svm中的数学和算法
2014-11-18 23:33
246 查看
转载自:http://blog.csdn.net/sealyao/article/details/6442403
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
1.1二维空间
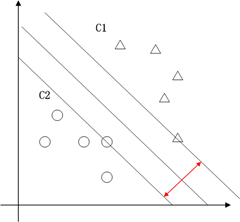
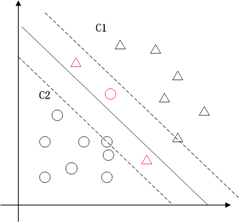
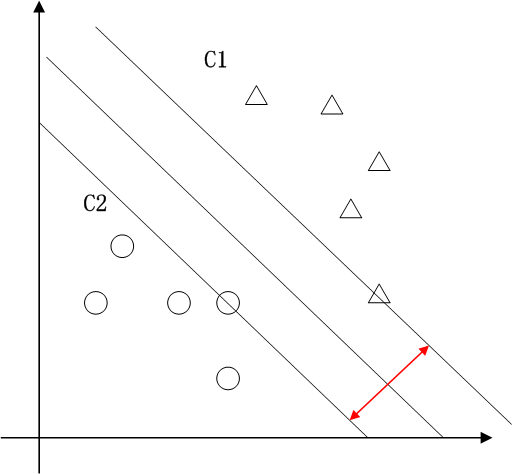
支持向量机的典型应用是分类,用于解决这样的问题:有一些事物是可以被分类的,但是具体怎么分类的我们又说不清楚,比如说下图中三角的就是C1类,圆圈的就是C2类,这都是已知的,好,又来了一个方块,这个方块是属于C1呢还是属于C2呢,说不清楚。SVM算法就是试着帮您把这件事情说清楚的。
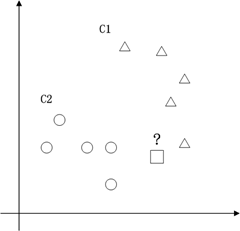
在二维空间里(这时候样本有两个参照属性),SVM就是在C1和C2中间划一条线g(x)=0,线儿上边的属于C1类,线儿下边的属于C2类,这时候方块再来,咱就有章程了。
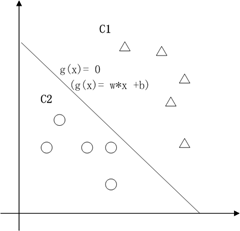
关于g(x) = 0得再啰嗦几句,g(x)里边的x不是横坐标,而是一个向量,
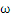
也不是解析几何里边的斜率,也是向量。
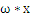
是一个向量积。比如在解析几何意义上的直线y
= -x-b,换成向量表示法就是

,这里w就是那个
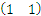
,x就是那个
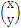
。
对C1类中的点:g(x) > 0;对于 C2类中的点:g(x) < 0 ;
如果我们用y来表示类型,+1代表C1类,-1代表C2类。
那么对于所有训练样本而言,都有:
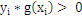
,那么g(x)
= 0 就能够正确分割所有训练样本的那条线,只要把g(x) = 0这条线给找出来就能凑合用了。
这也就只能凑合用,因为满足这个条件的g(x) = 0 太多了,追求完美的我们要的是最优的那条线。怎么才是最优的呢?直觉告诉我们g(x) = 0这条线不偏向C1那边,也不偏向C2那边,就应该是最优的了吧。对,学名叫分类间隔,下图红线的长度就是分类间隔。
在二维空间中,求分类间隔,可以转化为求点到线的距离,点到线的距离可以表示为
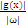
(向量表示)。为简单计,把整个二维空间归一化(等比放大或缩小),使得对于所有的样本,都有|g(x)|>=1,也就是让C1和C2类中离g(x)=0最近的训练样本的|g(x)|=1,这时分类间隔就是
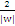
,这个间隔越大越好,那么|
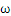
|越小越好。
1.2多维空间
现在我们已经在2维空间中抽象出一个数学问题,求满足如下条件的g(x)=0:
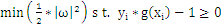
,即在满足
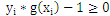
条件下能使
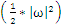
取最小值的那个w。在二维空间中,w可以近似的理解为斜率,在样本确定,斜率确定的情况下,
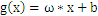
中的那个b也是可以确定的,整个

