flume+kafka+hdfs构建实时消息处理系统
2014-10-22 15:39
645 查看
flume是一个实时消息收集系统,它定义了多种的source、channel、sink,可以根据实际情况选择。
Flume下载及文档: http://flume.apache.org/ Kafka
kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
支持通过kafka服务器和消费机集群来分区消息。
支持Hadoop并行数据加载。
kafka的目的是提供一个发布订阅解决方案,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
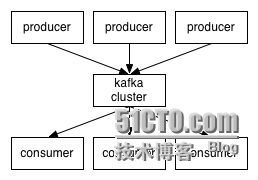
kafka分布式订阅架构如下图:--取自Kafka官网
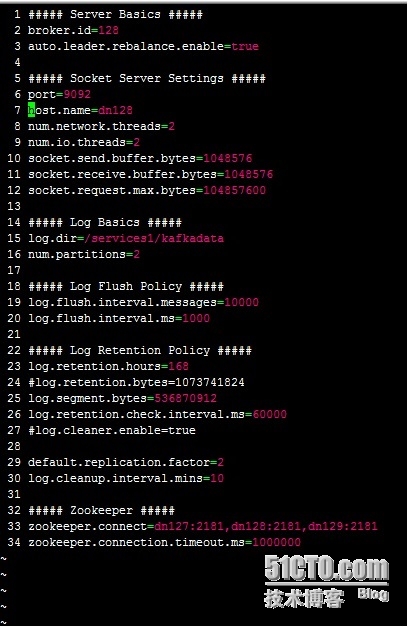
配置kafka的配置文件 server.properties ,其它可根据自己的情况修改。
启动kafka,启动之前先启动zookeeper,zookeeper的配置不再叙述。
# bin/kafka-server-start.sh config/server.properties
Create a topic
# bin/kafka-topics.sh --create --zookeeper localhost:2181 ----replication-factor 1 --partitions 1 --topic test
查看topic
# bin/kafka-topics.sh --list --zookeeper localhost:2181
测试是否能正常生产消费;验证流程正确性
# bin/kafka-console-producer.sh--broker-list localhost:9092 --topic test
# bin/kafka-console-consumer.sh--zookeeper localhost:2181 --topic test --from-beginning
接下来是框架之间的整合
flume和kafka整合
1.下载flume-kafka-plus:https://github.com/beyondj2ee/flumeng-kafka-plugin
2.提取插件中的flume-conf.properties文件
修改该文件:#source section
producer.sources.s.type = exec
producer.sources.s.command = tail -f -n+1 /mnt/hgfs/vmshare/test.log
producer.sources.s.channels = c
修改所有topic的值改为test
将改后的配置文件放进flume/conf目录下
在该项目中提取以下jar包放入环境中flume的lib下:
还有package目录的flumeng-kafka-plugin.jar包一并放到flume的lib目录下。
附上flume的配置文件
############################################
# producer config
###########################################
#agent section
producer.sources = s
producer.channels = c
producer.sinks = r
#source section
producer.sources.s.type = exec
producer.sources.s.channels = c
producer.sources.s.command = tail -f /var/log/messages
#producer.sources.s.type=spooldir
#producer.sources.s.spoolDir=/home/xiaojie.li
#producer.sources.s.fileHeader=false
#producer.sources.s.type=syslogtcp
#producer.sources.s.port=5140
#producer.sources.s.host=localhost
# Each sink's type must be defined
producer.sinks.r.type = org.apache.flume.plugins.KafkaSink
producer.sinks.r.metadata.broker.list=10.10.10.127:9092
producer.sinks.r.zk.connect=10.10.10.127:2181
producer.sinks.r.partition.key=0
producer.sinks.r.partitioner.class=org.apache.flume.plugins.SinglePartition
producer.sinks.r.serializer.class=kafka.serializer.StringEncoder
producer.sinks.r.request.required.acks=0
producer.sinks.r.max.message.size=1000000
producer.sinks.r.producer.type=sync
producer.sinks.r.custom.encoding=UTF-8
producer.sinks.r.custom.topic.name=test
#Specify the channel the sink should use
producer.sinks.r.channel = c
# Each channel's type is defined.
producer.channels.c.type = memory
producer.channels.c.capacity = 1000
producer.channels.c.transactionCapacity=100
#producer.channels.c.type=file
#producer.channels.c.checkpointDir=/home/checkdir
#producer.channels.c.dataDirs=/home/datadir
验证flume和kafka组合
前面kafka已经启动,这里直接启动flume
# bin/flume-ng agent -c conf -f conf/master.properties -n producer -Dflume.root.logger=INFO,console
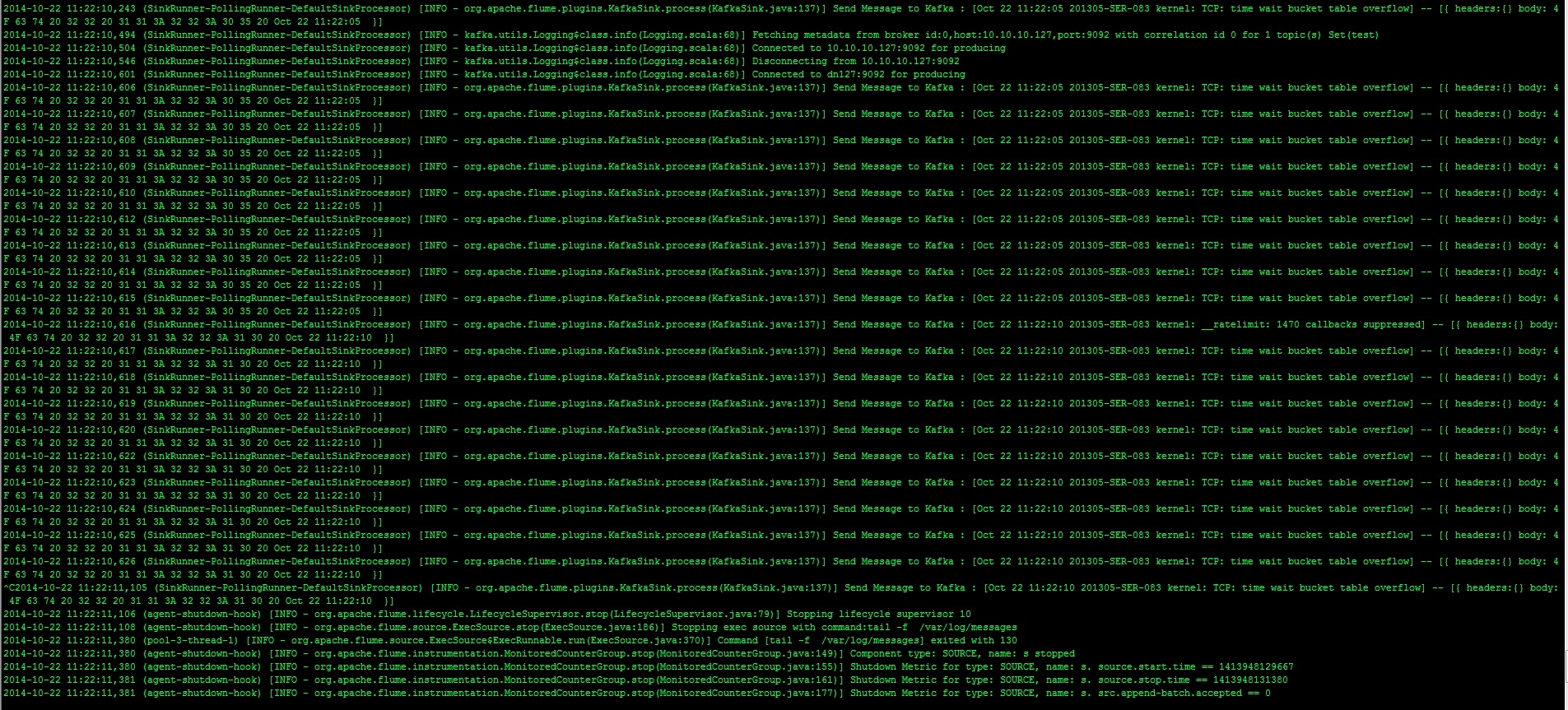
使用kafka的kafka-console-consumer.sh脚本查看是否有flume有没有往Kafka传输数据;
可以看到tail /var/log/messages已经通过flume传到kafka里,说明flume+kafka组合已经成功了。
日志最终需要保存在hdfs里
还需要自己开发插件去实现,这里不再多说。
Flume下载及文档: http://flume.apache.org/ Kafka
kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
支持通过kafka服务器和消费机集群来分区消息。
支持Hadoop并行数据加载。
kafka的目的是提供一个发布订阅解决方案,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
kafka分布式订阅架构如下图:--取自Kafka官网
配置kafka的配置文件 server.properties ,其它可根据自己的情况修改。
启动kafka,启动之前先启动zookeeper,zookeeper的配置不再叙述。
# bin/kafka-server-start.sh config/server.properties
Create a topic
# bin/kafka-topics.sh --create --zookeeper localhost:2181 ----replication-factor 1 --partitions 1 --topic test
查看topic
# bin/kafka-topics.sh --list --zookeeper localhost:2181
测试是否能正常生产消费;验证流程正确性
# bin/kafka-console-producer.sh--broker-list localhost:9092 --topic test
# bin/kafka-console-consumer.sh--zookeeper localhost:2181 --topic test --from-beginning
接下来是框架之间的整合
flume和kafka整合
1.下载flume-kafka-plus:https://github.com/beyondj2ee/flumeng-kafka-plugin
2.提取插件中的flume-conf.properties文件
修改该文件:#source section
producer.sources.s.type = exec
producer.sources.s.command = tail -f -n+1 /mnt/hgfs/vmshare/test.log
