GPU库伦求和实现
2014-12-03 10:58
267 查看
实验内容
给定一个三维网格空间,空间中网格的坐标为[x,y,z],该空间中有K个原子,分布于网格空间中的任意网格坐标上。设计实现一个并行算法,求出该网格空间中每一个网格点受到的网格空间中的所有原子的库仑力之和。
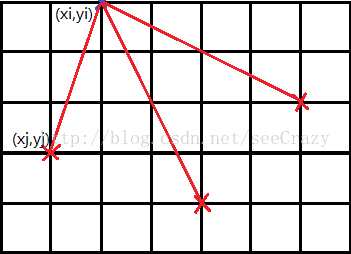
图1
图1显示了一个三维网格空间的切片,在该空间中有三个原子(用红色的叉标注),这三个原子对网格空间中的所有网格点都有库仑力的作用,该二维空间中共有6X8=48个网格点。对于其中的一个网格点(xi,yi)。原子(xj,yj)对该点的库仑力大小Fj为:
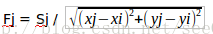
公式1
其中Sj为原子所带的电量。设一个二维网格空间中共有K个原子,则对于网格空间中的任意一个网格点(xi,yi),其所受到的原子库仑力之和为:
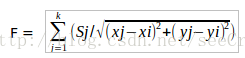
公式2
由问题的描述,我们大致了解了该算法的实现思路,若是要实现CPU上的串行代码,可由以下步骤进行:
输入参数:
floatenergyGrid[][]:在计算时存放每个网格点受到的库仑力之和,并用作输出。
Int m:网格的行数即y方向的维度
Int n:网格的列数即x方向的维度
Struct atomatomarray[]:存放原子信息的结构体数组,structatom的定义为:structatom{int
x, int y, int z, float w};x,y,z为原子的坐标,w为原子带的电量。
Int k:原子的数量。
执行步骤伪代码描述:
for i = 1 to m
for j = 1 to n
for r = 1 to k
energyGrid[i][j] +=atomarray[k].w*sqrt((i–atomarray[r].x)^2+(j– atomarray[r].y)^2 +atomarray[r].z^2)
算法需要遍历每一个网格时间复杂度为O(m*n);对每一个网格,算法需要遍历所有的原子,并进行计算,时间复杂度为O(k);故整个算法时间复杂度是O(m*n*k);并且对于每一个网格切片来说,原子数量的增长是与网格空间的体积成正比的,因为三维网格的任意一个坐标处都可以有原子分布。
本实验的任务就是要实现一个并行的算法,以提高这个问题的执行效率。
2.实验分析
要将这个计算任务并行化,就需要分析这个主问题,找出他的“不相关”子问题,然后给每一个不相关的子问题分配一个单独的线程进行执行;这种“不相关”指的是一个问题的解决不依赖于另一个问题的解决是,一个问题的输出不是另一个问题的输入。
分析这个问题,我们可以知道,这个问题中的组成元素是网格和原子,分别以原子和网格为计算问题的中心,我们可以得到两种计算方案。
方案1:以每一个原子为计算单位,分配一个线程执行。这种方案需要每一个线程ri计算一个原子atomr对网格空间中所有的网格产生的库仑力,由于在这种计算方式中,每一个线程都会访问所有的网格energyGrid[i][j],这就可能出现访问冲突,造成数据的不一致,如tr与tq同时访问energyGrid[i][j]。这就要求每个线程对energyGrid[i][j]的访问是原子操作,但是原子访问操作对性能的影响较大,所以以每一个原子为计算单位的方案并不具有很好的并行性。
方案2:以每一个网格为计算单位,分配一个线程执行。这种方案需要每一个线程tr计算一个网格受到的所有原子的库仑力的和。因为在这种方案中每一个线程tr访问的energyGrid[i][j]是不同的,所以不存在访存冲突;另外,虽然在计算每个网格受到的库仑力时,每一个线程都会访问所有的原子信息。但是对原子信息的访问是只读的,所以不会存在访问冲突,不会引起数据的不一致性。
确定了方案二之后,很快就能得到一个并行的kernel函数算法,每一个kernel函数只需执行一次迭代,即上面的代码中的最内层迭代。外面的两层迭代分配给m*n个线程并行执行,每一个线程网格空间的thread[i][j]对应于二维网格空间中的energyGrid[i][j],kernel函数的实现代码如下:
以上参数的定义与CPU串行代码的定义一致,不同的是此处的energyGrid采用一维数组进行存储;另外增加了一个gridSpace变量,用于表示一个维度上相邻坐标的距离。
算法的前两行完成线程与问题的映射。正如前面所述,整个线程空间里的一个线程唯一对应一个二维网格空间的一个网格点;为了便于问题的对应,本算法将线程的threadGrid设置为二维的,也将threadBlock设置成二维的。(col,row)表示一个线程在整个threadGrid空间中的坐标,该线程处理的数据是energyGrid[row][col]。
