[CLPR] 定位算法探幽 - 边缘和形态学
2014-10-22 09:35
197 查看
一. 引言
如何从一副图片中找到车牌? 这是机器视觉的一个应用. 理所当然地, 思考的角度是从车牌本身的信息入手, 为了讨论方便, 下面均以长窄型蓝白车牌为例.
下图就是这样一张车牌的基本信息.
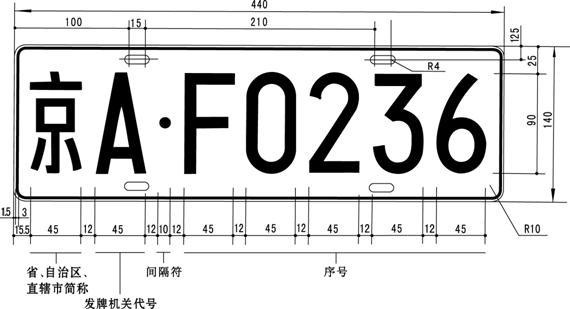
一眼看过去, 可以得到的信息有: 长宽比 - 3.14, 字符数 - 7, 第一个字符是汉字, 第二个字符是字母, 之后为5个字母/数字混合等距排列.
同时还可以大致了解到, 一个清晰的车牌应该拥有足够多的边缘信息, 换句话说, 边缘信息足够密集地聚集在一个3.14:1的矩形中.
所以今天介绍的算法, 都使用的是边缘信息, 结合上形态学来进行判别.
二. 什么是边缘?
什么是边缘? 一般我们定义灰度(256阶)图像中灰度的跳变点为边缘. 跳变点指的是相近的两个像素的灰度差异较大.
一般用于计算边缘的方法是使用算子对图像进行处理, 我们这里使用的是Sobel算子. 用于检测垂直边缘的三阶Sobel算子的形式大致如下:
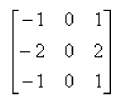
我们设算子为S, 图像中应用于算子的部分为GS, 输出为OS. 我们可以得到OS = GS * S. 也即计算了GS左侧和右侧灰度值的差, 将此差值赋予中间的三个像素. 可以看到, 这是符合我们对于边缘的定义的. 下面我们就看看使用垂直和水平两个方向的Sobel算子的计算结果:
第一张是原图, 第二张是灰度边缘.


三. 形态学 - Morphology
形态学听起来高大上, 实际上不过是利用图像的一些几何特征进行分析罢了. 在CLPR(中国车牌识别)学术领域, 形态学分析可以说占据了半壁江山.
第一章我们就分析过, 车牌可以利用的形态学信息不过寥寥: 长宽比3.14, 边缘密度高等.
其中长宽比如何确定? 边缘密度的高低又如何定量?
这些参数的获取方法和确定方法才是隐藏在形态学分析背后的关键所在.
四. 中国车牌识别常见算法汇总
我总结了21世纪以来国内外大多数期刊学报发表的关于CLPR的论文以及它们的效果, 这里先放出来, 以便下一步分析.
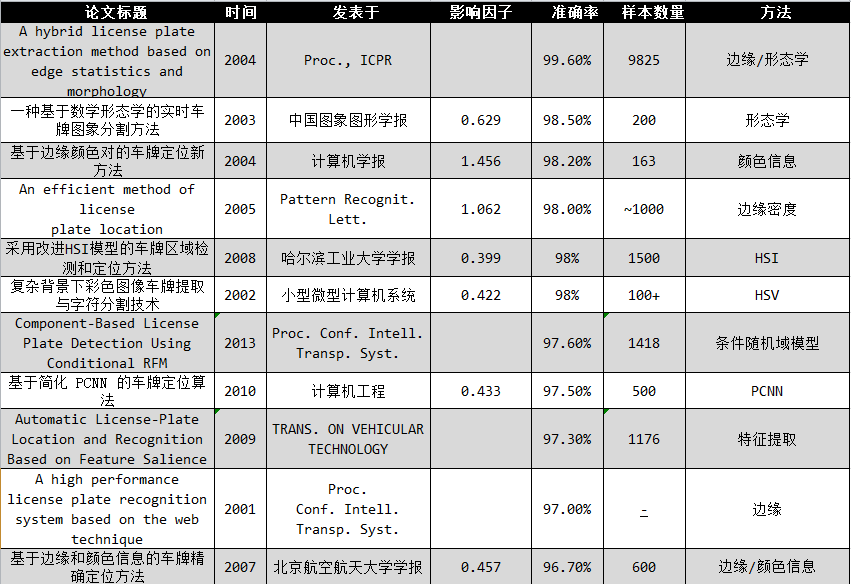
大多数已发表的结果定位的成功率都在96%以上. 基于应用情景的不同, 成功率略有波动但无须在意.
