Neo4j简介
2014-11-01 14:30
190 查看
来自:残阳似血的博客
http://qinxuye.me/article/introduction-to-neo4j/
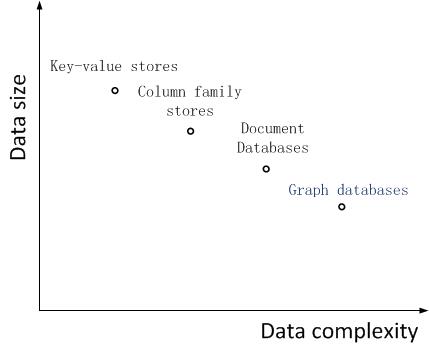
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系、地图数据、或是基因信息等等。RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘。NoSQL数据库的兴起,很好地解决了海量数据的存放问题,图数据库也是NoSQL的一个分支,相比于NoSQL中的其他分支,它很适合用来原生表达图结构的数据。下面一张图说明,相比于其他NoSQL,图数据库存放的数据规模有所下降,但是更能够表达复杂的数据。
通常来说,一个图数据库存储的结构就如同数据结构中的图,由顶点和边组成。
Neo4j是图数据库中一个主要代表,其开源,且用Java实现。经过几年的发展,已经可以用于生产环境。其有两种运行方式,一种是服务的方式,对外提供REST接口;另外一种是嵌入式模式,数据以文件的形式存放在本地,可以直接对本地文件进行操作。
Neo4j分三个版本:社区版(community)、高级版(advanced)和企业版(enterprise)。社区版是基础,本文主要对其作出介绍,它使用的是GPLv3协议,这意味着修改和使用其代码都需要开源,但是这是建立在软件分发的基础上,如果使用Neo4j作为服务提供,而不分发软件,则不需要开源。这实际上是GPL协议本身的缺陷。高级版和企业版建立在社区版的基础上,但多出一些高级特性。高级版包括一些高级监控特性,而企业版则包括在线备份、高可用集群以及高级监控特性。要注意它们使用了AGPLv3协议,也就是说,除非获得商业授权,否则无论以何种方式修改或者使用Neo4j,都需要开源。
接下来就从Neo4j的几个主要特性出发,结合代码逐一作出介绍。它们包括:数据模型、索引、事务、遍历和查询、以及图算法。
数据模型
Neo4j被称为property graph,除了顶点(Node)和边(Relationship,其包含一个类型),还有一种重要的部分——属性。无论是顶点还是边,都可以有任意多的属性。属性的存放类似于一个hashmap,key为一个字符串,而value必须是Java基本类型、或者是基本类型数组,比如说String、int或者int[]都是合法的。接下来本文都会围绕下图进行举例。

可以看到Thomas Anderson这个Node有age和name的property,其指向Trinity的relationship边类型为KNOWS,有age的属性。
要生成上图所示数据,首先可以定义所有边的类型:?
索引
Neo4j支持索引,其内部实际上通过Lucene实现。现在可以创建一个索引叫nodes,来索引所有拥有name属性的顶点,这样我们就可以查询名字为“Thomas Anderson”的节点了。以下代码创建了这个索引,并索引了“Thomas Anderson”顶点,并通过名字得到了它。?事务
Neo4j完整支持事务,即满足ACID性质。示例代码如下:?遍历和查询
遍历是图数据库中的主要查询方式,所以遍历是图数据中相当关键的一个概念。可以用两种方式来进行遍历查询:第一种是直接编写Java代码,使用Neo4j提供的traversal框架;第二种方式是使用Neo4j提供的描述型查询语言,Cypher。第一种方式例子如下:?Thomas Anderson's friends:
At depth 1 => Trinity
At depth 1 => Morpheus
At depth 2 => Cypher
At depth 3 => Agent Smith
Number of friends found: 4
关于traversal框架,请参考官方文档。
第二种方法Cypher则直观得多,它是一种描述型的语言。下面是达到同样目标的Cypher命令。?
查询结果如下:
+-----------------------------------------------------------------------------------+
| f | f.name |
+-----------------------------------------------------------------------------------+
| Node[4]{name:"Morpheus",rank:"Captain",occupation:"Total badass"} | "Morpheus" |
| Node[5]{name:"Cypher",last name:"Reagan"} | "Cypher" |
| Node[6]{name:"Agent Smith",version:"1.0b",language:"C++"} | "Agent Smith" |
| Node[3]{name:"Trinity"} | "Trinity" |
+-----------------------------------------------------------------------------------+
4 rows
289 ms
不过,Cypher语言不能定义查询是按照深度优先还是广度优先遍历。Cypher更多用法,可以参考官方文档。
图算法
Neo4j实现的三种图算法:最短路径、Dijkstra算法以及A*算法。下面是最短路径算法的简单例子:?总结
本文对Neo4j做了简单的介绍,更多信息可以参考Neo4j的官方网站。在社交网络呈爆炸性发展的今天,随着knowledge graph(知识图谱)技术的兴起,相信图数据库能够扮演越来越重要的角色。
本文使用的完整代码,可以在这里下载。

相关文章推荐
- 图形数据库Neo4J简介
- neo4j-简介,安装
- 图形数据库Neo4J简介
- 图形数据库Neo4J简介
- Neo4j 简介
- Neo4j简介及Py2Neo的用法(python操作neo4j)
- Neo4j简介
- Neo4j图数据库简介和底层原理
- 图数据库Neo4j简介
- 图形数据库Neo4J简介
- 图数据库实践系列 (一)--Neo4J简介与安装
- 图形数据库Neo4j(1)----简介及使用
- 图形数据库Neo4J简介
- Neo4j简介
- c++ Boost库简介
- RDF简介
- 《iPhone开发基础教程》第8章 表视图简介
- CString常用方法简介
- onSaveInstanceState(Bundle outState)函数简介
- Hbase安装与简介