算法的5~10行的迭代是计算所有原子对一个网格点的库仑力之和。
最后一行是将求到的一个网格点受到的库仑力之和存入结果数组,row* (gridDim.x
* blockDim.x) + blockIdx.x * blockDim.x +threadIdx.x表示元素energyGrid[row][col]在一维数组中的存储位置的索引。
存储器访问方面的优化:
在上面的算法中,每一个kernel函数执行一层迭代,迭代次数为原子个数numatoms,每一次迭代都需要访问4次全局存储器,这样下来,每一个线程在迭代过程中都要访问4*numatoms次全局存储器;并且由于每个线程都是要按顺序访问所有的原子,所以对于共享存储器来说,也不具备合并访问条件(线程ID相邻的线程访问相邻的数据元素)。
这个地方可以使用常量存储器来加快访问速度,因为常量存储器有缓存,由于一个warp中的所有线程访问相同的元素,当一个warp中的一个线程访问过一个数据之后,该数据就会被放在常量存储器的缓存里,当该warp中的其他的线程再使用该数据时,就可以直接在缓存中取到数据,对缓存的访问几乎与对寄存器的访问一样有效。这又进一步减少了对存储器的访问时间。但是由于常量存储器的容量大小是有限制的64KB,所以当原子数量太多时,我们就需要分几个阶段调用kernel函数,每一个阶段将一部分的原子信息拷贝入常量存储器,完成一个阶段的计算。
指令执行效率优化:
在使用了常量存储器后,存储器带宽限制问题已经得到了很好的解决;然而继续观察代码可以发现每一次迭代任然有4个访存指令的开销,这些指令会消耗硬件资源,而这些硬件资源可以提高浮点计算的吞吐量;所以可以增加线程的执行粒度,即一个线程同时计算多个网格点的库伦值,在计算之前先把原子信息加载到寄存器中,这样可以减少对硬件资源的消耗,并且由于同一行的网格对于任意一个原子来说,y坐标之间的差值是一样的,可以通过计算一次得到。
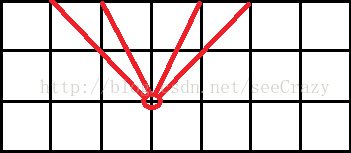
图2
如图2所示,同一行的网格点到一个原子的y坐标之间的差值是相同的。
写入合并的优化:
我们增加了线程的粒度,一个线程执行8个网格点的库伦值,如果一个线程执行的8个网格点是连续的,则不能利用全局存储器合并访问的优势,因为相邻的两个线程之间访问的存储区域不是连续的,相差8个存储单位。为了利用全局存储器合并访问的优势,就得安排ID相邻的线程访问相邻的元素。在本算法的实现中,每个线程执行的网格之间的距离是16,这样就能保证半个Warp的线程能够合并访问存储器。在这种情况下就要求网格的一行网格数为128的整数倍,不然,部分线程会访问出界。
Kernel函数实现算法:
__global__ void computeElectric(float* energyGrid, float gridSpace, int numatoms)
{
1 float coory = (blockIdx.y * blockDim.y + threadIdx.y) * gridSpace;
2 float coorx = (blockIdx.x * BLOCKSIZEX * 8 + threadIdx.x) * gridSpace;
3 int outaddr = (blockIdx.y * blockDim.y + threadIdx.y) * (gridDim.x * BLOCKSIZEX * 8) + blockIdx.x * BLOCKSIZEX * 8 + threadIdx.x;
4 float gridspacing_coalesce = gridSpace * BLOCKSIZEX;
5 int atomid;
6 float energyvalx1 = 0.0f;
7 float energyvalx2 = 0.0f;
8 float energyvalx3 = 0.0f;
9 float energyvalx4 = 0.0f;
10 float energyvalx5 = 0.0f;
11 float energyvalx6 = 0.0f;
12 float energyvalx7 = 0.0f;
13 float energyvalx8 = 0.0f;
14 for(atomid = 0; atomid < numatoms; atomid ++)
15 {
16 float dy = coory - atominfo[atomid].y;
17 float dyz2 = (dy * dy) + atominfo[atomid].z;