这里我们分析第一篇论文"A hybrid License Plate Extraction Method Based On Edge Statistics and Morphology". 这篇论文发表于模式识别国际会议(ICPR2004)的Proceedings上. ICPR属于模式识别领域最顶级的会议了, 所以这篇文章的可靠性还是有的. 下面我们看看这篇论文定位算法的基本思路:

我们可以看到, 这篇文章使用的是垂直边缘检测配合边缘分析和形态学提取的方法. 其中的第三步是算法的关键实现点, 通过连接近邻的边缘点构造边缘线进而连接这些线来构造矩形, 最后根据矩形的位置信息来合并这些矩形, 从而实现了一种巧妙的图像膨胀. 这种膨胀不同于一般IP中使用的无目的的膨胀, 它倾向于合并那些水平距离不远, 垂直距离相近的矩形(见下式).
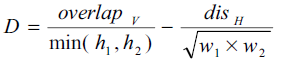
连接密度定义
overlapV是两个矩形垂直方向上的重叠部分, disH是它们的水平距离, h1, h2, w1, w2则是它们的高度和宽度.
当两矩形越处于同一水平线, overlapV越大, 则D就越大, 这两个矩形就越倾向于合并;
当两个矩形距离越远, 则disH就越大, D就越小, 这两个矩形就越不倾向于合并;
当两个矩形都比较高, D越小, 越不倾向于合并;
当两个矩形都比较宽, D越大, 越倾向于合并;
所以问题的关键就落在了D取多少的时候应该合并, 取多少的时候又不该合并呢? 这是一个阈值选取问题. 论文中选取了4阶阈值(64, 32, 16, 8)分别对图像进行处理, 得到4张处理后的图. 随后基于以下四点进行提取:
高阈值得到的矩形优先级高;
图像底部的矩形优先级高;
符合标准车牌的比例的矩形优先级高;
交叉的区域可以参考D的定义.
在获取这些图后, 作者又使用了非线性滤波器(但是没说是什么滤波器)移除了一些窄长边缘. 随后使用3x15的窗对上述图像进行卷积, 再使用大津二值法进行二值化. 二值化结束后, 对于每一个边缘点, 如果它上下的边缘点的距离低于某一阈值, 我们就连接它上下的边缘. 随后使用1x9的窗口对图像进行膨胀.
这之后就是连通分量分析和特征提取. 此处不再赘述.
五. 边缘定位算法的优劣分析
边缘定位算法的优点是准确率非常高, 但是问题明显.
受噪声影响, 误检率高;
受噪声影响, 容易粘黏导致形态学分析失效;
受光照条件影响, 性能鲁棒性不足.
对于第一点和第二点, 我们需要对边缘进行处理, 尽量滤除非车牌的边缘或弱化它们.
对于第三点, 图像的预处理就非常重要, 直方图均衡化特别是分块局部直方图均衡化是常用的手段, 也有针对特定灰度的折线分段灰度拉伸算法, 此处也不赘述.
总结起来, 使用边缘算法需要注意两点:
预处理工作
边缘滤波
如何从一副图片中找到车牌? 这是机器视觉的一个应用. 理所当然地, 思考的角度是从车牌本身的信息入手, 为了讨论方便, 下面均以长窄型蓝白车牌为例.
下图就是这样一张车牌的基本信息.
一眼看过去, 可以得到的信息有: 长宽比 - 3.14, 字符数 - 7, 第一个字符是汉字, 第二个字符是字母, 之后为5个字母/数字混合等距排列.
同时还可以大致了解到, 一个清晰的车牌应该拥有足够多的边缘信息, 换句话说, 边缘信息足够密集地聚集在一个3.14:1的矩形中.
所以今天介绍的算法, 都使用的是边缘信息, 结合上形态学来进行判别.
二. 什么是边缘?
什么是边缘? 一般我们定义灰度(256阶)图像中灰度的跳变点为边缘. 跳变点指的是相近的两个像素的灰度差异较大.
一般用于计算边缘的方法是使用算子对图像进行处理, 我们这里使用的是Sobel算子. 用于检测垂直边缘的三阶Sobel算子的形式大致如下:
我们设算子为S, 图像中应用于算子的部分为GS, 输出为OS. 我们可以得到OS = GS * S. 也即计算了GS左侧和右侧灰度值的差, 将此差值赋予中间的三个像素. 可以看到, 这是符合我们对于边缘的定义的. 下面我们就看看使用垂直和水平两个方向的Sobel算子的计算结果:
第一张是原图, 第二张是灰度边缘.
三. 形态学 - Morphology
形态学听起来高大上, 实际上不过是利用图像的一些几何特征进行分析罢了. 在CLPR(中国车牌识别)学术领域, 形态学分析可以说占据了半壁江山.
第一章我们就分析过, 车牌可以利用的形态学信息不过寥寥: 长宽比3.14, 边缘密度高等.
