多浏览器兼容的Javascript读取XML节点方法
2014-11-14 15:54
816 查看
最近才接触XML这个东西,网上有各种大神都写过js读取XML的方法,但是发现多数都是转载的,而且会发现IE中运行OK,但是到别的浏览器中跑瞬间bug掉了。或许这个问题早就有其他大神解决过。我就在这里谈一下我的经验,分享一下的拙略之作好了~
另外如果你根本不知道树形结构或者XML文件的结构的话,推荐去学习一下XML的节点与元素关系
刚才说到浏览器兼容的问题,其实这个不怪浏览器,浏览器大战也没有影响到这里。问题出在读取方式上。先来看一段常用的XML读取的代码
这段代码就是最通用的载入XML文件的方法。其中不难看出,方法会先判断浏览器是否支持ActiveXObject方法,这个玩意是微软的其他厂家的浏览器并不支持。当ActiveX方法走不通的时候,就会判断浏览器是否支持XMLHttpRequest方法。而在读取XML节点上这两个方法的结构是截然不同的。
先来看一下读取后的结构
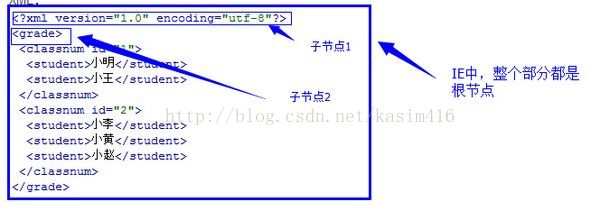

这两张图我相信可以很明白的表达出了,ActiveX和XMLHttpRequest两个方法的不同
光这里就很让人头疼了。到了子节点、孙子节点,那就更乱了。

我们就拿id=1下的子节点来说吧
在XMLHttpRequest方法下,“小明”处于的并不是第一个子节点,而是第二个,也就是ChildNodes[1]。
而在ActiveX中则是第一个,也就是ChildNodes[0]或者firstChild。
在XMLHttpRequest中认为所有的偶数自己点是text Object格式,而奇数个节点才是Node Object。所以我们需要的数据在所有的奇数个节点里,偶数个节点里是啥以及要它何用,呵呵,不要问我,我也不知道。相对于XMLHttpRequest,ActiveX中则是比较中规中矩的。
如果你喜欢随时自己写读取语句,且代码不会反复读取XML文件的内容,那么以下代码对你意义不大。
那么重点来了。
// JavaScript Document
function XML_Reader(filePath){
var LOADER_TYPE = null;//browser_type: IE=0,Chrome、FF=1
var XmlDom = loadXmlFile(filePath);
var Executable=(XmlDom==null)?false:true;
var root = (LOADER_TYPE == 1)?XmlDom.fristChild:XmlDom.childNodes[1];
var pointer = root;//vernier
this.POF = false;
function loadXmlFile(xmlFile){ var xmlDom = null; if (window.ActiveXObject){ xmlDom = new ActiveXObject("Microsoft.XMLDOM"); //xmlDom.loadXML(xmlFile);//XML String xmlDom.load(xmlFile);//XML file LOADER_TYPE = 0; browserDetection(); }else if (document.implementation && document.implementation.createDocument){ var xmlhttp = new window.XMLHttpRequest(); xmlhttp.open("GET", xmlFile, false); xmlhttp.send(null); xmlDom = xmlhttp.responseXML; LOADER_TYPE = 1; }else{ xmlDom = null; } return xmlDom; }
//The method which find node by id dosen't completely support in ActiveXObject(IE);
this.toNodeByID = function(id){
if(!Executable)return;
switch(LOADER_TYPE){
case 0:pointer = getNodeByID_IE(id);break;
case 1:pointer = XmlDom.getElementById(id);break;
}
if(pointer !=null)this.POF = false;
}
//Get a json object, it can get the value which dosen't have child node, the node has child node will be skip
this.getNodeValueByTagName = function(name){
if(!Executable)return;
var backdata = {};var num = 0;
var Nodes = XmlDom.getElementsByTagName(name);
if((num = Nodes.length)<=0)return null;
else{
for(i = 0; i < num; i++){
if(haveChildNode(Nodes[num]))continue;
backdata[num]=getNodeValue(Nodes[num]);
}
}
}
this.toChildNode = function(){
if(!Executable || !hasChildNode(pointer))return;
switch(LOADER_TYPE){
case 0:pointer = pointer.firstChild;break;
case 1:pointer = pointer.childNodes[1];break;
}
}
this.toParentNode = function(){
if(!Executable)return;
if(pointer.parentNode != null)
pointer = pointer.parentNode;