producer.sources.s.channels = c
修改所有topic的值改为test
将改后的配置文件放进flume/conf目录下
在该项目中提取以下jar包放入环境中flume的lib下:
还有package目录的flumeng-kafka-plugin.jar包一并放到flume的lib目录下。
附上flume的配置文件
############################################
# producer config
###########################################
#agent section
producer.sources = s
producer.channels = c
producer.sinks = r
#source section
producer.sources.s.type = exec
producer.sources.s.channels = c
producer.sources.s.command = tail -f /var/log/messages
#producer.sources.s.type=spooldir
#producer.sources.s.spoolDir=/home/xiaojie.li
#producer.sources.s.fileHeader=false
#producer.sources.s.type=syslogtcp
#producer.sources.s.port=5140
#producer.sources.s.host=localhost
# Each sink's type must be defined
producer.sinks.r.type = org.apache.flume.plugins.KafkaSink
producer.sinks.r.metadata.broker.list=10.10.10.127:9092
producer.sinks.r.zk.connect=10.10.10.127:2181
producer.sinks.r.partition.key=0
producer.sinks.r.partitioner.class=org.apache.flume.plugins.SinglePartition
producer.sinks.r.serializer.class=kafka.serializer.StringEncoder
producer.sinks.r.request.required.acks=0
producer.sinks.r.max.message.size=1000000
producer.sinks.r.producer.type=sync
producer.sinks.r.custom.encoding=UTF-8
producer.sinks.r.custom.topic.name=test
#Specify the channel the sink should use
producer.sinks.r.channel = c
# Each channel's type is defined.
producer.channels.c.type = memory
producer.channels.c.capacity = 1000
producer.channels.c.transactionCapacity=100
#producer.channels.c.type=file
#producer.channels.c.checkpointDir=/home/checkdir
#producer.channels.c.dataDirs=/home/datadir
验证flume和kafka组合
前面kafka已经启动,这里直接启动flume
# bin/flume-ng agent -c conf -f conf/master.properties -n producer -Dflume.root.logger=INFO,console
使用kafka的kafka-console-consumer.sh脚本查看是否有flume有没有往Kafka传输数据;
可以看到tail /var/log/messages已经通过flume传到kafka里,说明flume+kafka组合已经成功了。
日志最终需要保存在hdfs里
还需要自己开发插件去实现,这里不再多说。

相关文章推荐
- flume + kafka + sparkStreaming + HDFS 构建实时日志分析系统
- flume + kafka + sparkStreaming + HDFS 构建实时日志分析系统
- Flume+Kafka+Storm+Redis构建大数据实时处理系统 - 大数据
- Flume+Kafka+Storm+Redis构建大数据实时处理系统 - 大数据
- flume + kafka + sparkStreaming + HDFS 构建实时日志分析系统
- Flume+Kafka+Storm+Redis构建大数据实时处理系统:实时统计网站PV、UV+展示
- flume-ng+Kafka+Storm+HDFS 实时系统搭建
- 大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
- [转载] 利用flume+kafka+storm+mysql构建大数据实时系统
- 大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
- 大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
- 大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
- flume-ng+Kafka+Storm+HDFS 实时系统搭建
- 大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
- 大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
- flume-ng+Kafka+Storm+HDFS 实时系统搭建
- 大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
- flume-ng+Kafka+Storm+HDFS 实时系统搭建
- 大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
- [转]flume-ng+Kafka+Storm+HDFS 实时系统搭建