K-d tree 算法
2014-11-14 13:17
218 查看
转载的原文链接:http://www.cnblogs.com/eyeszjwang/articles/2429382.html
已经写得非常好了,非常清晰。只是在原文的基础上增加了一点解释,方便大家理解。
K-d tree 算法
k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构。主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。
应用背景
k-d树是用在特征值匹配的情况下,一般是通过距离函数在高维矢量之间进行相似性搜索的问题。可以实现快速准确的查询点的近邻。
实例
先以一个简单直观的实例来介绍k-d树算法。假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间内(如图1中黑点所示)。k-d树算法就是要确定图
1中这些分割空间的分割线(多维空间即为分割平面,一般为超平面)。下面就要通过一步步展示k-d树是如何确定这些分割线的。

图1二维数据k-d树空间划分示意图
k-d树算法可以分为两大部分,一部分是有关k-d树本身这种数据结构建立的算法,另一部分是在建立的k-d树上如何进行最邻近查找的算法。
k-d树构建算法
k-d树是一个二叉树,每个节点表示一个空间范围。表1给出的是k-d树每个节点中主要包含的数据结构。
表1 k-d树中每个节点的数据类型
看这个描述可能会有点迷惑,现在来简单的描述一下:
1. Node-date是一个k维的节点,在我们举得例子中就是一个二维的节点。其实可以把Note-data看做是某个特定区域(Range)的“根节点” (注:你必须递归的看待这个问题)。
2. Range的范围在初始的时候可以看成是这六个点。
3. split你直观的感受就是图1中的那些实线。
4. split可以把多维空间分为左右两个部分,小于分割线的我们规定为在左空间,大于分割线的我们认为在右空间
从上面对k-d树节点的数据类型的描述可以看出构建k-d树是一个逐级展开的递归过程。表2给出的是构建k-d树的伪码。
从上面对k-d树节点的数据类型的描述可以看出构建k-d树是一个逐级展开的递归过程。表2给出的是构建k-d树的伪码。
表2 构建k-d树的伪码
以上述举的实例来看,过程如下:
以上述举的实例来看,过程如下:
由于此例简单,数据维度只有2维,所以可以简单地给x,y两个方向轴编号为0,1,也即split={0,1}。
(1)确定split域的首先该取的值。分别计算x,y方向上数据的方差得知x方向上的方差最大,所以split域值首先取0,也就是x轴方向;
我们验算一下,有助有些同学对数学有恐惧心理的同学理解:

上面列出的是方差的计算公式。
有6个点分别是(2, 3),(5,
4),(9, 6),(4,
7),(8, 1),(7,
2)
在X方向的我们就选取:2,5,9,4,8,7
计算出平均数:
平均值:M(x)=5.833
方差:S(x)=5.81
在Y方向我们选取的数据是:3,4,6,7,1,2
平均值:M(Y)=3.83
方差:S(Y)=3.137
X方向上的方差比较大,说明这个方向上的点分的比较开,选这个方向分割。(其实可以很容易想到原因)
(2)确定Node-data的域值。根据x轴方向的值2,5,9,4,8,7排序选出中值为7,所以Node-data=(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于split
=0(x轴)的直线x = 7;
(3)确定左子空间和右子空间。分割超平面x= 7将整个空间分为两部分,如图2所示。x
<= 7的部分为左子空间,包含3个节点{(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点{(9,6),(8,1)}。

图 2 x=7将整个空间分为两部分
如算法所述,k-d树的构建是一个递归的过程。然后对左子空间和右子空间内的数据重复根节点的过程就可以得到下一级子节点(5,4)和(9,6)(也就是左右子空间的'根'节点),同时将空间和数据集进一步细分。如此反复直到空间中只包含一个数据点,如图1所示。最后生成的k-d树如图5所示。
为了方方便又数学恐惧症的在处理一遍剩余的左右空间,也便于理解递归的算法。
l 先计算左空间
剩余的点集是(2,3), (4,7),(5,4)
X方向上的平均值和方差:
平均值:M(x)=3.67
方差: s(x)= 1.56
Y方向上的平均值和方差:
M(Y)=4.67
S(Y)=2.89
所以左子空间的split应该选在Y方向上。Y方向上的中值就是4,所以我们选取的点就是(5,4)
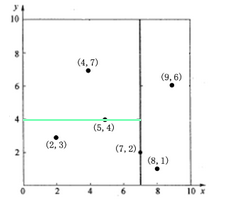
图 3
依次类推,我们可以计算出右自空间的距离,这个时候我们得到的图形就如图4所示。