if(pointer != null)this.POF=false;
}
this.toNextNode = function(){
if(!Executable)return;
switch(LOADER_TYPE){
case 0:pointer = pointer.nextSibling;break;
case 1:pointer = pointer.nextSibling.nextSibling;break;
}
if(pointer == null)this.POF=true;
}
this.toLastNode = function(){
if(!Executable)return;
switch(LOADER_TYPE){
case 0:pointer = pointer.previousSibling;break;
case 1:pointer = pointer.previousSibling.previousSibling;break;
}
}
this.getValue = function(){
if(!Executable || hasChildNode(pointer))return null;
return pointer.firstChild.nodeValue;
}
this.getName = function(){
if(!Executable)return;
else return pointer.nodeName;
}
this.getAttr = function(attr){
if(!Executable)return;
return pointer.getAttribute(attr);
}
this.toRoot = function(){
if(!Executable)return;
pointer = root;
}
/*
function hasChildNode(){
if(!Executable || pointer==null)return;
if(!pointer.hasChildNodes())return false;
else{
switch(LOADER_TYPE){
case 0:return pointer.firstChild.hasChildNodes();
case 1:return pointer.childNodes[1].hasChildNodes();
}
}
}*/
function hasChildNode(node){
if(!Executable || pointer==null)return;
if(!node.hasChildNodes())return false;
else{
switch(LOADER_TYPE){
case 0:return node.firstChild.hasChildNodes();break;
case 1:
if(node.childNodes[1])return node.childNodes[1].hasChildNodes();
else return node.firstChild.hasChildNodes(
93a5
);break;
}
}
}
function getNodeValue(node){
return node.firstChild.nodeValue;
}
function getNodeByID_IE(id){
//alert(root.firstChild);return;
p = root.firstChild;
while(p!=null){
if(p.getAttribute('id')==id)break;
if(haveChildNode(p)){p=p.firstChild;continue;}
if(p.nextSibling == null && p.parentNode!=pointer)p = p.parentNode;
p=p.nextSibling;
}
return p;
}
//This method must be run behind the load of ActiveXObject, and before all method which will use the XmlDom.
function browserDetection(){
if(!(navigator.userAgent.indexOf("Chrome") > -1)){
if(!confirm('您当前的浏览器为低版本IE,这会影响您的使用感受,甚至导致部分功能无法正常运行,是否继续浏览该页?')){
window.opener=null;window.open('','_self');window.close();
}
}
}
this.getpointer = function(){
return pointer;
}
}其实并没有任何难度,只是将多种浏览器中的实现方法的分开封装了以下,js会根据浏览器类型自行执行对应代码。便利方式也变为了游标方式。(如果你不懂啥叫游标那就真的没辙了)
主要是为了方便新手和伸手党使用啦~(其实我也是伸手党)
这个方法并没有实现增删改的功能,以后会陆续实现的!如果有什么问题可以联系我。
另外如果你根本不知道树形结构或者XML文件的结构的话,推荐去学习一下XML的节点与元素关系
刚才说到浏览器兼容的问题,其实这个不怪浏览器,浏览器大战也没有影响到这里。问题出在读取方式上。先来看一段常用的XML读取的代码
function loadXmlFile(xmlFile){
var xmlDom = null;
if (window.ActiveXObject){
xmlDom = new ActiveXObject("Microsoft.XMLDOM");
//xmlDom.loadXML(xmlFile);//XML String
xmlDom.load(xmlFile);//XML file
LOADER_TYPE = 0;
browserDetection();
}else if (document.implementation && document.implementation.createDocument){
var xmlhttp = new window.XMLHttpRequest();
