使用BeautifulSoup轻松获取url及其内容
2014-11-26 11:24
309 查看
1、环境:系统Win7 x64,Python 2.7。
2、示例代码:
相关阅读:
1、bs4官方文档 。
2、readthedocs
3、Windows下安装失败
4、lxml官网
5、BeautifulSoup深度优先遍历:https://www.crummy.com/software/BeautifulSoup/bs4/doc/#descendants
6、BeautifulSoup广度优先遍历:How to do a Breadth First Search easily with beautiful soup?
*** walker * 2014-11-26 ***
2、示例代码:
#encoding: utf-8
#author: walker
#date: 2014-11-26
#summary: 使用BeautifulSoup获取url及其内容
import sys, re, requests, urllib
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding('utf8')
#给定关键词,获取百度搜索的结果
def GetList(keyword):
keyword = unicode(keyword, 'gb18030')
dic = {'wd': keyword}
urlwd = urllib.urlencode(dic)
print(urlwd)
sn = requests.Session()
url = 'http://www.baidu.com/s?ie=utf-8&csq=1&pstg=22&mod=2&isbd=1&cqid=9c0f47b700036f17&istc=8560&ver=0ApvSgUI_ODaje7cp4DVye9X2LZqWiCPEIS&chk=54753dd5&isid=BD651248E4C31919&'
url += urlwd
url += '&ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&rsv_pq=b05765d70003b6c0&rsv_t=ce54Z5LOdER%2Fagxs%2FORKVsCT6cE0zvMTaYpqpgprhExMhsqDACiVefXOze4&_ck=145469.1.129.57.22.735.37'
r = sn.get(url=url)
soup = BeautifulSoup(r.content) #r.text很可能中文乱码
rtn = soup.find('div',id='content_left').find_all(name='a',href=re.compile('baidu.com'))
for item in rtn:
print(item.getText().encode('gb18030'))
print(item['href'])
if __name__ == '__main__':
keyword = '正则表达式'
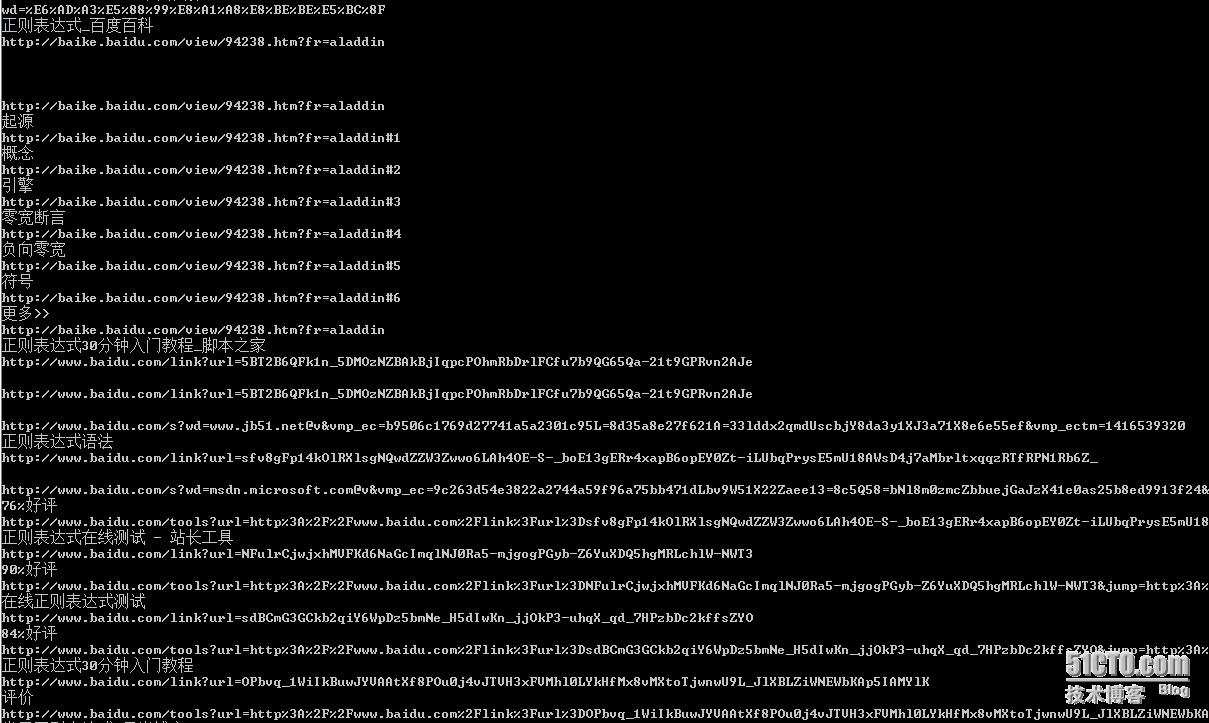
GetList(keyword)3、运行结果截图:相关阅读:
1、bs4官方文档 。
2、readthedocs
3、Windows下安装失败
4、lxml官网
5、BeautifulSoup深度优先遍历:https://www.crummy.com/software/BeautifulSoup/bs4/doc/#descendants
6、BeautifulSoup广度优先遍历:How to do a Breadth First Search easily with beautiful soup?
*** walker * 2014-11-26 ***

相关文章推荐
- Delphi使用IdHttp 获取 HttpsURL内容
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
- JSON的使用:获取url地址内容添加至ListView控件中
- 使用UrlConnection请求一个url地址获取内容
- Python获取网页指定内容(BeautifulSoup工具的使用方法)
- Delphi使用IdHttp 获取 HttpsURL内容
- Java使用URL获取网页内容
- Demo16 :获取一个URL文本(使用URL类构造一个输入对象并读取其内容)
- Python获取网页指定内容(BeautifulSoup工具的使用方法)
- 使用HttpURLConnection获取网页内容
- 使用jQuery.get(url,[data],[callback])不能获取返回的页面XML内容
- VC++中使用使用winnet类获取网页内容
- 使用HttpURLConnection开发自动发送Get、Post请求并获取响应
- Java 获取URL的内容
- 使用javascript在html中获取url参数的脚本
- Windows XP中轻松获取未使用的IP地址
- 使用javascript获取Url的参
- 获取并使用通过Downloader对象下载的内容
- 使用获取url中的文件名和传过来的值
- 使用MFC获取网页内容