图 4
注意:每一级节点旁边的'x'和'y'表示以该节点分割左右子空间时split所取的值。

图 5
k-d树上的最邻近查找算法
在k-d树中进行数据的查找也是特征匹配的重要环节,其目的是检索在k-d树中与查询点距离最近的数据点。这里先以一个简单的实例来描述最邻近查找的基本思路。
星号表示要查询的点(2.1,3.1)。通过二叉搜索,顺着搜索路径很快就能找到最邻近的近似点,也就是叶子节点(2,3)。而找到的叶子节点并不一定就是最邻近的,最邻近肯定距离查询点更近,应该位于以查询点为圆心且通过叶子节点的圆域内。为了找到真正的最近邻,还需要进行'回溯'操作:算法沿搜索路径反向查找是否有距离查询点更近的数据点。此例中先从(7,2)点开始进行二叉查找,然后到达(5,4),最后到达(2,3),此时搜索路径中的节点为<(7,2),(5,4),(2,3)>,首先以(2,3)作为当前最近邻点,计算其到查询点(2.1,3.1)的距离为0.1414,然后回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查询点更近的数据点(就是计算一下两点之间的距离,(5,4)和判定点)。以(2.1,3.1)为圆心,以0.1414为半径画圆,如图
6所示。发现该圆并不和超平面y = 4交割,因此不用进入(5,4)节点右子空间中去搜索。

图6查找(2.1,3.1)点的两次回溯判断
再回溯到(7,2),以(2.1,3.1)为圆心,以0.1414为半径的圆更不会与x
= 7超平面交割,因此不用进入(7,2)右子空间进行查找。至此,搜索路径中的节点已经全部回溯完,结束整个搜索,返回最近邻点(2,3),最近距离为0.1414。
一个复杂点了例子如查找点为(2,4.5)。同样先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y
= 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,取(4,7)为当前最近邻点,计算其与目标查找点的距离为3.202。然后回溯到(5,4),计算其与查找点之间的距离为3.041。以(2,4.5)为圆心,以3.041为半径作圆,如图
7所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找。此时需将(2,3)节点加入搜索路径中得<(7,2),(2,3)>。回溯至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5。回溯至(7,2),以(2,4.5)为圆心1.5为半径作圆,并不和x
= 7分割超平面交割,如图 8所示。至此,搜索路径回溯完。返回最近邻点(2,3),最近距离1.5。k-d树查询算法的伪代码如表3所示。