xmlhttp.open("GET", xmlFile, false);
xmlhttp.send(null);
xmlDom = xmlhttp.responseXML;
LOADER_TYPE = 1;
}else{
xmlDom = null;
}
return xmlDom;
}这段代码就是最通用的载入XML文件的方法。其中不难看出,方法会先判断浏览器是否支持ActiveXObject方法,这个玩意是微软的其他厂家的浏览器并不支持。当ActiveX方法走不通的时候,就会判断浏览器是否支持XMLHttpRequest方法。而在读取XML节点上这两个方法的结构是截然不同的。
先来看一下读取后的结构
这两张图我相信可以很明白的表达出了,ActiveX和XMLHttpRequest两个方法的不同
光这里就很让人头疼了。到了子节点、孙子节点,那就更乱了。
我们就拿id=1下的子节点来说吧
在XMLHttpRequest方法下,“小明”处于的并不是第一个子节点,而是第二个,也就是ChildNodes[1]。
而在ActiveX中则是第一个,也就是ChildNodes[0]或者firstChild。
在XMLHttpRequest中认为所有的偶数自己点是text Object格式,而奇数个节点才是Node Object。所以我们需要的数据在所有的奇数个节点里,偶数个节点里是啥以及要它何用,呵呵,不要问我,我也不知道。相对于XMLHttpRequest,ActiveX中则是比较中规中矩的。
如果你喜欢随时自己写读取语句,且代码不会反复读取XML文件的内容,那么以下代码对你意义不大。
那么重点来了。
// JavaScript Document
function XML_Reader(filePath){
var LOADER_TYPE = null;//browser_type: IE=0,Chrome、FF=1
var XmlDom = loadXmlFile(filePath);
var Executable=(XmlDom==null)?false:true;
var root = (LOADER_TYPE == 1)?XmlDom.fristChild:XmlDom.childNodes[1];
var pointer = root;//vernier
this.POF = false;
function loadXmlFile(xmlFile){ var xmlDom = null; if (window.ActiveXObject){ xmlDom = new ActiveXObject("Microsoft.XMLDOM"); //xmlDom.loadXML(xmlFile);//XML String xmlDom.load(xmlFile);//XML file LOADER_TYPE = 0; browserDetection(); }else if (document.implementation && document.implementation.createDocument){ var xmlhttp = new window.XMLHttpRequest(); xmlhttp.open("GET", xmlFile, false); xmlhttp.send(null); xmlDom = xmlhttp.responseXML; LOADER_TYPE = 1; }else{ xmlDom = null; } return xmlDom; }
//The method which find node by id dosen't completely support in ActiveXObject(IE);
this.toNodeByID = function(id){
if(!Executable)return;
switch(LOADER_TYPE){
case 0:pointer = getNodeByID_IE(id);break;
case 1:pointer = XmlDom.getElementById(id);break;
}
if(pointer !=null)this.POF = false;
}
//Get a json object, it can get the value which dosen't have child node, the node has child node will be skip
this.getNodeValueByTagName = function(name){
if(!Executable)return;
var backdata = {};var num = 0;
var Nodes = XmlDom.getElementsByTagName(name);
if((num = Nodes.length)<=0)return null;
else{
for(i = 0; i < num; i++){
if(haveChildNode(Nodes[num]))continue;
backdata[num]=getNodeValue(Nodes[num]);
}
}
}
this.toChildNode = function(){
if(!Executable || !hasChildNode(pointer))return;
switch(LOADER_TYPE){
case 0:pointer = pointer.firstChild;break;
case 1:pointer = pointer.childNodes[1];break;
}
}
this.toParentNode = function(){
if(!Executable)return;
if(pointer.parentNode != null)
pointer = pointer.parentNode;
if(pointer != null)this.POF=false;
}
this.toNextNode = function(){
if(!Executable)return;
switch(LOADER_TYPE){
case 0:pointer = pointer.nextSibling;break;
case 1:pointer = pointer.nextSibling.nextSibling;break;