=
0也就确定了。
现在我们讨论的只是二维空间,但是我们惊喜的发现,在二维空间中的结论可以很容易的推广到多维空间。比如说:
我们仍然可以把多维空间中的分割面(超平面)表示为
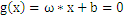
。
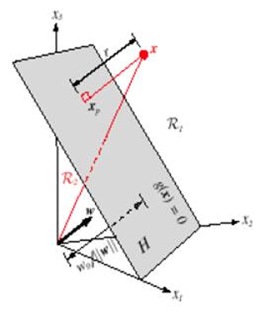
多维空间中点到面的距离仍然可以表示为
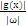
。如下图,平面表示为
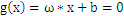
,x是
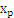
在面上的投影,r是x到面的距离,简单推导如下:
w向量垂直于平面
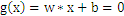
,有:
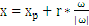
,把上式带入
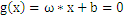
中得到
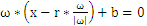
,化简得到
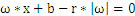
,所以
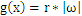
,向量x到平面
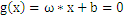
的距离
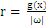
,这和二维空间中结论也是一致的。
现在我们把SVM从2维空间推广到多维空间,即求满足如下条件的g(x)=0:
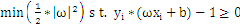
。
1.3拉格朗日因子
这是一个典型的带约束条件的求极值问题,目标函数是
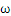
的二次函数,约束函数是
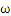
的线性函数:二次规划问题。求解二次规划问题的一般性方法就是添加拉格朗日乘子,构造拉格朗日函数(理论上这儿应该还有一些额外的数学条件,拉格朗日法才是可用,就略过了)。
具体求解步骤如下:
1、构造拉格朗日函数
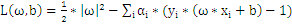
其中

和b是未知量。
2、对
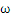
和b求偏导数,令偏导数为0。
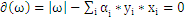
,
即
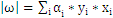
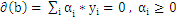
3、把上式带回拉格朗日函数,得到拉格朗日对偶问题,把问题转化为求解
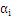
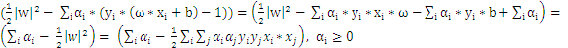
4、最后把问题转化为求解满足下列等式的
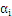
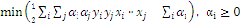
1.4线性化
好,现在我们再来梳理一下svm的分类逻辑,在空间中找一个分割面(线)把样本点分开,分割面(线)的最优条件就是分类间隔最大化,分类间隔是基于点到平面(直线)的距离来计算的。问题是所有的分割面都是平面,所有的分割线都是直线吗?显然不是。
比如特征是房子的面积x,这里的x是实数,结果y是房子的价格。假设我们从样本点的分布中看到x和y符合3次曲线,那么我们希望使用x的三次多项式来逼近这些样本点。
在二维空间中这是非线性的,这样我们前面的推理都没法用了------点到曲线的距离?不知道怎么算。但是如果把x映射到3维空间
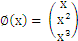
,那么对于
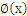
来说,
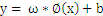
就是线性的,也就是说,对于低维空间中非线性的线(面),在映射到高维空间中时,就能变成线性的。于是我们还需要把问题做一个小小的修正,我们面临的问题是求解:
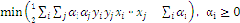
,这里面引入了一个Kernel,核函数,用于样本空间的线性化。
1.5松弛变量
上面就是一个比较完整的推导过程,但是经验表明把上述条件丢给计算机进行求解,基本上是无解的,因为条件太苛刻了。实际上,最经常出现的情况如下图红色部分,在分类过程中会出现噪声,如果对噪声零容忍那么很有可能导致分类无解。
为了解决这个问题又引入了松弛变量。把原始问题修正为:
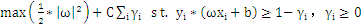
按照拉格朗日法引入拉格朗日因子:
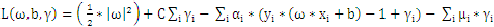
对上式分别求
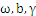
的导数得到:
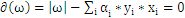
,
即
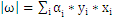
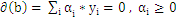
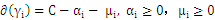
带回
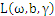
得到拉格朗日的对偶问题:
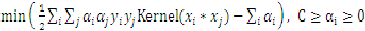
另外当目标函数取极值时,约束条件一定是位于约束边界(KKT条件),也就是说:
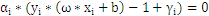
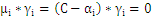
分析上面式子可以得出以下结论:
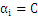
时:
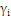
可以不为零,就是说该点到分割面的距离小于
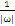
,是误分点。
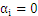
时:
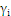
为零,
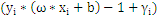
大于零:表示该点到分割面的距离大于
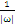
是正确分类点。

