层次分析法量化用户的产品偏好
2014-12-19 01:03
585 查看
层次分析法量化用户的产品偏好
用户对产品有很多行为,如何进行用户行为分析来量化用户对产品的喜好程度呢?
比如豆瓣FM,用户可以点击“喜好”和"扔进垃圾箱"等;比如优酷视频,用户可以顶,踩,分享等。
我们如何通过这些行为信息分析用户对这首歌的喜好程度,对这个视频的评分是多少。
下面实例分析用户对视频的喜好程度。说到视频,我们可以联想到各种用户行为,看了多久,是否评论,是顶是踩,是否分享?
我们可以通过这些指标来评估用户对该视频的打分。比如用户看了多久打多少分,分享了打多少分等。还有就是不同的行为也反映了不同程度的喜好。
我们可以通过一条简单的公司来评估打分,score=w1*x1+w2*x2.......
x1,x2等是行为指标,w1,w2等是行为权重。
行为指标:比如用户点了赞,给1分,分享了,给2分。通常这里需要做归一化处理,把分数压缩到一个合理范围。
(PS:这里相当于领域专家打分,不知道是否通过建模的方法,有待探讨)。
行为权重:不同的行为,反映了用户的不同喜好程度,比如分享了比顶赞更重要。面对众多指标,如何合理地确定各权重呢?
这里通过层次分析法来确定各行为指标的权重。
构造成对比较矩阵
比如第四行第一列的数字3,表示“下载”比“播放时长”稍重要。
列进行归一化
[[ 0.05555556 0.0521327 0.07692308 0.05830389 0.03508772 0.06896552]
[0.16666667 0.15797788 0.07692308 0.17667845 0.1754386 0.17241379]
[0.05555556 0.15797788 0.07692308 0.05830389 0.0877193 0.06896552]
[0.16666667 0.15797788 0.23076923 0.17667845 0.1754386 0.17241379]
[0.27777778 0.15797788 0.15384615 0.17667845 0.1754386 0.17241379]
[0.27777778 0.31595577 0.38461538 0.35335689 0.35087719 0.34482759]]
行求和
[ 0.34696846 0.92609846 0.50544522 1.07994462 1.11413265 2.0274106 ]
再归一化:
[ 0.05782808 0.15434974 0.08424087 0.17999077 0.18568877 0.33790177]
就得到了个指标的权重
对于各项指标的得分,也要进行归一化处理,比如把分数限定在0-1.
假如一个用户对一个视频的各指标得分是
则将得分进行加权求和(或者平均),得到该用户对该视频的评分。
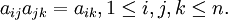
但实际上在构造成对比较矩阵时要求满足上述众多等式是不可能的。因此退而要求成对比较矩阵有一定的一致性,即可以允许成对比较矩阵存在一定程度的不一致性。
由分析可知,对完全一致的成对比较矩阵,其绝对值最大的特征值等于该矩阵的维数。对成对比较矩阵 的一致性要求,转化为要求: 矩阵的绝对值最大的特征值和该矩阵的维数相差不大。
python代码实现
输出是:
[ 0.05782808 0.15434974 0.08424087 0.17999077 0.18568877 0.33790177]
(6.16381602081+0j)
其中,第一行就是权重了,第二行就是最大特征值。显然,矩阵的维数是6,跟最大特征值差不多,合理。
PS:如果有什么更好的用户行为分析和量化用户产品偏好的做法,欢迎交流!!!!!!!!!!
参考资料:
http://wiki.mbalib.com/wiki/%E5%B1%82%E6%AC%A1%E5%88%86%E6%9E%90%E6%B3%95
http://courseware.ecnudec.com/zsb/zsx/zsx07/zsx07d/zsx07d000.htm
http://www.tup.tsinghua.edu.cn/Resource/tsyz/035658-01.pdf
http://blog.csdn.net/huruzun/article/details/39801217
http://www.cnblogs.com/broadview/archive/2013/02/27/2934925.html
本文链接:http://blog.csdn.net/lingerlanlan/article/details/41917319
本文作者:linger
用户对产品有很多行为,如何进行用户行为分析来量化用户对产品的喜好程度呢?
比如豆瓣FM,用户可以点击“喜好”和"扔进垃圾箱"等;比如优酷视频,用户可以顶,踩,分享等。
我们如何通过这些行为信息分析用户对这首歌的喜好程度,对这个视频的评分是多少。
下面实例分析用户对视频的喜好程度。说到视频,我们可以联想到各种用户行为,看了多久,是否评论,是顶是踩,是否分享?
我们可以通过这些指标来评估用户对该视频的打分。比如用户看了多久打多少分,分享了打多少分等。还有就是不同的行为也反映了不同程度的喜好。
我们可以通过一条简单的公司来评估打分,score=w1*x1+w2*x2.......
x1,x2等是行为指标,w1,w2等是行为权重。
行为指标:比如用户点了赞,给1分,分享了,给2分。通常这里需要做归一化处理,把分数压缩到一个合理范围。
(PS:这里相当于领域专家打分,不知道是否通过建模的方法,有待探讨)。
行为权重:不同的行为,反映了用户的不同喜好程度,比如分享了比顶赞更重要。面对众多指标,如何合理地确定各权重呢?
