大数据云计算的利器hadoop介绍
2014-11-11 10:37
417 查看
Hadoop是由ASF(Apache SoftwareFoundation)源于Lucene的子项目Nutch所开发的开源分布式计算平台,可以构建具有高容错性、可伸缩性、低成本、和良好扩展的高效分布式系统,允许用户将Hadoop部署在大量廉价硬件设备所组成的集群上,为应用程序提供一组稳定可靠的接口,充分利用集群的存储和计算能力,完成海量数据的处理。由于Hadoop优势突出,得到了众多企业和个人的青睐,尤其是在互联网领域。Yahoo!通过Hadoop集群支持广告系统和Web搜索研究;Facebook借助Hadoop集群支持数据分析和机器学习;Baidu使用Hadoop进行搜索日志的分析和网页数据的挖掘;TaobaoHadoop系统用于存储并处理电子商务交易的相关数据;中国移动研究院基于Hadoop的“Big Cloud”系统用于对数据进行分析和对外提供服务等。

PS:Hadoop之父Doug Cutting解释Hadoop的得名:“这个名字是我孩子给一个棕黄色的大象玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义,并且不会被用于别处。小孩子恰恰是这方面的高手。” Hadoop的技术背景——与Google云计算的渊源说到Hadoop,不得不从云计算说起,主流互联网公司为了抢占云计算的市场份额,纷纷提出各自的云计算思路以及解决方案。Google、Yahoo、Amazon、Salesforce与Microsoft等公司作为行业领军者,它们的云计算平台解决方案的详情如下表所示:表1-1 主流云计算平台详情
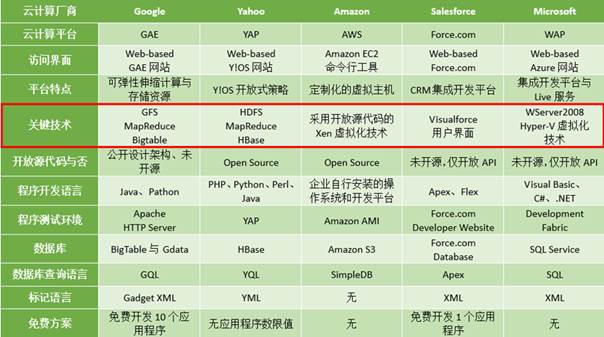
从上表可以看出Google和Yahoo云计算平台的关键技术非常相似,的确,Hadoop是Google云计算的开源实现。
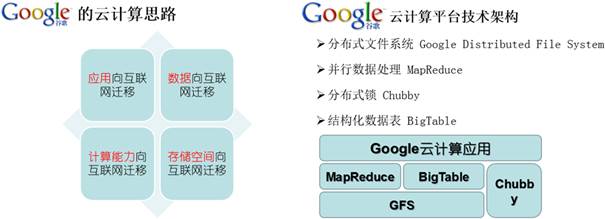
作为一个开源项目,Hadoop受到最先由Google Lab开发的Google分布式文件系统GFS(Google File System)以及Google的Map/Reduce编程模式的启发,将 NDFS(Nutch Distributed File System)和Map/Reduce分别纳入Hadoop项目中,现已发展成包括Hadoop common、HDFS、MapReduce、HBase、Hive、ZooKeeper、Avro、Pig、Ambari、Sqoop等在内的多个子项目。
Hadoop Common:Hadoop体系最底层的一个模块,为Hadoop各子项目提供各种工具,如:配置文件和日志操作等。HDFS:Hadoop分布式文件系统(Hadoop Distributed File System) ,前身是NDFS (Nutch Distributed File System)。类似Google File System。MapReduce:实现了MapReduce编程框架。HBase: 基于HDFS,是一个开源的、基于列存储模型的分布式数据库。类似Google BigTable的分布式NoSQL列数据库。Hive:数据仓库工具,由Facebook贡献。使得存储在hadoop里面的海量数据的汇总,即席查询简单化。Zookeeper:分布式锁设施,一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。类似Google Chubby,由Facebook贡献。Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。Pig:大数据分析平台,为用户提供多种接口。Ambari:Hadoop管理工具,可以快捷的监控、部署、管理集群。Sqoop:用于在Hadoop与传统的数据库间进行数据的传递。