时:
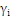
为零,

,该点就是支持向量。
再用数学语言提炼一下:
令
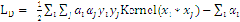
,其对
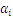
的偏导数为:
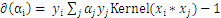
。
KKT条件可以表示为:
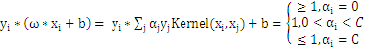
用
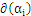
表示该KKT条件就是:
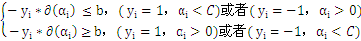
若
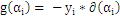
,则
所有的
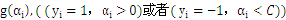
大于所有的
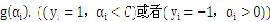
。这里b作为中间数被忽略了,因为b是可以由

推导得到的。
对于样本数量比较多的时候(几千个),SVM所需要的内存是计算机所不能承受的。目前,对于这个问题的解决方法主要有两种:块算法和分解算法。这里,libSVM采用的是分解算法中的SMO(串行最小化)方法,其每次训练都只选择两个样本。基本流程如下:
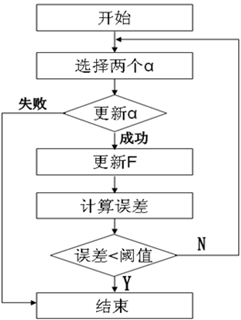
这里有两个重要的算法,一个是
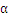
的选择,另一个是
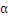
的更新。
2.1
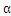
的选择算法
选择两个和KKT条件违背的最严重的两个

,包含两层循环:
外层循环:优先选择遍历非边界样本,因为非边界样本更有可能需要调整,而边界样本常常不能得到进一步调整而留在边界上。在遍历过程中找出
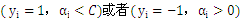
的所有样本中
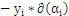
值最大的那个(这个样本是最有可能不满足
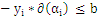
条件的样本。
内层循环:对于外层循环中选定的那个样本
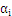
,找到这样的样本

,使得:
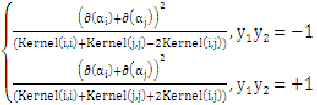

最大,上式是更新
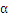
中的一个算式,表示的是在选定
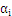
,
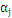
最为更新算子的情况下,
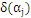
最大。
如果选择
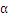
的过程中发现KKT条件已经满足了,那么算法结束。
2.2
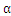
的更新算法
由于SMO每次都只选择2个样本,那么等式约束可以转化为直线约束:
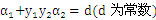
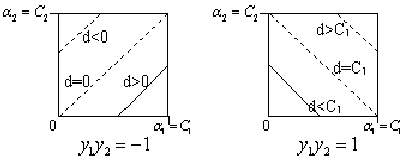
转化为图形表示为:
那么
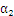
的取值范围是:
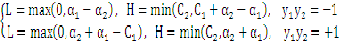
把
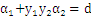
带入
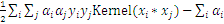
中,得到一个一元二次方程,求极值得到:
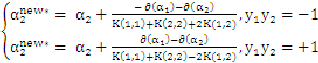
最终:
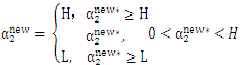
2.3其他
上面说到SVM用到的内存巨大,另一个缺陷就是计算速度,因为数据大了,计算量也就大,很显然计算速度就会下降。因此,一个好的方式就是在计算过程中逐步去掉不参与计算的数据。因为,实践证明,在训练过程中,
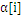
一旦达到边界(
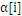
=0或者
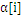
=C),

的值就不会变,随着训练的进行,参与运算的样本会越来越少,SVM最终结果的支持向量(0<
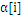
LibSVM采用的策略是在计算过程中,检测active_size中的
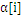
值,如果
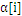
到了边界,那么就应该把相应的样本去掉(变成inactived),并放到栈的尾部,从而逐步缩小active_size的大小。
b的计算 ,基本计算公式为:

理论上,b的值是不定的。当程序达到最优后,只要用任意一个标准支持向量机(0<
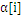
<C)的样本带入上式,得到的b值都是可以的。目前,求b的方法也有很多种。在libSVM中,分别对y=+1和y=-1的两类所有支持向量求b,然后取平均值。
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
一、数学部分
1.1二维空间支持向量机的典型应用是分类,用于解决这样的问题:有一些事物是可以被分类的,但是具体怎么分类的我们又说不清楚,比如说下图中三角的就是C1类,圆圈的就是C2类,这都是已知的,好,又来了一个方块,这个方块是属于C1呢还是属于C2呢,说不清楚。SVM算法就是试着帮您把这件事情说清楚的。

在二维空间里(这时候样本有两个参照属性),SVM就是在C1和C2中间划一条线g(x)=0,线儿上边的属于C1类,线儿下边的属于C2类,这时候方块再来,咱就有章程了。
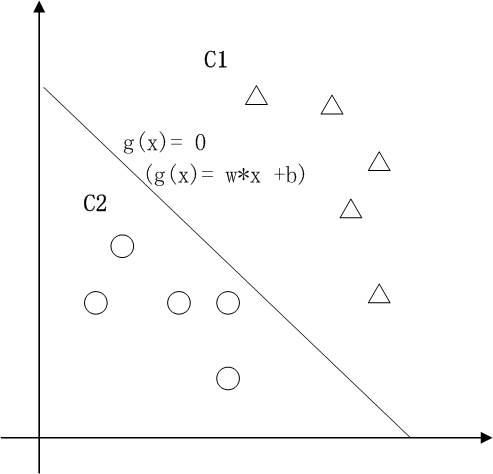
关于g(x) = 0得再啰嗦几句,g(x)里边的x不是横坐标,而是一个向量,
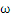
也不是解析几何里边的斜率,也是向量。
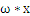
是一个向量积。比如在解析几何意义上的直线y
= -x-b,换成向量表示法就是

,这里w就是那个
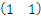
,x就是那个
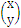
。
对C1类中的点:g(x) > 0;对于 C2类中的点:g(x) < 0 ;
如果我们用y来表示类型,+1代表C1类,-1代表C2类。
那么对于所有训练样本而言,都有:
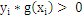
,那么g(x)
= 0 就能够正确分割所有训练样本的那条线,只要把g(x) = 0这条线给找出来就能凑合用了。
这也就只能凑合用,因为满足这个条件的g(x) = 0 太多了,追求完美的我们要的是最优的那条线。怎么才是最优的呢?直觉告诉我们g(x) = 0这条线不偏向C1那边,也不偏向C2那边,就应该是最优的了吧。对,学名叫分类间隔,下图红线的长度就是分类间隔。
在二维空间中,求分类间隔,可以转化为求点到线的距离,点到线的距离可以表示为
(向量表示)。为简单计,把整个二维空间归一化(等比放大或缩小),使得对于所有的样本,都有|g(x)|>=1,也就是让C1和C2类中离g(x)=0最近的训练样本的|g(x)|=1,这时分类间隔就是

,这个间隔越大越好,那么|

|越小越好。
1.2多维空间
现在我们已经在2维空间中抽象出一个数学问题,求满足如下条件的g(x)=0:
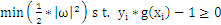
,即在满足

条件下能使

取最小值的那个w。在二维空间中,w可以近似的理解为斜率,在样本确定,斜率确定的情况下,
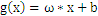
中的那个b也是可以确定的,整个

=
0也就确定了。
现在我们讨论的只是二维空间,但是我们惊喜的发现,在二维空间中的结论可以很容易的推广到多维空间。比如说:
我们仍然可以把多维空间中的分割面(超平面)表示为

。
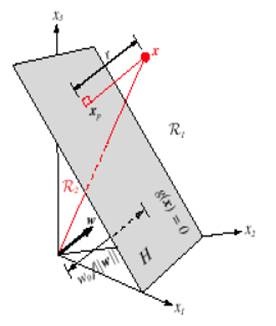
多维空间中点到面的距离仍然可以表示为

。如下图,平面表示为

,x是
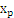
在面上的投影,r是x到面的距离,简单推导如下:
w向量垂直于平面
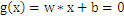
,有:

,把上式带入
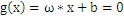
中得到
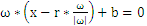
,化简得到
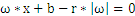
,所以
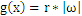
,向量x到平面
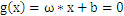
的距离

,这和二维空间中结论也是一致的。
现在我们把SVM从2维空间推广到多维空间,即求满足如下条件的g(x)=0:
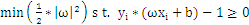
。
1.3拉格朗日因子
这是一个典型的带约束条件的求极值问题,目标函数是
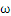
的二次函数,约束函数是
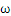
的线性函数:二次规划问题。求解二次规划问题的一般性方法就是添加拉格朗日乘子,构造拉格朗日函数(理论上这儿应该还有一些额外的数学条件,拉格朗日法才是可用,就略过了)。
具体求解步骤如下:
1、构造拉格朗日函数
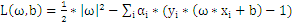
其中
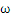
和b是未知量。
2、对
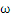
和b求偏导数,令偏导数为0。
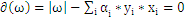
,
即

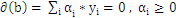
3、把上式带回拉格朗日函数,得到拉格朗日对偶问题,把问题转化为求解
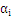

4、最后把问题转化为求解满足下列等式的
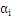
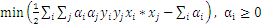
1.4线性化
好,现在我们再来梳理一下svm的分类逻辑,在空间中找一个分割面(线)把样本点分开,分割面(线)的最优条件就是分类间隔最大化,分类间隔是基于点到平面(直线)的距离来计算的。问题是所有的分割面都是平面,所有的分割线都是直线吗?显然不是。
比如特征是房子的面积x,这里的x是实数,结果y是房子的价格。假设我们从样本点的分布中看到x和y符合3次曲线,那么我们希望使用x的三次多项式来逼近这些样本点。
在二维空间中这是非线性的,这样我们前面的推理都没法用了------点到曲线的距离?不知道怎么算。但是如果把x映射到3维空间
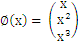
,那么对于
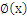
来说,

就是线性的,也就是说,对于低维空间中非线性的线(面),在映射到高维空间中时,就能变成线性的。于是我们还需要把问题做一个小小的修正,我们面临的问题是求解:

,这里面引入了一个Kernel,核函数,用于样本空间的线性化。
1.5松弛变量
上面就是一个比较完整的推导过程,但是经验表明把上述条件丢给计算机进行求解,基本上是无解的,因为条件太苛刻了。实际上,最经常出现的情况如下图红色部分,在分类过程中会出现噪声,如果对噪声零容忍那么很有可能导致分类无解。
为了解决这个问题又引入了松弛变量。把原始问题修正为:
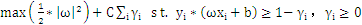
按照拉格朗日法引入拉格朗日因子:

对上式分别求

的导数得到:

,
即
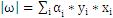
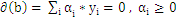
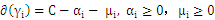
带回
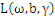
得到拉格朗日的对偶问题:
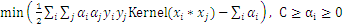
另外当目标函数取极值时,约束条件一定是位于约束边界(KKT条件),也就是说:
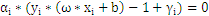
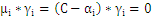
分析上面式子可以得出以下结论:

时:

可以不为零,就是说该点到分割面的距离小于
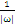
,是误分点。
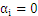
时:
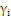
为零,
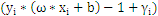
大于零:表示该点到分割面的距离大于
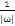
是正确分类点。

时:

为零,

,该点就是支持向量。
再用数学语言提炼一下:
令
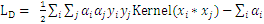
,其对
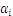
的偏导数为:
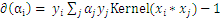
。
KKT条件可以表示为:
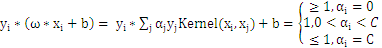
用