}
if(pointer == null)this.POF=true;
}
this.toLastNode = function(){
if(!Executable)return;
switch(LOADER_TYPE){
case 0:pointer = pointer.previousSibling;break;
case 1:pointer = pointer.previousSibling.previousSibling;break;
}
}
this.getValue = function(){
if(!Executable || hasChildNode(pointer))return null;
return pointer.firstChild.nodeValue;
}
this.getName = function(){
if(!Executable)return;
else return pointer.nodeName;
}
this.getAttr = function(attr){
if(!Executable)return;
return pointer.getAttribute(attr);
}
this.toRoot = function(){
if(!Executable)return;
pointer = root;
}
/*
function hasChildNode(){
if(!Executable || pointer==null)return;
if(!pointer.hasChildNodes())return false;
else{
switch(LOADER_TYPE){
case 0:return pointer.firstChild.hasChildNodes();
case 1:return pointer.childNodes[1].hasChildNodes();
}
}
}*/
function hasChildNode(node){
if(!Executable || pointer==null)return;
if(!node.hasChildNodes())return false;
else{
switch(LOADER_TYPE){
case 0:return node.firstChild.hasChildNodes();break;
case 1:
if(node.childNodes[1])return node.childNodes[1].hasChildNodes();
else return node.firstChild.hasChildNodes(
93a5
);break;
}
}
}
function getNodeValue(node){
return node.firstChild.nodeValue;
}
function getNodeByID_IE(id){
//alert(root.firstChild);return;
p = root.firstChild;
while(p!=null){
if(p.getAttribute('id')==id)break;
if(haveChildNode(p)){p=p.firstChild;continue;}
if(p.nextSibling == null && p.parentNode!=pointer)p = p.parentNode;
p=p.nextSibling;
}
return p;
}
//This method must be run behind the load of ActiveXObject, and before all method which will use the XmlDom.
function browserDetection(){
if(!(navigator.userAgent.indexOf("Chrome") > -1)){
if(!confirm('您当前的浏览器为低版本IE,这会影响您的使用感受,甚至导致部分功能无法正常运行,是否继续浏览该页?')){
window.opener=null;window.open('','_self');window.close();
}
}
}
this.getpointer = function(){
return pointer;
}
}其实并没有任何难度,只是将多种浏览器中的实现方法的分开封装了以下,js会根据浏览器类型自行执行对应代码。便利方式也变为了游标方式。(如果你不懂啥叫游标那就真的没辙了)
主要是为了方便新手和伸手党使用啦~(其实我也是伸手党)
这个方法并没有实现增删改的功能,以后会陆续实现的!如果有什么问题可以联系我。

相关文章推荐
- javascript读取xml的解法,兼容多浏览器
- javascript读取XML(兼容所有浏览器)
- Javascript支持在Firefox下读取XML节点的方法
- Javascript支持在Firefox下读取XML节点的方法
- javascript 解析后的xml对象的读取方法细解
- 读取指定XML节点的方法(XMLtextreader)
- 12种Javascript解决常见浏览器兼容问题的方法
- 这是一个关于XML文档的操作管理器XMLHelper类,类中包括XML文档的创建,文档节点和属性的读取,添加,修改,删除的方法功能的实现
- C#读取xml节点五种方法
- 12种Javascript解决常见浏览器兼容问题的方法
- JavaScript js 兼容浏览器问题 兼容FireFox(FF)、IE的解决方法
- 一种简单环境下,读取XML节点值的方法
- 12种Javascript解决常见浏览器兼容问题的方法
- avascript读取XML(兼容所有浏览器)
- C#.NET示例读写xml所有节点的代码实现方法和读取xml节点的数据总结
- Firefox浏览器兼容Javascript脚本的方法
- C#.NET示例读写xml所有节点的代码实现方法和读取xml节点的数据总结
- 12种Javascript解决常见浏览器兼容问题的方法
- [原]JavaScript 读取XML 通用类 兼容IE与众浏览器
- JavaScript中获取XML数据流中数据节点的方法