18 float dx1 = coorx - atominfo[atomid].x;
19 float dx2 = gridspacing_coalesce + dx1;
20 float dx3 = gridspacing_coalesce + dx2;
21 float dx4 = gridspacing_coalesce + dx3;
22 float dx5 = gridspacing_coalesce + dx4;
23 float dx6 = gridspacing_coalesce + dx5;
24 float dx7 = gridspacing_coalesce + dx6;
25 float dx8 = gridspacing_coalesce + dx7;
26 energyvalx1 += atominfo[atomid].w * rsqrtf(dx1 * dx1 + dyz2);
27 energyvalx2 += atominfo[atomid].w * rsqrtf(dx2 * dx2 + dyz2);
28 energyvalx3 += atominfo[atomid].w * rsqrtf(dx3 * dx3 + dyz2);
29 energyvalx4 += atominfo[atomid].w * rsqrtf(dx4 * dx4 + dyz2);
30 energyvalx5 += atominfo[atomid].w * rsqrtf(dx5 * dx5 + dyz2);
31 energyvalx6 += atominfo[atomid].w * rsqrtf(dx6 * dx6 + dyz2);
32 energyvalx7 += atominfo[atomid].w * rsqrtf(dx7 * dx7 + dyz2);
33 energyvalx8 += atominfo[atomid].w * rsqrtf(dx8 * dx8 + dyz2);
34 }
35 energyGrid[outaddr] += energyvalx1;
36 energyGrid[outaddr + BLOCKSIZEX] += energyvalx2;
37 energyGrid[outaddr + BLOCKSIZEX * 2] += energyvalx3;
38 energyGrid[outaddr + BLOCKSIZEX * 3] += energyvalx4;
39 energyGrid[outaddr + BLOCKSIZEX * 4] += energyvalx5;
40 energyGrid[outaddr + BLOCKSIZEX * 5] += energyvalx6;
41 energyGrid[outaddr + BLOCKSIZEX * 6] += energyvalx7;
42 energyGrid[outaddr + BLOCKSIZEX * 7] += energyvalx8;
}
上面代码中的BLOCKSIZEX值得大小为16。
经过最终的改动,代码中的浮点数运算指令数与访问全局存储器的指令数的比值大大增加,与原来的代码相比,每完成8个网格的库伦力的计算,访问存储器的指令数,冗余计算的指令数量都大大减小。
程序运行结果截图如下:
输入:512(m) 512(n) 10000(k)
图3
注:
本实验是《大规模并行处理器编程实战》上面的案例,试验中的算法思想都是参考书中的内容。在学习了该模块的内容后,自己动手实现了该算法。
给定一个三维网格空间,空间中网格的坐标为[x,y,z],该空间中有K个原子,分布于网格空间中的任意网格坐标上。设计实现一个并行算法,求出该网格空间中每一个网格点受到的网格空间中的所有原子的库仑力之和。
图1
图1显示了一个三维网格空间的切片,在该空间中有三个原子(用红色的叉标注),这三个原子对网格空间中的所有网格点都有库仑力的作用,该二维空间中共有6X8=48个网格点。对于其中的一个网格点(xi,yi)。原子(xj,yj)对该点的库仑力大小Fj为:
公式1
其中Sj为原子所带的电量。设一个二维网格空间中共有K个原子,则对于网格空间中的任意一个网格点(xi,yi),其所受到的原子库仑力之和为:
公式2
由问题的描述,我们大致了解了该算法的实现思路,若是要实现CPU上的串行代码,可由以下步骤进行:
输入参数:
floatenergyGrid[][]:在计算时存放每个网格点受到的库仑力之和,并用作输出。
Int m:网格的行数即y方向的维度
Int n:网格的列数即x方向的维度
Struct atomatomarray[]:存放原子信息的结构体数组,structatom的定义为:structatom{int