Hadoop具有如下优势:(1)可伸缩性,能够处理PB级数据,并可以无限扩充存储和计算能力。(2)可靠性,可以维护同一份数据的多份副本并自动对失败的节点重新分布处理。(3)高效性,Hadoop能并行地处理数据。同时,Hadoop也是低成本的,因为它对硬件的要求不高,所以可以运行在普通的微机集群上。Hadoop 从单一应用(Web数据抓取)发展到现在庞大的Hadoop生态系统(Hadoop Ecosystem),自成一派的技术架构体系,叩开了大数据时代的海量数据处理的大门,开辟了海量数据存储、处理与应用的新领地。
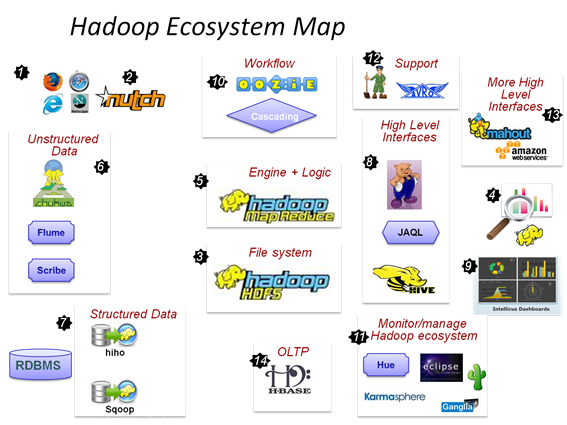
1.这一切,都起源自Web数据爆炸时代的来临2.数据抓取系统—Nutch3.海量数据怎么存,当然是用分布式文件系统- HDFS4.数据怎么用呢?分析,处理5.MapReduce框架,让你编写代码来实现对大数据的分析工作6.非结构化数据(日志)收集处理- fuse,webdav, chukwa, flume,Scribe7.数据导入到HDFS中,至此RDBSM也可以加入HDFS的狂欢了- Hiho, sqoop8.MapReduce太麻烦,好吧,让你用熟悉的方式来操作Hadoop里的数据– Pig, Hive, Jaql9.让你的数据可见- drilldown, Intellicus10.用高级语言管理你的任务流– oozie, Cascading11.Hadoop当然也有自己的监控管理工具– Hue, karmasphere, eclipseplugin, cacti, ganglia12.数据序列化处理与任务调度– Avro, Zookeeper13.更多构建在Hadoop上层的服务–Mahout, Elastic map Reduce14.OLTP存储系统– Hbase
PS:Hadoop之父Doug Cutting解释Hadoop的得名:“这个名字是我孩子给一个棕黄色的大象玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义,并且不会被用于别处。小孩子恰恰是这方面的高手。” Hadoop的技术背景——与Google云计算的渊源说到Hadoop,不得不从云计算说起,主流互联网公司为了抢占云计算的市场份额,纷纷提出各自的云计算思路以及解决方案。Google、Yahoo、Amazon、Salesforce与Microsoft等公司作为行业领军者,它们的云计算平台解决方案的详情如下表所示:表1-1 主流云计算平台详情
从上表可以看出Google和Yahoo云计算平台的关键技术非常相似,的确,Hadoop是Google云计算的开源实现。
作为一个开源项目,Hadoop受到最先由Google Lab开发的Google分布式文件系统GFS(Google File System)以及Google的Map/Reduce编程模式的启发,将 NDFS(Nutch Distributed File System)和Map/Reduce分别纳入Hadoop项目中,现已发展成包括Hadoop common、HDFS、MapReduce、HBase、Hive、ZooKeeper、Avro、Pig、Ambari、Sqoop等在内的多个子项目。
Hadoop Common:Hadoop体系最底层的一个模块,为Hadoop各子项目提供各种工具,如:配置文件和日志操作等。HDFS:Hadoop分布式文件系统(Hadoop Distributed File System) ,前身是NDFS (Nutch Distributed File System)。类似Google File System。MapReduce:实现了MapReduce编程框架。HBase: 基于HDFS,是一个开源的、基于列存储模型的分布式数据库。类似Google BigTable的分布式NoSQL列数据库。Hive:数据仓库工具,由Facebook贡献。使得存储在hadoop里面的海量数据的汇总,即席查询简单化。Zookeeper:分布式锁设施,一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。类似Google Chubby,由Facebook贡献。Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。Pig:大数据分析平台,为用户提供多种接口。Ambari:Hadoop管理工具,可以快捷的监控、部署、管理集群。Sqoop:用于在Hadoop与传统的数据库间进行数据的传递。
