SQL Server Profiler -- 性能调校
2014-12-12 11:25
309 查看
SQL Server Profiler -- 性能调校
性能有足够的理由成为一个热点话题。当今商业领域竞争激烈,如果用户认为某个应用程序速度太慢,就会立刻转向另一个供应商。为了满足用户的要求,SQL跟踪加载了一些事件类,可以利用这些事件类来查找和调试性能瓶颈。性能监视技术可以大致分为两个类别:在已知故障相关知识时使用的技术和用来查找故障所在(或者查找到底是否存在故障)的技术。如果查出这个故障的某些问题,就可以在这方面获取更多的信息。因此,从第2种帮助精确定位故障区域的技术开始,然后再讨论怎样进行更详细的分析。
当开始一个新的数据库性能调校工程时,首先要查明的就是哪个查询的效率最低。换言之,要确定最差性能的原因,这样可以找到最佳的调校效果。在这个阶段,不要跟踪太多的信息,通常只启动“Stored Procedures: RPC:Completed”和“TSQL: SQL:BatchCompleted”这两个事件。这些事件都在SQL Server性能分析器提供的TSQL_Duration模板中被选中。建议往这两个事件中添加默认模板中并没有选中的读、写和CPU列,以便获得更加完整的描述。也建议为“Stored Procedures: RPC:Completed”事件选择TextData列而不是(默认的)BinaryData列―这可以使后续处理数据的工作更简单。下图显示了一个完整的给定事件集合。

如果选择了事件,就要在生存期列上设置一个以毫秒计的短时过滤器。使用过的大部分活动OLTP系统都有极其大量的0毫秒查询,且在性能瓶颈方面,这些显然不是最好的。通常从设置为100毫秒的过滤器开始,然后从开始进行工作。方法是增加每次迭代上的信噪比,淘汰较小的查询,只保留有较高潜力进行性能调校的查询。根据应用程序和服务器荷载的不同,通常对每个迭代跟踪运行10~15分钟,然后查看结果并适度地增加这个数值直到在跟踪期间只得到几百个事件为止。这个10~15分钟的数字对于有些特别忙的应用程序来说太长了。
另一个选项是只运行初始跟踪,然后开始过滤结果。简单的方法就是使用SQL Server 2005的NTILE开窗函数,它将输入行分为数目相等的“桶”。如果只查看一个基于生存期的跟踪表里前10%的查询,可以使用如下查询:
SELECT * FROM ( SELECT *, NTILE(10) OVER(ORDER BY Duration) Bucket FROM TraceTable ) x WHERE Bucket = 10
注意:大量看上去很小的(甚至0毫秒的)查询组成的应用程序的执行也可能导致性能故障,但是这个问题一般需要通过移除无用的界面,系统有体系地解决,而不是通过Transact-SQL查询调校。如果不知道一个特定的应用程序的操作,那么通过性能分析查找这类问题也很困难,因此,这里不讨论这个问题。
如果发现很难将获得的返回事件数量限制在一个可控制级别(在忙碌的系统上这是很常见的问题),就不得不对结果做一些调整以使输出聚合得更好一些。从SQL跟踪获得的结果包含了每个查询的未加工文本数据,这些数据包括所有被实际用到的参数。为了进一步分析结果,这些数据应该被载入数据库中的一张表里,然后进行聚合,例如,得出逻辑读的平均生存期或数目。
问题在于如果成功地聚合SQL跟踪结果所返回的未加工文本数据。知道实际的参数有好处,对于重新产生性能问题很有用,但是在试图判断应当首先处理哪个查询前,最好先用查询“表单”聚合这些结果。例如,下列两个查询都是属于同一个表单,使用同样的表和列,只在WHERE子句使用的参数上有差别,但是由于它们的文本不同,因此要聚合它们是不可能的:
SELECT * FROM SomeTable WHERE SomeColumn = 1 --- SELECT * FROM SomeTable WHERE SomeColumn = 2
为了帮助解决这个问题,并将这些查询减少到可以聚合的一个常见表单,提供了一个CLR UDF,稍作修订的版本(也可以处理NULL)如下:
[Microsoft.SqlServer.Server.SqlFunction(IsDeterministic=true)]
Public static SqlString sqlsig(SqlString querystring)
{
Return (SqlString)Regex.Replace(
Querystring.Value,
@”([\s,(=<>!](?![^\]]+[\]](?:(?:(?:(?:(?# expression coming
)(?:(
)?(‘)(?:[^’]’’)*(‘))(?# character
)|(?:0x[\da-fA-F]*)(?# binary
)|(?:[-+]?(?:(?:[\d]*\.[\d]*|[\d]+)(?# precise number
)(?:[eE]?[\d]*)))(?# imprecise number
)|(?:[~]?[-+]?(?:[\d]+))(?# interger
)|(?:[nN][uU][lL][lL])(?# null
))(?:[\s]?[\+\-\*\/\%\&|\^][\s]?)?)+(?# operatoers
)))#,
@”$1$2$3#$4”);
}该UDF查找出大部分像参数的值,用“#”替代。用UDF处理完上面的两个查询后,输出应该一样:
SELET * FROM SomeTable WHERE SomeColumn = #
要用该UDF帮助处理一个跟踪表以找出前几位查询,可以从接下来的查询的某些行开始,该查询聚合了每一个常用的查询表单,并得到了生存期、读、写和CPU的平均值:
SELECT QueryForm, AVG(Duration), AVG(Reads), AVG(Writes), AVG(CPU) FROM ( SELECT Dbo.fn_sqlsig(TextData) AS QueryForm, l.* Duration AS Duration, l.* Reads AS Reads, l.* Writes AS Writes, l.* CPU AS CPU FROM TraceTable WHERE TextData IS NOT NULL ) x GROUP BY QueryForm
在这里,可以进一步用平均值进行过滤,以找出更多查询。
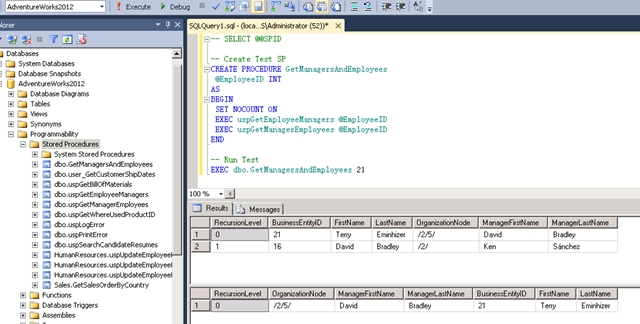
如果决定了对一个或多个查询进行调校,就可以用SQL跟踪来帮助做进一步的分析。例如,假设已经将下列可以在AdventureWorks数据库中创建的存储过程作为故障原因隔离起来的显示:
CREATE PROCEDURE GetManagersAndEmployees @EmployeeID INT AS BEGIN SET NOCOUNT ON EXEC uspGetEmployeeManagers @EmployeeID EXEC uspGetManagerEmployees @EmployeeID END
要开始一个会话以分析该存储过程在做什么,首先要在SQL Server管理工作室中打开一个新的查询窗口,用@@SPID函数获取会话的spid。接下来,打开SQL Server性能分析器,连接到服务器上,并选择调校模板。
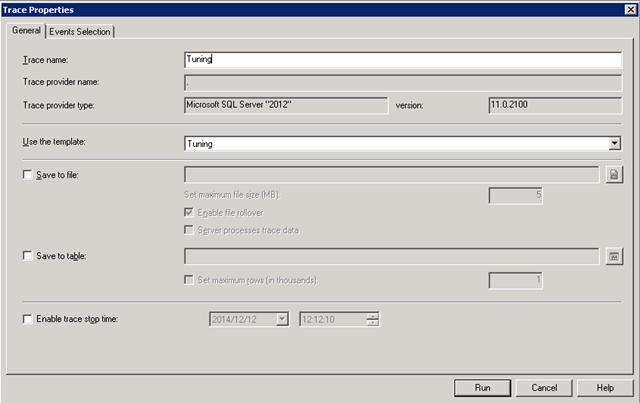
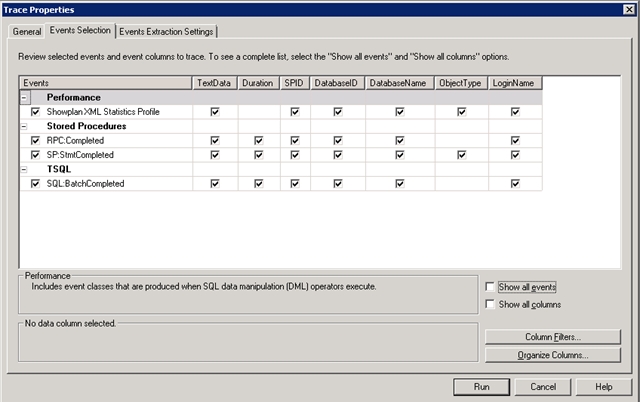
该模板将SP:StmtCompleted添加至用来获取服务器活动更完整描述的事件组合。这将导致每个调用都返回更多的数据,因此要用之前锁收集到的spid来过滤跟踪。用户也可能希望添加显示计划XML统计值性能分析事件,以撤销连同查询剩余信息在内的查询计划。下图显示了此类工作一个完整的事件选择屏幕。
注意:添加一个显示计划XML或死锁图事件会使得跟踪性能对话框中新增一个名为事件提取设置的标签页,这个标签页包括自动保存任何已收集到的查询计划或死锁图XML至文本文件的选项,并可以防止以后需要时重新用到它们。