其中长宽比如何确定? 边缘密度的高低又如何定量?
这些参数的获取方法和确定方法才是隐藏在形态学分析背后的关键所在.
四. 中国车牌识别常见算法汇总
我总结了21世纪以来国内外大多数期刊学报发表的关于CLPR的论文以及它们的效果, 这里先放出来, 以便下一步分析.
大多数已发表的结果定位的成功率都在96%以上. 基于应用情景的不同, 成功率略有波动但无须在意.
这里我们分析第一篇论文"A hybrid License Plate Extraction Method Based On Edge Statistics and Morphology". 这篇论文发表于模式识别国际会议(ICPR2004)的Proceedings上. ICPR属于模式识别领域最顶级的会议了, 所以这篇文章的可靠性还是有的. 下面我们看看这篇论文定位算法的基本思路:
我们可以看到, 这篇文章使用的是垂直边缘检测配合边缘分析和形态学提取的方法. 其中的第三步是算法的关键实现点, 通过连接近邻的边缘点构造边缘线进而连接这些线来构造矩形, 最后根据矩形的位置信息来合并这些矩形, 从而实现了一种巧妙的图像膨胀. 这种膨胀不同于一般IP中使用的无目的的膨胀, 它倾向于合并那些水平距离不远, 垂直距离相近的矩形(见下式).
连接密度定义
overlapV是两个矩形垂直方向上的重叠部分, disH是它们的水平距离, h1, h2, w1, w2则是它们的高度和宽度.
当两矩形越处于同一水平线, overlapV越大, 则D就越大, 这两个矩形就越倾向于合并;
当两个矩形距离越远, 则disH就越大, D就越小, 这两个矩形就越不倾向于合并;
当两个矩形都比较高, D越小, 越不倾向于合并;
当两个矩形都比较宽, D越大, 越倾向于合并;
所以问题的关键就落在了D取多少的时候应该合并, 取多少的时候又不该合并呢? 这是一个阈值选取问题. 论文中选取了4阶阈值(64, 32, 16, 8)分别对图像进行处理, 得到4张处理后的图. 随后基于以下四点进行提取:
高阈值得到的矩形优先级高;
图像底部的矩形优先级高;
符合标准车牌的比例的矩形优先级高;
交叉的区域可以参考D的定义.
在获取这些图后, 作者又使用了非线性滤波器(但是没说是什么滤波器)移除了一些窄长边缘. 随后使用3x15的窗对上述图像进行卷积, 再使用大津二值法进行二值化. 二值化结束后, 对于每一个边缘点, 如果它上下的边缘点的距离低于某一阈值, 我们就连接它上下的边缘. 随后使用1x9的窗口对图像进行膨胀.
这之后就是连通分量分析和特征提取. 此处不再赘述.
五. 边缘定位算法的优劣分析
边缘定位算法的优点是准确率非常高, 但是问题明显.
受噪声影响, 误检率高;
受噪声影响, 容易粘黏导致形态学分析失效;
受光照条件影响, 性能鲁棒性不足.
对于第一点和第二点, 我们需要对边缘进行处理, 尽量滤除非车牌的边缘或弱化它们.
对于第三点, 图像的预处理就非常重要, 直方图均衡化特别是分块局部直方图均衡化是常用的手段, 也有针对特定灰度的折线分段灰度拉伸算法, 此处也不赘述.
总结起来, 使用边缘算法需要注意两点:
预处理工作
边缘滤波

相关文章推荐
- 亚像素级点定位及边缘定位算法
- 颜色定位和形态学定位改进后的mtcnn车牌定位算法
- 边缘文本检测:快速的和健壮的场景文本定位算法的研究
- 一种边缘检测与扫描线相结合的车牌定位算法
- 一些基本形态学算法------边缘提取算法
- 算法_GPS定位基本常识
- 图像处理之积分图应用二(快速边缘保留滤波算法)
- 第五章 - 图像形态学 - 漫水填充算法(cvFloodFill)
- Sobel边缘提取算法(DSP)
- 图像形态学 - 漫水填充算法(cvFloodFill)
- OpenCV下车牌定位算法实现代码
- Canny边缘检测算法原理及其VC实现
- 基于肤色和眼睛定位的人脸检测算法——MATLAB实现【转】
- 对图像边缘进行随机均匀采样的算法实现( 转载)
- 双指数边缘平滑滤波器用于磨皮算法的尝试。
- 一些基本形态学算法------区域填充算法
- 基于临界灰度值和亚像素的“边缘寻找”算法
- Retinex、log对数变换、直方图均衡化区别,边缘增强Retinex算法与拉普拉斯算法联系、均衡化与亮度调节算法、大津阈值计算
- DBoW2 回环检测/重定位 算法解析
- OpenCV下车牌定位算法实现代码(一)