Hadoop具有如下优势:(1)可伸缩性,能够处理PB级数据,并可以无限扩充存储和计算能力。(2)可靠性,可以维护同一份数据的多份副本并自动对失败的节点重新分布处理。(3)高效性,Hadoop能并行地处理数据。同时,Hadoop也是低成本的,因为它对硬件的要求不高,所以可以运行在普通的微机集群上。Hadoop 从单一应用(Web数据抓取)发展到现在庞大的Hadoop生态系统(Hadoop Ecosystem),自成一派的技术架构体系,叩开了大数据时代的海量数据处理的大门,开辟了海量数据存储、处理与应用的新领地。
1.这一切,都起源自Web数据爆炸时代的来临2.数据抓取系统—Nutch3.海量数据怎么存,当然是用分布式文件系统- HDFS4.数据怎么用呢?分析,处理5.MapReduce框架,让你编写代码来实现对大数据的分析工作6.非结构化数据(日志)收集处理- fuse,webdav, chukwa, flume,Scribe7.数据导入到HDFS中,至此RDBSM也可以加入HDFS的狂欢了- Hiho, sqoop8.MapReduce太麻烦,好吧,让你用熟悉的方式来操作Hadoop里的数据– Pig, Hive, Jaql9.让你的数据可见- drilldown, Intellicus10.用高级语言管理你的任务流– oozie, Cascading11.Hadoop当然也有自己的监控管理工具– Hue, karmasphere, eclipseplugin, cacti, ganglia12.数据序列化处理与任务调度– Avro, Zookeeper13.更多构建在Hadoop上层的服务–Mahout, Elastic map Reduce14.OLTP存储系统– Hbase

相关文章推荐
- 数据、进程-云计算学习笔记---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战-by小雨
- 什么是HADOOP、产生背景、在大数据、云计算中的位置和关系、国内外HADOOP应用案例介绍、就业方向、生态圈以及各组成部分的简介(学习资料中的文档材料)
- hadoop背景介绍及在大数据、云计算中的位置和关系
- 云计算实战 (海量日志管理)hadoop + scribe -- scribe 介绍和安装
- Android Loaders介绍(异步加载数据利器,类似AsyncTask)
- IT视频课程集(包含各类Oracle、DB2、Linux、Mysql、Nosql、Hadoop、BI、云计算、编程开发、网络、大数据、虚拟化
- 大数据架构:Hadoop和Storm的介绍
- 准备测试数据的利器DBUNIT介绍
- 每天一点hadoop 第四篇(云计算与大数据)
- 王家林最受欢迎的一站式云计算大数据和移动互联网解决方案课程 V1(20140809)之Hadoop企业级完整训练:Rocky的16堂课(HDFS&MapReduce&HBase&Hive&Zookee
- hadoop SequenceFile介绍 大数据 存储
- 大数据架构师基础:hadoop家族,Cloudera系列产品介绍
- 云计算学习笔记---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战
- 大数据伴随“平安城市”走向智能——英特尔发行版 Hadoop 为视频智能云计算方案提供支持
- [Hadoop] 云计算管理三大利器:Nagios、Ganglia和Splunk
- 云计算学习笔记003---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战
- 云计算和虚拟化:数据迁移下的最佳利器
- 大数据中:Hadoop云计算以及Nosql与BI商业智能之间的关系
- Hadoop数据管理介绍及原理分析