图7查找(2,4.5)点的第一次回溯判断

图8查找(2,4.5)点的第二次回溯判断
安利一个微信公众号~欢迎多多关注哟~定期推送IT面试经典问题~
谢谢大家

已经写得非常好了,非常清晰。只是在原文的基础上增加了一点解释,方便大家理解。
K-d tree 算法
k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构。主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。
应用背景
k-d树是用在特征值匹配的情况下,一般是通过距离函数在高维矢量之间进行相似性搜索的问题。可以实现快速准确的查询点的近邻。
实例
先以一个简单直观的实例来介绍k-d树算法。假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间内(如图1中黑点所示)。k-d树算法就是要确定图
1中这些分割空间的分割线(多维空间即为分割平面,一般为超平面)。下面就要通过一步步展示k-d树是如何确定这些分割线的。
图1二维数据k-d树空间划分示意图
k-d树算法可以分为两大部分,一部分是有关k-d树本身这种数据结构建立的算法,另一部分是在建立的k-d树上如何进行最邻近查找的算法。
k-d树构建算法
k-d树是一个二叉树,每个节点表示一个空间范围。表1给出的是k-d树每个节点中主要包含的数据结构。
表1 k-d树中每个节点的数据类型
| 域名 | 数据类型 | 描述 |
| Node-data | 数据矢量 | 数据集中某个数据点,是n维矢量(这里也就是k维) |
| Range | 空间矢量 | 该节点所代表的空间范围 |
| split | 整数 | 垂直于分割超平面的方向轴序号 |
| Left | k-d树 | 由位于该节点分割超平面左子空间内所有数据点所构成的k-d树 |
| Right | k-d树 | 由位于该节点分割超平面右子空间内所有数据点所构成的k-d树 |
| parent | k-d树 | 父节点 |
1. Node-date是一个k维的节点,在我们举得例子中就是一个二维的节点。其实可以把Note-data看做是某个特定区域(Range)的“根节点” (注:你必须递归的看待这个问题)。
2. Range的范围在初始的时候可以看成是这六个点。
3. split你直观的感受就是图1中的那些实线。
4. split可以把多维空间分为左右两个部分,小于分割线的我们规定为在左空间,大于分割线的我们认为在右空间
从上面对k-d树节点的数据类型的描述可以看出构建k-d树是一个逐级展开的递归过程。表2给出的是构建k-d树的伪码。
从上面对k-d树节点的数据类型的描述可以看出构建k-d树是一个逐级展开的递归过程。表2给出的是构建k-d树的伪码。
表2 构建k-d树的伪码
| 算法:构建k-d树(createKDTree) |
| 输入:数据点集Data-set和其所在的空间Range |
| 输出:Kd,类型为k-d tree |
| 1.If Data-set为空,则返回空的k-d tree |
| 2.调用节点生成程序: (1)确定split域:对于所有描述子数据(特征矢量),统计它们在每个维上的数据方差。以上面的那个例子为例,它有两个维,X方向上的和Y方向上的。我们可以计算出两个方向的方差,然后挑选出最大的,对应的维就是split域。数据方差大表明沿该坐标轴方向上的数据分散得比较开,在这个方向上进行数据分割有较好的分辨率; (2)确定Node-data域:数据点集Data-set按其第split域的值排序。位于正中间的那个数据点被选为Node-data。此时新的Data-set' = Data-set\Node-data(除去其中Node-data这一点)。 |
| 3.dataleft = {d属于Data-set' && d[split] ≤ Node-data[split]} *注:dataleft表示的是左空间的数据集(是一些K维的点),它的数据集取值范围是根据split那个维度来划分的,所有在split域上的某一维小于等于Node-data中选取的那一个维的数据都划分为我们左空间 Left_Range = {Range && dataleft} *注:表示的左空间的范围包括做数据集以及其边界在图1我们大致可以理解为在0《X《7这个范围内 dataright = {d属于Data-set' && d[split] > Node-data[split]} Right_Range = {Range && dataright} 注:同上 |
| 4.left = 由(dataleft,Left_Range)建立的k-d tree,即递归调用createKDTree(dataleft,Left_ Range)。并设置left的parent域为Kd; right = 由(dataright,Right_Range)建立的k-d tree,即调用createKDTree(dataleft,Left_ Range)。并设置right的parent域为Kd。 |
以上述举的实例来看,过程如下:
由于此例简单,数据维度只有2维,所以可以简单地给x,y两个方向轴编号为0,1,也即split={0,1}。
(1)确定split域的首先该取的值。分别计算x,y方向上数据的方差得知x方向上的方差最大,所以split域值首先取0,也就是x轴方向;
我们验算一下,有助有些同学对数学有恐惧心理的同学理解:
上面列出的是方差的计算公式。
有6个点分别是(2, 3),(5,
4),(9, 6),(4,
7),(8, 1),(7,
2)
在X方向的我们就选取:2,5,9,4,8,7
计算出平均数:
平均值:M(x)=5.833