接下来,继续启动SQL Server性能分析器里的跟踪。尽管通常使用服务器端跟踪做绝大部分的性能监视,但是用单个spid处理单个查询时性能分析器带给表的开销是很小,因此可以为此类工作充分利用UI。下图显示的是启动跟踪和运行@EmployeeID=21查询之后性能分析器的连续输出。选择显示计划XML事件中的一个,以突出该特性的能力。连通最外层存储过程执行的每个语句和调用的所有存储过程一起,用户可以看到在性能分析器UI中有一个完整的图形查询计划。这可使其称为帮助用户调校复杂多层存储过程的一个理想助手。
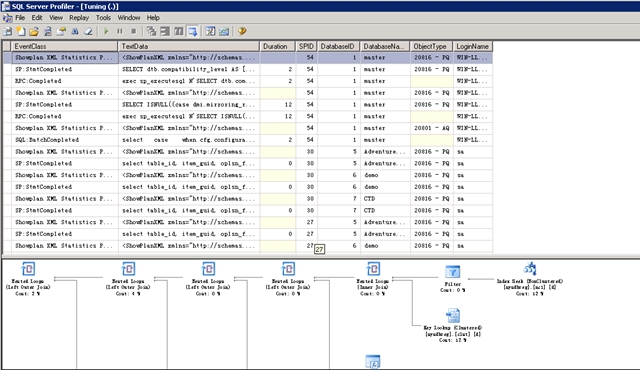
SQL跟踪不会进行实际的调校,但是它能帮助查找可能导致故障的查询,以及这些查询中需要工作的组件。然而,它的功能远不止于性能调校而已。
注意:SQL跟踪并不进行实际调校,SQL Server的数据库引擎优化顾问(DTA)工具可以跟踪一个输入文件,这样就可以在索引、统计值和分区方面帮助用户查询进行得更快。如果使用DTA工具,要确保提供系统通常所处理查询的足够多的样本。如果收集到的样本数目太多,结果就会有偏差,很可能就会导致DTA给出低水平的建议,甚至有可能提供导致其他尚未在输入集合的查询中产生性能故障的建议。
本文出自 “SQL Server Deep Dives” 博客,请务必保留此出处http://ultrasql.blog.51cto.com/9591438/1589152

相关文章推荐
- SqlServer2005 性能调校之 利用Sql Server Profiler捕捉阻塞事件
- SqlServer2005 性能调校之 利用Sql Server Profiler捕捉阻塞事件(转)
- SqlServer2005 性能调校之 利用Sql Server Profiler捕捉阻塞事件
- 数据库性能监测工具——SQL Server Profiler
- Sql2005性能工具(SQL Server Profiler和数据库引擎优化顾问)使用方法详解
- 读书笔记(三):【SQL Server 2005 Performance Tuning性能调校】(0):【开篇】
- 读书笔记(三):【SQL Server 2005 Performance Tuning性能调校】(1):【性能调校概观】
- 读书笔记(三):【SQL Server 2005 Performance Tuning性能调校】(1):【性能调校概观】
- 读书笔记(三):【SQL Server 2005 Performance Tuning性能调校】(2):【SQL Server 架构简介】
- 读书笔记(三):【SQL Server 2005 Performance Tuning性能调校】(2):【SQL Server 架构简介】
- 读书笔记(三):【SQL Server 2005 Performance Tuning性能调校】(2):【SQL Server 架构简介】
- Sql性能检测工具:Sql server profiler和优化工具:Database Engine Tuning Advisor
- 书评 <SQL Server 2005 Performance Tuning性能调校> 竟然能够如此的不用心........
- 转载:【SQL Server 2005 Performance Tuning性能调校】
- SQL SERVER性能调优之四(使用Profiler捕获慢查询)
- SQL Server性能优化(3)使用SQL Server Profiler查询性能瓶颈
- MS SQL 查询数据库中所有索引以及对应的表字段 SQL Server Profiler性能跟踪
- 数据库性能优化-1-使用SQL Server Profiler工具和执行计划分析
- Sql性能检测工具:Sql server profiler和优化工具:Database Engine Tuning Advisor
- SQL Server性能调校的步骤