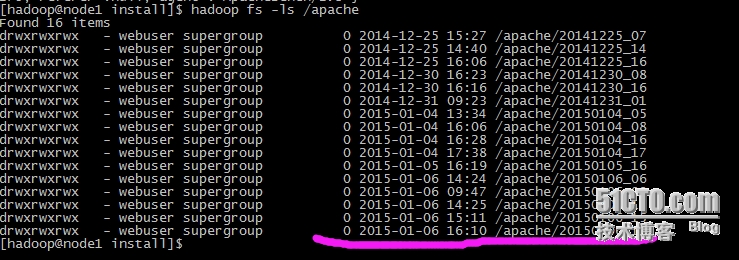
然后,到node1服务器上去查看HDFS文件系统中,是否生成了相关文件及目录:
查看生成的目录:
查看文件里面具体日志:
hadoop fs -cat /apache/20150106_16/access.log.node1.test.com

如上图所示,fluentd已经通过转发模式,把node29服务器上apache日志收集到hdfs文件系统中了,方便下一步用hadoop进行离线分析。
本文出自 “shine_forever的博客” 博客,请务必保留此出处http://shineforever.blog.51cto.com/1429204/1599771
通过开源软件fluentd收集各个设备的apache访问日志到fluentd的转发服务器中,然后通过webHDFS接口,写入到hdfs文件系统中。
软件版本说明:
hadoop版本:1.1.2
fluentd版本:1.1.21
测试环境说明:
node29服务器上安装了apache,以及fluentd,作为fluentd的客户端;
node1服务器,为hadoop服务器的namenode;
node29服务器上fluentd配置文件:
<source> type tail format apache2 path /var/log/httpd/access_log pos_file /var/log/td-agent/access_log.pos time_format %Y-%m-%d %H:%M:%S localtime tag apache.access </source> #Log Forwarding to node1 server <match apache.access> type forward # time_slice_format %Y%m%d # time_slice_wait 10m # localtime #定义日志入库日志的时间; time_format %Y-%m-%d %H:%M:%S #localtime非常重要,不设置日志时间和系统时间相差8小时; localtime #定义入库日志的时间; <server> host node1 port 24224 </server> flush_interval 1s </match>
node1服务器配置,这个服务器上配置了hadoop的namenode,以及作为fluentd的转发角色,具体配置文件如下:
<source> type forward port 24224 </source>
<match apache.access>
type webhdfs
host node1.test.com
port 50070
path /apache/%Y%m%d_%H/access.log.${hostname}
time_slice_format %Y%m%d
time_slice_wait 10m
#定义日志入库日志的时间;
time_format %Y-%m-%d %H:%M:%S
localtime
flush_interval 1s
</match>
配置好以后,重启fluentd服务;
开始测试,在node29用ab命令开始访问apache,生成访问日志;
然后,到node1服务器上去查看HDFS文件系统中,是否生成了相关文件及目录:
查看生成的目录:
查看文件里面具体日志:
hadoop fs -cat /apache/20150106_16/access.log.node1.test.com
如上图所示,fluentd已经通过转发模式,把node29服务器上apache日志收集到hdfs文件系统中了,方便下一步用hadoop进行离线分析。
本文出自 “shine_forever的博客” 博客,请务必保留此出处http://shineforever.blog.51cto.com/1429204/1599771

相关文章推荐
- 开源日志收集软件fluentd 转发(forward)架构配置
- 使用开源工具fluentd-pilot收集容器日志
- C#实现多级子目录Zip压缩解压实例 NET4.6下的UTC时间转换 [译]ASP.NET Core Web API 中使用Oracle数据库和Dapper看这篇就够了 asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程 asp.net core异步进行新增操作并且需要判断某些字段是否重复的三种解决方案 .NET Core开发日志
- 使用开源工具fluentd-pilot收集容器日志
- 为什么说JAVA中要慎重使用继承 C# 语言历史版本特性(C# 1.0到C# 8.0汇总) SQL Server事务 事务日志 SQL Server 锁详解 软件架构之 23种设计模式 Oracle与Sqlserver:Order by NULL值介绍 asp.net MVC漏油配置总结
- asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程
- 使用开源工具fluentd-pilot收集容器日志
- 利用开源日志收集软件fluentd收集日志到HDFS文件系统中
- Flume(NG)架构设计要点及配置实践 Flume NG是一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集
- 开源软件收集
- 分布式日志收集系统: Facebook Scribe之配置文件
- 收集的网络上大型的开源图像处理软件代码(提供下载链接)
- 分布式日志收集系统: Facebook Scribe之配置文件
- 分布式日志收集系统: Facebook Scribe之配置文件
- 国产免费非开源测试管理软件MYPM 零配置安装过程
- 收集的网络上大型的开源图像处理软件代码(提供下载链接)
- 一些嵌入式开源软件的资源网站 (持续收集中)
- 开源软件收集
- 使用Fluentd + MongoDB构建实时日志收集系统
- 改造apache的开源日志项目来实现 分布式日志收集系统