x, int y, int z, float w};x,y,z为原子的坐标,w为原子带的电量。
Int k:原子的数量。
执行步骤伪代码描述:
for i = 1 to m
for j = 1 to n
for r = 1 to k
energyGrid[i][j] +=atomarray[k].w*sqrt((i–atomarray[r].x)^2+(j– atomarray[r].y)^2 +atomarray[r].z^2)
算法需要遍历每一个网格时间复杂度为O(m*n);对每一个网格,算法需要遍历所有的原子,并进行计算,时间复杂度为O(k);故整个算法时间复杂度是O(m*n*k);并且对于每一个网格切片来说,原子数量的增长是与网格空间的体积成正比的,因为三维网格的任意一个坐标处都可以有原子分布。
本实验的任务就是要实现一个并行的算法,以提高这个问题的执行效率。
2.实验分析
要将这个计算任务并行化,就需要分析这个主问题,找出他的“不相关”子问题,然后给每一个不相关的子问题分配一个单独的线程进行执行;这种“不相关”指的是一个问题的解决不依赖于另一个问题的解决是,一个问题的输出不是另一个问题的输入。
分析这个问题,我们可以知道,这个问题中的组成元素是网格和原子,分别以原子和网格为计算问题的中心,我们可以得到两种计算方案。
方案1:以每一个原子为计算单位,分配一个线程执行。这种方案需要每一个线程ri计算一个原子atomr对网格空间中所有的网格产生的库仑力,由于在这种计算方式中,每一个线程都会访问所有的网格energyGrid[i][j],这就可能出现访问冲突,造成数据的不一致,如tr与tq同时访问energyGrid[i][j]。这就要求每个线程对energyGrid[i][j]的访问是原子操作,但是原子访问操作对性能的影响较大,所以以每一个原子为计算单位的方案并不具有很好的并行性。
方案2:以每一个网格为计算单位,分配一个线程执行。这种方案需要每一个线程tr计算一个网格受到的所有原子的库仑力的和。因为在这种方案中每一个线程tr访问的energyGrid[i][j]是不同的,所以不存在访存冲突;另外,虽然在计算每个网格受到的库仑力时,每一个线程都会访问所有的原子信息。但是对原子信息的访问是只读的,所以不会存在访问冲突,不会引起数据的不一致性。
确定了方案二之后,很快就能得到一个并行的kernel函数算法,每一个kernel函数只需执行一次迭代,即上面的代码中的最内层迭代。外面的两层迭代分配给m*n个线程并行执行,每一个线程网格空间的thread[i][j]对应于二维网格空间中的energyGrid[i][j],kernel函数的实现代码如下:
__global__ void computeElectric_v1(float* energyGrid, atom* patoms, float gridSpace, int numatoms)
{
1 int row = blockIdx.y * blockDim.y + threadIdx.y;
2 int col = blockIdx.x * blockDim.x + threadIdx.x;
3 int atomid;
4 float energyVal = 0.0f;
5 for(atomid = 0; atomid < numatoms; atomid++)
6 {
7 float dy = row * gridSpace - patoms[atomid].y;
8 float dx = col * gridSpace - patoms[atomid].x;
9 energyVal += patoms[atomid].w * rsqrtf(dy * dy + dx * dx + patoms[atomid].z);
10 }
11 energyGrid[row * (gridDim.x * blockDim.x) + blockIdx.x * blockDim.x + threadIdx.x] = energyVal;
}以上参数的定义与CPU串行代码的定义一致,不同的是此处的energyGrid采用一维数组进行存储;另外增加了一个gridSpace变量,用于表示一个维度上相邻坐标的距离。
算法的前两行完成线程与问题的映射。正如前面所述,整个线程空间里的一个线程唯一对应一个二维网格空间的一个网格点;为了便于问题的对应,本算法将线程的threadGrid设置为二维的,也将threadBlock设置成二维的。(col,row)表示一个线程在整个threadGrid空间中的坐标,该线程处理的数据是energyGrid[row][col]。
算法的5~10行的迭代是计算所有原子对一个网格点的库仑力之和。