方差:S(x)=5.81
在Y方向我们选取的数据是:3,4,6,7,1,2
平均值:M(Y)=3.83
方差:S(Y)=3.137
X方向上的方差比较大,说明这个方向上的点分的比较开,选这个方向分割。(其实可以很容易想到原因)
(2)确定Node-data的域值。根据x轴方向的值2,5,9,4,8,7排序选出中值为7,所以Node-data=(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于split
=0(x轴)的直线x = 7;
(3)确定左子空间和右子空间。分割超平面x= 7将整个空间分为两部分,如图2所示。x
<= 7的部分为左子空间,包含3个节点{(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点{(9,6),(8,1)}。
图 2 x=7将整个空间分为两部分
如算法所述,k-d树的构建是一个递归的过程。然后对左子空间和右子空间内的数据重复根节点的过程就可以得到下一级子节点(5,4)和(9,6)(也就是左右子空间的'根'节点),同时将空间和数据集进一步细分。如此反复直到空间中只包含一个数据点,如图1所示。最后生成的k-d树如图5所示。
为了方方便又数学恐惧症的在处理一遍剩余的左右空间,也便于理解递归的算法。
l 先计算左空间
剩余的点集是(2,3), (4,7),(5,4)
X方向上的平均值和方差:
平均值:M(x)=3.67
方差: s(x)= 1.56
Y方向上的平均值和方差:
M(Y)=4.67
S(Y)=2.89
所以左子空间的split应该选在Y方向上。Y方向上的中值就是4,所以我们选取的点就是(5,4)
图 3
依次类推,我们可以计算出右自空间的距离,这个时候我们得到的图形就如图4所示。
图 4
注意:每一级节点旁边的'x'和'y'表示以该节点分割左右子空间时split所取的值。
图 5
k-d树上的最邻近查找算法
在k-d树中进行数据的查找也是特征匹配的重要环节,其目的是检索在k-d树中与查询点距离最近的数据点。这里先以一个简单的实例来描述最邻近查找的基本思路。
星号表示要查询的点(2.1,3.1)。通过二叉搜索,顺着搜索路径很快就能找到最邻近的近似点,也就是叶子节点(2,3)。而找到的叶子节点并不一定就是最邻近的,最邻近肯定距离查询点更近,应该位于以查询点为圆心且通过叶子节点的圆域内。为了找到真正的最近邻,还需要进行'回溯'操作:算法沿搜索路径反向查找是否有距离查询点更近的数据点。此例中先从(7,2)点开始进行二叉查找,然后到达(5,4),最后到达(2,3),此时搜索路径中的节点为<(7,2),(5,4),(2,3)>,首先以(2,3)作为当前最近邻点,计算其到查询点(2.1,3.1)的距离为0.1414,然后回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查询点更近的数据点(就是计算一下两点之间的距离,(5,4)和判定点)。以(2.1,3.1)为圆心,以0.1414为半径画圆,如图
6所示。发现该圆并不和超平面y = 4交割,因此不用进入(5,4)节点右子空间中去搜索。
图6查找(2.1,3.1)点的两次回溯判断
再回溯到(7,2),以(2.1,3.1)为圆心,以0.1414为半径的圆更不会与x
= 7超平面交割,因此不用进入(7,2)右子空间进行查找。至此,搜索路径中的节点已经全部回溯完,结束整个搜索,返回最近邻点(2,3),最近距离为0.1414。
一个复杂点了例子如查找点为(2,4.5)。同样先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y
= 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,取(4,7)为当前最近邻点,计算其与目标查找点的距离为3.202。然后回溯到(5,4),计算其与查找点之间的距离为3.041。以(2,4.5)为圆心,以3.041为半径作圆,如图
7所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找。此时需将(2,3)节点加入搜索路径中得<(7,2),(2,3)>。回溯至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5。回溯至(7,2),以(2,4.5)为圆心1.5为半径作圆,并不和x
= 7分割超平面交割,如图 8所示。至此,搜索路径回溯完。返回最近邻点(2,3),最近距离1.5。k-d树查询算法的伪代码如表3所示。
图7查找(2,4.5)点的第一次回溯判断
图8查找(2,4.5)点的第二次回溯判断
谢谢大家

相关文章推荐
- K-D Tree 算法详解及Python实现
- k-d tree树 近邻算法
- 最近邻算法的实现:k-d tree
- k-d tree算法研究
- k-d tree算法研究
- “算法与计算数学”之四书五经
- 算法之带权调度问题(有个人新创复杂度n算法)
- 一些常用算法 练手的的代码
- 编程珠玑 - 算法优化 - 过滤敏感词 - 第三步:树形结构
- 图的遍历算法程序
- 01-算法分析开始
- 【计算机科学中最重要的32个算法】
- 《程序员的第一年》---------- 数据挖掘(数据挖掘视频与算法 百度分享地址如下)
- 单链表全部算法
- Java编程算法基础-自顶向下风格
- 【算法导论】动态规划之“钢管切割”问题
- 专门用来对付运算式子的一个算法
- HDU - 2121 Ice_cream’s world II(朱刘算法+虚根)
- 【iOS学习笔记】iOS算法(四)之冒泡排序