这里通过层次分析法来确定各行为指标的权重。
构造成对比较矩阵
| | 播放时长 | 播放时长/ 视频时长 | 评论 | 下载 | 收藏 | 分享 |
| 播放时长 | 1 | 1/3 | 1 | 1/3 | 1/5 | 1/5 |
| 播放时长/ 视频时长 | 3 | 1 | 1 | 1 | 1 | 1/2 |
| 评论 | 1 | 1 | 1 | 1/3 | 1/2 | 1/5 |
| 下载 | 3 | 1 | 3 | 1 | 1 | 1/2 |
| 收藏 | 5 | 1 | 2 | 1 | 1 | 1/2 |
| 分享 | 5 | 2 | 5 | 2 | 2 | 1 |
| 标度 | 含义 |
| 1 | 表示两个元素相比,具有同样重要性 |
| 3 | 表示两个元素相比,前者比后者稍重要 |
| 5 | 表示两个元素相比,前者比后者明显重要 |
| 7 | 表示两个元素相比,前者比后者强烈重要 |
| 9 | 表示两个元素相比,前者比后者极端重要 |
| 2,4,6,8 | 表示上述相邻判断的中间值 |
| 倒数 | 若元素与的重要性之比为,那么元素与元素重 要性之比为 |
列进行归一化
[[ 0.05555556 0.0521327 0.07692308 0.05830389 0.03508772 0.06896552]
[0.16666667 0.15797788 0.07692308 0.17667845 0.1754386 0.17241379]
[0.05555556 0.15797788 0.07692308 0.05830389 0.0877193 0.06896552]
[0.16666667 0.15797788 0.23076923 0.17667845 0.1754386 0.17241379]
[0.27777778 0.15797788 0.15384615 0.17667845 0.1754386 0.17241379]
[0.27777778 0.31595577 0.38461538 0.35335689 0.35087719 0.34482759]]
行求和
[ 0.34696846 0.92609846 0.50544522 1.07994462 1.11413265 2.0274106 ]
再归一化:
[ 0.05782808 0.15434974 0.08424087 0.17999077 0.18568877 0.33790177]
| 播放时长 | 播放时长/ 视频时长 | 评论 | 下载 | 收藏 | 分享 |
| 0.05782808 | 0.15434974 | 0.08424087 | 0.17999077 | 0.18568877 | 0.33790177 |
对于各项指标的得分,也要进行归一化处理,比如把分数限定在0-1.
假如一个用户对一个视频的各指标得分是
| 播放时长 | 播放时长/ 视频时长 | 评论 | 下载 | 收藏 | 分享 |
| 0.9 | 0.8 | 1 | 0 | 0 | 0 |
则将得分进行加权求和(或者平均),得到该用户对该视频的评分。
作一致性检验
从理论上分析得到:如果A是完全一致的成对比较矩阵,应该有但实际上在构造成对比较矩阵时要求满足上述众多等式是不可能的。因此退而要求成对比较矩阵有一定的一致性,即可以允许成对比较矩阵存在一定程度的不一致性。
由分析可知,对完全一致的成对比较矩阵,其绝对值最大的特征值等于该矩阵的维数。对成对比较矩阵 的一致性要求,转化为要求: 矩阵的绝对值最大的特征值和该矩阵的维数相差不大。
python代码实现
import numpy as np
import numpy.linalg as nplg
da = np.loadtxt("data.csv")
sum= np.sum(da,axis=0)
col_arv = da/sum
w = np.sum(col_arv,axis=1)
w_n = w/np.sum(w)
print w_n
print np.max(nplg.eig(da)[0])输出是:
[ 0.05782808 0.15434974 0.08424087 0.17999077 0.18568877 0.33790177]
(6.16381602081+0j)
其中,第一行就是权重了,第二行就是最大特征值。显然,矩阵的维数是6,跟最大特征值差不多,合理。
PS:如果有什么更好的用户行为分析和量化用户产品偏好的做法,欢迎交流!!!!!!!!!!
参考资料:
http://wiki.mbalib.com/wiki/%E5%B1%82%E6%AC%A1%E5%88%86%E6%9E%90%E6%B3%95
http://courseware.ecnudec.com/zsb/zsx/zsx07/zsx07d/zsx07d000.htm
http://www.tup.tsinghua.edu.cn/Resource/tsyz/035658-01.pdf
http://blog.csdn.net/huruzun/article/details/39801217
http://www.cnblogs.com/broadview/archive/2013/02/27/2934925.html
本文链接:http://blog.csdn.net/lingerlanlan/article/details/41917319
本文作者:linger

相关文章推荐
- 层次分析法量化用户的产品偏好
- 从用户体验的角度说明产品的五个层次
- 产品用户体验的层次
- 互联网产品用户体验的层次详解
- 基于层次分析法的信息安全风险评估量化法的研究报告
- 产品用户体验的五个层次
- 面向用户需求的产品设计
- 如何进行用户与产品直接的个性化推荐?
- 产品销售心理学:要卖给冲动的人!别指望从理性用户身上赚钱
- 超半数用户偏好“棋牌娱乐”类手游
- 让用户对产品上瘾,需要这4个环节
- 产品设计体会(6016)我是哪种用户(下)
- 作为产品运营,如何培养自己的用户思维?
- 《UCD火花集》书评:从卖产品到卖用户体验
- SharedPreferences保存用户偏好参数
- 产品需求分析:用户的“奶酪”不要碰
- toB产品规划的三明治,从用户中来到用户中去
- 互联网产品设计进阶(12)描绘用户心中的海市蜃楼
- AHP层次分析法
- Android之用SharedPreferences来添加用户偏好