最后一行是将求到的一个网格点受到的库仑力之和存入结果数组,row* (gridDim.x
* blockDim.x) + blockIdx.x * blockDim.x +threadIdx.x表示元素energyGrid[row][col]在一维数组中的存储位置的索引。
存储器访问方面的优化:
在上面的算法中,每一个kernel函数执行一层迭代,迭代次数为原子个数numatoms,每一次迭代都需要访问4次全局存储器,这样下来,每一个线程在迭代过程中都要访问4*numatoms次全局存储器;并且由于每个线程都是要按顺序访问所有的原子,所以对于共享存储器来说,也不具备合并访问条件(线程ID相邻的线程访问相邻的数据元素)。
这个地方可以使用常量存储器来加快访问速度,因为常量存储器有缓存,由于一个warp中的所有线程访问相同的元素,当一个warp中的一个线程访问过一个数据之后,该数据就会被放在常量存储器的缓存里,当该warp中的其他的线程再使用该数据时,就可以直接在缓存中取到数据,对缓存的访问几乎与对寄存器的访问一样有效。这又进一步减少了对存储器的访问时间。但是由于常量存储器的容量大小是有限制的64KB,所以当原子数量太多时,我们就需要分几个阶段调用kernel函数,每一个阶段将一部分的原子信息拷贝入常量存储器,完成一个阶段的计算。
指令执行效率优化:
在使用了常量存储器后,存储器带宽限制问题已经得到了很好的解决;然而继续观察代码可以发现每一次迭代任然有4个访存指令的开销,这些指令会消耗硬件资源,而这些硬件资源可以提高浮点计算的吞吐量;所以可以增加线程的执行粒度,即一个线程同时计算多个网格点的库伦值,在计算之前先把原子信息加载到寄存器中,这样可以减少对硬件资源的消耗,并且由于同一行的网格对于任意一个原子来说,y坐标之间的差值是一样的,可以通过计算一次得到。
图2
如图2所示,同一行的网格点到一个原子的y坐标之间的差值是相同的。
写入合并的优化:
我们增加了线程的粒度,一个线程执行8个网格点的库伦值,如果一个线程执行的8个网格点是连续的,则不能利用全局存储器合并访问的优势,因为相邻的两个线程之间访问的存储区域不是连续的,相差8个存储单位。为了利用全局存储器合并访问的优势,就得安排ID相邻的线程访问相邻的元素。在本算法的实现中,每个线程执行的网格之间的距离是16,这样就能保证半个Warp的线程能够合并访问存储器。在这种情况下就要求网格的一行网格数为128的整数倍,不然,部分线程会访问出界。
Kernel函数实现算法:
__global__ void computeElectric(float* energyGrid, float gridSpace, int numatoms)
{
1 float coory = (blockIdx.y * blockDim.y + threadIdx.y) * gridSpace;
2 float coorx = (blockIdx.x * BLOCKSIZEX * 8 + threadIdx.x) * gridSpace;
3 int outaddr = (blockIdx.y * blockDim.y + threadIdx.y) * (gridDim.x * BLOCKSIZEX * 8) + blockIdx.x * BLOCKSIZEX * 8 + threadIdx.x;
4 float gridspacing_coalesce = gridSpace * BLOCKSIZEX;
5 int atomid;
6 float energyvalx1 = 0.0f;
7 float energyvalx2 = 0.0f;
8 float energyvalx3 = 0.0f;
9 float energyvalx4 = 0.0f;
10 float energyvalx5 = 0.0f;
11 float energyvalx6 = 0.0f;
12 float energyvalx7 = 0.0f;
13 float energyvalx8 = 0.0f;
14 for(atomid = 0; atomid < numatoms; atomid ++)
15 {
16 float dy = coory - atominfo[atomid].y;
17 float dyz2 = (dy * dy) + atominfo[atomid].z;
18 float dx1 = coorx - atominfo[atomid].x;
19 float dx2 = gridspacing_coalesce + dx1;
20 float dx3 = gridspacing_coalesce + dx2;