表示该KKT条件就是:
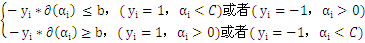
若

,则
所有的

大于所有的
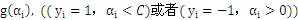
。这里b作为中间数被忽略了,因为b是可以由
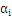
推导得到的。
二、算法部分
对于样本数量比较多的时候(几千个),SVM所需要的内存是计算机所不能承受的。目前,对于这个问题的解决方法主要有两种:块算法和分解算法。这里,libSVM采用的是分解算法中的SMO(串行最小化)方法,其每次训练都只选择两个样本。基本流程如下: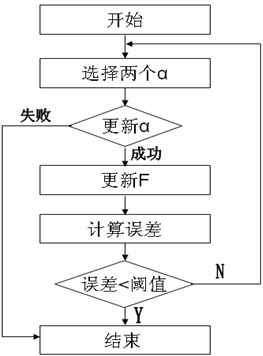
这里有两个重要的算法,一个是
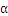
的选择,另一个是
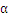
的更新。
2.1
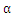
的选择算法
选择两个和KKT条件违背的最严重的两个

,包含两层循环:
外层循环:优先选择遍历非边界样本,因为非边界样本更有可能需要调整,而边界样本常常不能得到进一步调整而留在边界上。在遍历过程中找出
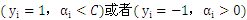
的所有样本中

值最大的那个(这个样本是最有可能不满足
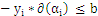
条件的样本。
内层循环:对于外层循环中选定的那个样本

,找到这样的样本
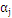
,使得:


最大,上式是更新
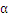
中的一个算式,表示的是在选定
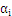
,
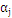
最为更新算子的情况下,
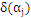
最大。
如果选择
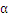
的过程中发现KKT条件已经满足了,那么算法结束。
2.2
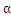
的更新算法
由于SMO每次都只选择2个样本,那么等式约束可以转化为直线约束:
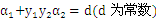
转化为图形表示为:
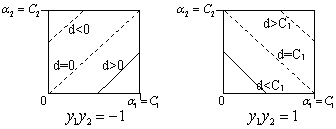
那么
的取值范围是:

把

带入
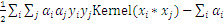
中,得到一个一元二次方程,求极值得到:
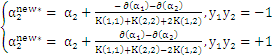
最终:
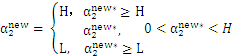
2.3其他
上面说到SVM用到的内存巨大,另一个缺陷就是计算速度,因为数据大了,计算量也就大,很显然计算速度就会下降。因此,一个好的方式就是在计算过程中逐步去掉不参与计算的数据。因为,实践证明,在训练过程中,
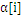
一旦达到边界(
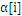
=0或者
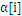
=C),

的值就不会变,随着训练的进行,参与运算的样本会越来越少,SVM最终结果的支持向量(0<
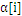
LibSVM采用的策略是在计算过程中,检测active_size中的
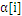
值,如果

到了边界,那么就应该把相应的样本去掉(变成inactived),并放到栈的尾部,从而逐步缩小active_size的大小。
b的计算 ,基本计算公式为:
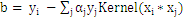
理论上,b的值是不定的。当程序达到最优后,只要用任意一个标准支持向量机(0<

<C)的样本带入上式,得到的b值都是可以的。目前,求b的方法也有很多种。在libSVM中,分别对y=+1和y=-1的两类所有支持向量求b,然后取平均值。

相关文章推荐
- svm中的数学和算法
- svm中的数学和算法详解
- svm中的数学和算法
- svm中的数学和算法
- svm中的数学和算法
- SVM中的数学和算法
- 机器学习中的算法(2)-支持向量机(SVM)基础
- [置顶] 【ML--14】在R语言中使用SVM算法做多分类预测
- STL数学算法及堆排序算法
- 趣味数学-鸡兔同笼算法
- 机器学习第三个算法SVM上(支持向量机)
- 游戏开发中的数学和物理算法(2):定义线
- 【算法】算法中的趣味数学(一)
- 游戏开发中的数学和物理算法(18):缩放
- 机器学习中的算法-支持向量机(SVM)基础
- 游戏开发中的数学和物理算法(6):圆和球的碰撞检测
- 从数学角度看最大期望(EM)算法 II
- SVM算法Python实现语句细节
- 最重要的一些算法 (数学与计算机领域)
- 七月算法(julyedu.com)5 月深度学习班学习笔记-第一节数学基础