21 float dx4 = gridspacing_coalesce + dx3;
22 float dx5 = gridspacing_coalesce + dx4;
23 float dx6 = gridspacing_coalesce + dx5;
24 float dx7 = gridspacing_coalesce + dx6;
25 float dx8 = gridspacing_coalesce + dx7;
26 energyvalx1 += atominfo[atomid].w * rsqrtf(dx1 * dx1 + dyz2);
27 energyvalx2 += atominfo[atomid].w * rsqrtf(dx2 * dx2 + dyz2);
28 energyvalx3 += atominfo[atomid].w * rsqrtf(dx3 * dx3 + dyz2);
29 energyvalx4 += atominfo[atomid].w * rsqrtf(dx4 * dx4 + dyz2);
30 energyvalx5 += atominfo[atomid].w * rsqrtf(dx5 * dx5 + dyz2);
31 energyvalx6 += atominfo[atomid].w * rsqrtf(dx6 * dx6 + dyz2);
32 energyvalx7 += atominfo[atomid].w * rsqrtf(dx7 * dx7 + dyz2);
33 energyvalx8 += atominfo[atomid].w * rsqrtf(dx8 * dx8 + dyz2);
34 }
35 energyGrid[outaddr] += energyvalx1;
36 energyGrid[outaddr + BLOCKSIZEX] += energyvalx2;
37 energyGrid[outaddr + BLOCKSIZEX * 2] += energyvalx3;
38 energyGrid[outaddr + BLOCKSIZEX * 3] += energyvalx4;
39 energyGrid[outaddr + BLOCKSIZEX * 4] += energyvalx5;
40 energyGrid[outaddr + BLOCKSIZEX * 5] += energyvalx6;
41 energyGrid[outaddr + BLOCKSIZEX * 6] += energyvalx7;
42 energyGrid[outaddr + BLOCKSIZEX * 7] += energyvalx8;
}
上面代码中的BLOCKSIZEX值得大小为16。
经过最终的改动,代码中的浮点数运算指令数与访问全局存储器的指令数的比值大大增加,与原来的代码相比,每完成8个网格的库伦力的计算,访问存储器的指令数,冗余计算的指令数量都大大减小。
程序运行结果截图如下:
输入:512(m) 512(n) 10000(k)
图3
注:
本实验是《大规模并行处理器编程实战》上面的案例,试验中的算法思想都是参考书中的内容。在学习了该模块的内容后,自己动手实现了该算法。

相关文章推荐
- [菜鸟每天来段CUDA_C]GPU上实现任意长度的矢量求和
- 《GPU高性能编程CUDA实战》—— 《笔记一》——使用线程实现GPU上的矢量求和
- 为文本字段实现类似"求和"的效果
- 一个实现自动求和/合并单元格/排序的DataGrid
- CUDA硬件实现分析(二)------规行矩步------GPU的革命
- 基于GPU的粒子系统实现概要
- 用while、do-while和for语句实现累计求和
- 模仿草的运动 – GPU(Pixel Shader & Vertex Shader)实现(转)
- 为文本字段实现类似"求和"的效果
- 基于GPU实现的经典光照模型算法:漫反射模型(使用cg语言实现)
- GPU实现“Blinn-Phong 光照模型”(Cg语言)
- 一个实现自动求和/合并单元格/排序的DataGrid
- [导入]javascript 实现像excel样的自动求和功能。(初学的可以看看)
- 一个实现自动求和/合并单元格/排序的DataGrid
- CUDA硬件实现分析(二)------规行矩步------GPU的革命 推荐
- 用GPU实现Cellular Texture (转)
- 利用GPU实现通用计算
- javascript 实现像excel样的自动求和功能。(初学的可以看看)
- 一个实现自动求和、合并单元格、排序的DataGrid(转)
- Excel:如何使用函数实现多表多条件汇总求和